Mixture of Experts Made Intrinsically Interpretable
作者: Xingyi Yang, Constantin Venhoff, Ashkan Khakzar, Christian Schroeder de Witt, Puneet K. Dokania, Adel Bibi, Philip Torr
分类: cs.LG, cs.CL
发布日期: 2025-03-05
💡 一句话要点
提出MoE-X,一种本质上可解释的混合专家语言模型,提升模型可解释性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 可解释性 稀疏激活 语言模型 路由机制
📋 核心要点
- 大型语言模型神经元的多义性降低了模型的可解释性,现有方法依赖事后解释,存在局限性。
- MoE-X将MoE层转化为稀疏MLP,通过扩展隐藏层大小并保持稀疏性,实现本质上的可解释性。
- 实验表明,MoE-X在国际象棋和自然语言任务上表现与密集模型相当,且可解释性优于GPT-2和SAE。
📝 摘要(中文)
大型语言模型中的神经元通常表现出多义性,同时编码多个不相关的概念,从而模糊了可解释性。本文提出MoE-X,一种混合专家(MoE)语言模型,旨在实现本质上的可解释性,而非依赖事后解释方法。该方法基于语言模型中具有稀疏激活的更宽网络更有可能捕获可解释因素的观察。然而,直接训练这种大型稀疏网络在计算上是禁止的。MoE架构通过仅激活给定输入的专家子集,提供了一种可扩展的替代方案,这与可解释性目标天然一致。在MoE-X中,通过将MoE层重写为等效的稀疏大型MLP来建立这种联系。这种方法能够有效扩展隐藏层大小,同时保持稀疏性。为了进一步提高可解释性,在每个专家内部强制执行稀疏激活,并重新设计路由机制,以优先考虑具有最高激活稀疏性的专家。这些设计确保只有最显著的特征被路由并由专家处理。在国际象棋和自然语言任务上评估了MoE-X,结果表明它实现了与密集模型相当的性能,同时显著提高了可解释性。MoE-X实现了优于GPT-2的困惑度,其可解释性甚至超过了基于稀疏自编码器(SAE)的方法。
🔬 方法详解
问题定义:现有大型语言模型存在神经元多义性问题,即一个神经元同时编码多个不相关的概念,导致模型难以解释。传统的可解释性方法通常是事后解释,即在模型训练完成后再进行分析,这种方法可能无法真正揭示模型的内部机制,且效果有限。直接训练大型稀疏网络计算成本过高,难以实现。
核心思路:论文的核心思路是利用混合专家模型(MoE)的稀疏激活特性,将其设计成本质上可解释的模型。MoE模型只激活一部分专家来处理输入,这天然符合可解释性的目标。通过将MoE层重写为等效的稀疏大型MLP,可以在扩展模型容量的同时保持稀疏性,从而提高可解释性。同时,通过优化路由机制和强制专家内部的稀疏激活,进一步提升模型的可解释性。
