A Little Depth Goes a Long Way: The Expressive Power of Log-Depth Transformers
作者: William Merrill, Ashish Sabharwal
分类: cs.LG, cs.CC
发布日期: 2025-03-05 (更新: 2025-11-05)
备注: NeurIPS 2025
💡 一句话要点
提出对数深度Transformer,解决传统Transformer在长序列推理上的表达能力不足问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 深度学习 序列推理 表达能力 正则语言 图连通性 对数深度 模型复杂度
📋 核心要点
- 传统Transformer在处理长序列推理问题时,由于深度固定,表达能力受到限制,无法有效捕捉序列中的长期依赖关系。
- 论文提出对数深度Transformer,其深度随输入长度对数增长,理论证明了其在正则语言识别和图连通性问题上的表达能力。
- 实验结果表明,理论推导的深度要求与实际训练Transformer的深度需求高度吻合,验证了该理论的有效性,并为深度选择提供了指导。
📝 摘要(中文)
最近的理论结果表明,Transformer无法表达长输入上的序列推理问题,直观原因是其计算深度有限。然而,先前的工作将深度视为常数,使得有限深度在多大程度上足以解决短输入上的问题,或者增加Transformer的深度如何影响其表达能力尚不清楚。本文通过分析深度可以随上下文长度n最小程度增长的Transformer来解决这些问题。我们证明,即使是深度为Θ(log n)的高度均匀的Transformer也可以表达两个重要的问题:识别正则语言(捕捉状态跟踪能力,已知只能由非常规的、非均匀的Transformer模型表达)和图连通性(多步推理的基础)。值得注意的是,在标准复杂性假设下,固定深度的Transformer无法表达这两个问题,这证明了增加深度的表达能力优势。此外,我们的理论定量地预测了深度必须如何随输入长度增长才能表达这些问题,表明深度缩放比宽度缩放或思维链步骤更有效。经验上,我们旨在弥合表达能力与可学习性差距的详细实验表明,我们用于正则语言识别的理论深度要求与成功训练Transformer的实际深度要求非常吻合。因此,我们的结果阐明了深度如何影响Transformer的推理能力,并为有效选择序列推理的深度提供了实践指导。
🔬 方法详解
问题定义:论文旨在解决传统Transformer在长序列推理任务中表达能力不足的问题。现有Transformer的深度通常是固定的,这限制了它们捕捉长距离依赖关系的能力,使其难以处理需要多步推理的问题。例如,识别正则语言和判断图的连通性等问题,固定深度的Transformer在标准复杂性假设下无法有效解决。
核心思路:论文的核心思路是增加Transformer的深度,使其能够随着输入序列的长度对数增长。具体来说,论文证明了深度为Θ(log n)的Transformer足以表达正则语言和图连通性。这种对数深度的设计在表达能力和计算复杂度之间取得了较好的平衡,既能有效处理长序列,又避免了过度增加计算成本。
技术框架:论文主要通过理论分析来证明对数深度Transformer的表达能力。首先,论文形式化地定义了对数深度Transformer的模型结构,并给出了其计算过程。然后,论文分别针对正则语言识别和图连通性问题,设计了特定的Transformer结构,并证明了这些结构能够在对数深度下解决相应的问题。证明过程主要依赖于将这些问题分解为一系列可以在对数深度内完成的子任务。
关键创新:论文最重要的创新点在于证明了对数深度Transformer在表达能力上的优势。与以往认为Transformer深度是常数的观点不同,论文表明深度可以随着输入长度增长,并且对数级别的增长就足以显著提升Transformer的表达能力。此外,论文还定量地分析了深度增长与表达能力之间的关系,为实际应用中选择合适的Transformer深度提供了理论依据。
关键设计:论文的关键设计在于如何将正则语言识别和图连通性问题映射到Transformer的计算过程中。对于正则语言识别,论文设计了一种能够模拟有限状态自动机的Transformer结构,其中每个Transformer层对应于自动机的一个状态转移。对于图连通性问题,论文设计了一种能够迭代地更新节点之间连通性信息的Transformer结构,其中每个Transformer层对应于一次连通性信息的传播。
🖼️ 关键图片