技术框架:MoE-X模型的整体框架基于标准的MoE架构,主要包含以下几个模块:输入层、MoE层、输出层。MoE层是核心模块,它由多个专家网络和一个路由网络组成。路由网络根据输入选择激活哪些专家。每个专家网络都是一个小型的前馈神经网络。MoE-X的关键在于对MoE层的重新设计,将其等价于一个大型的稀疏MLP。此外,还对路由机制进行了改进,使其优先选择激活稀疏性最高的专家。
关键创新:MoE-X最重要的技术创新点在于将MoE层等价地表示为一个大型稀疏MLP。这种表示方法使得可以高效地扩展模型的容量,同时保持稀疏性,从而提高可解释性。此外,对路由机制的改进也是一个重要的创新点,它使得模型能够选择更具代表性的专家,从而进一步提高可解释性。与现有方法的本质区别在于,MoE-X不是通过事后解释来提高可解释性,而是通过模型结构的设计来实现本质上的可解释性。
关键设计:MoE-X的关键设计包括:1) 将MoE层重写为稀疏MLP的具体实现方式,包括如何计算等价的权重矩阵和偏置向量。2) 路由机制的设计,包括如何计算专家的激活稀疏性,以及如何根据激活稀疏性来选择专家。3) 专家内部的稀疏激活的实现方式,例如使用L1正则化或dropout等方法。4) 损失函数的设计,除了标准的交叉熵损失外,可能还包括一些正则化项,例如稀疏性正则化项。
🖼️ 关键图片

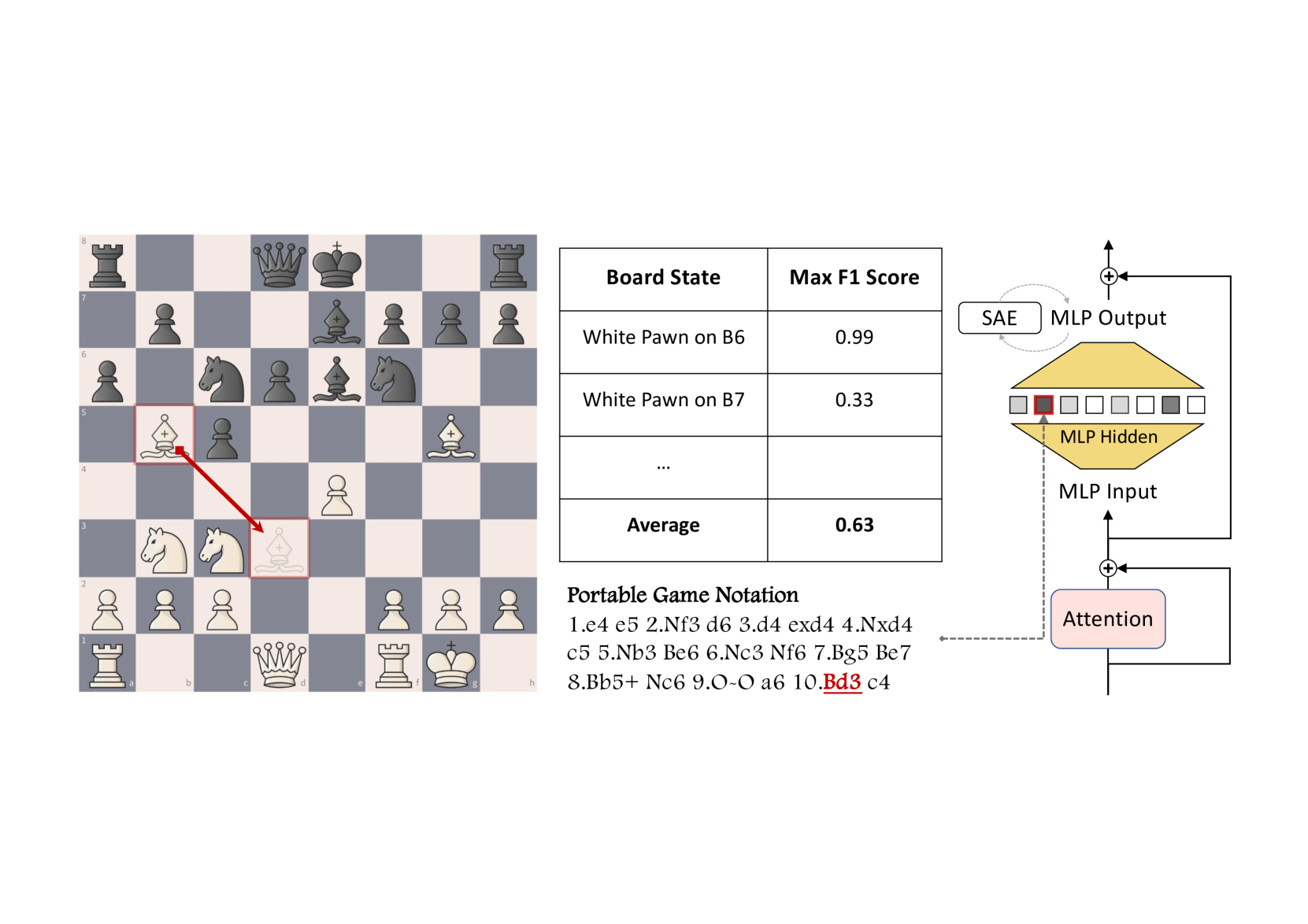
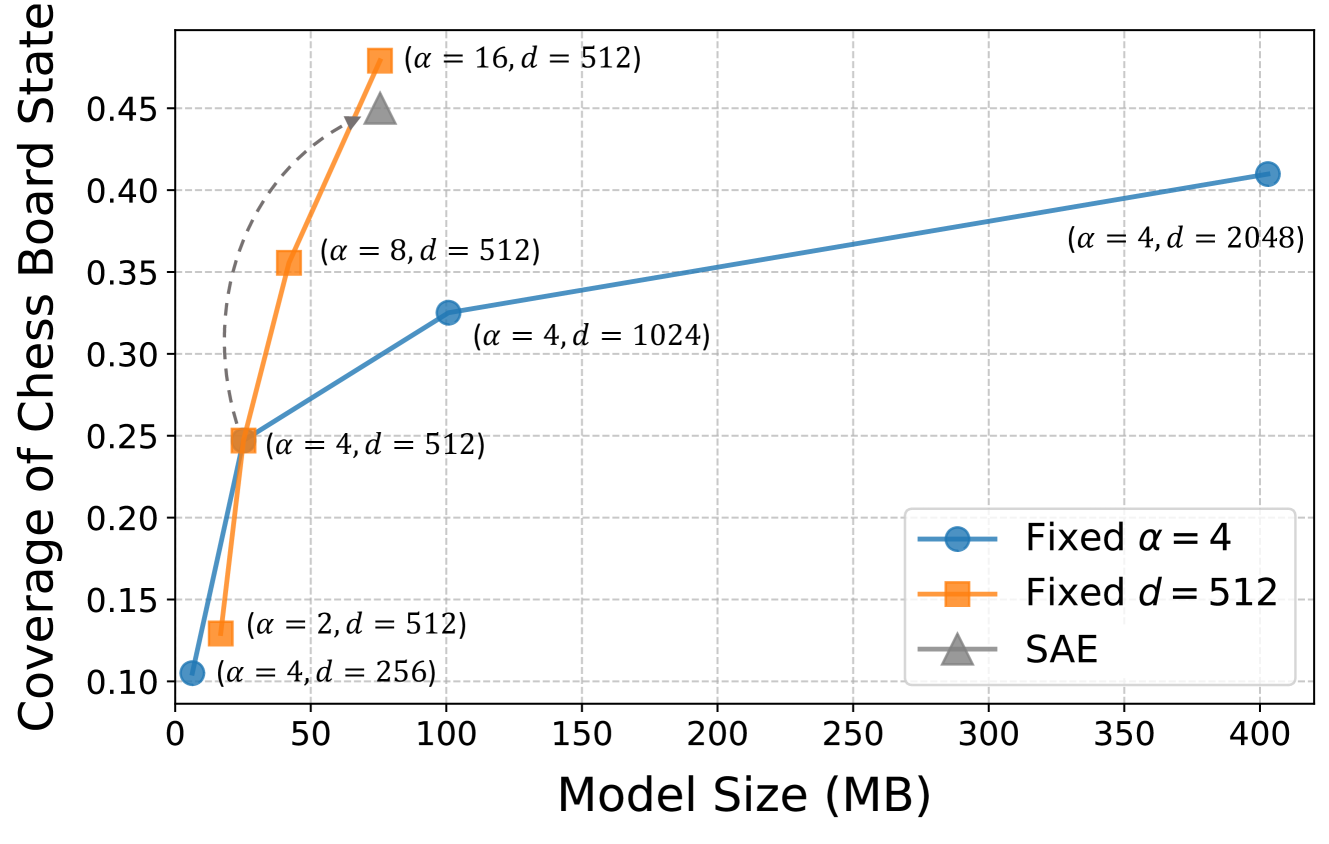
📊 实验亮点
MoE-X在国际象棋和自然语言任务上进行了评估,结果表明它实现了与密集模型相当的性能,同时显著提高了可解释性。在自然语言任务上,MoE-X实现了优于GPT-2的困惑度,并且其可解释性甚至超过了基于稀疏自编码器(SAE)的方法。这些结果表明,MoE-X是一种有效的可解释性语言模型。
🎯 应用场景
MoE-X模型在需要高可解释性的自然语言处理任务中具有广泛的应用前景,例如金融风控、医疗诊断等领域。通过提高模型的可解释性,可以帮助人们更好地理解模型的决策过程,从而提高模型的可靠性和可信度。此外,MoE-X模型还可以应用于知识发现和知识抽取等任务,帮助人们从大量文本数据中提取有用的信息。
📄 摘要(原文)
Neurons in large language models often exhibit \emph{polysemanticity}, simultaneously encoding multiple unrelated concepts and obscuring interpretability. Instead of relying on post-hoc methods, we present \textbf{MoE-X}, a Mixture-of-Experts (MoE) language model designed to be \emph{intrinsically} interpretable. Our approach is motivated by the observation that, in language models, wider networks with sparse activations are more likely to capture interpretable factors. However, directly training such large sparse networks is computationally prohibitive. MoE architectures offer a scalable alternative by activating only a subset of experts for any given input, inherently aligning with interpretability objectives. In MoE-X, we establish this connection by rewriting the MoE layer as an equivalent sparse, large MLP. This approach enables efficient scaling of the hidden size while maintaining sparsity. To further enhance interpretability, we enforce sparse activation within each expert and redesign the routing mechanism to prioritize experts with the highest activation sparsity. These designs ensure that only the most salient features are routed and processed by the experts. We evaluate MoE-X on chess and natural language tasks, showing that it achieves performance comparable to dense models while significantly improving interpretability. MoE-X achieves a perplexity better than GPT-2, with interpretability surpassing even sparse autoencoder (SAE)-based approaches.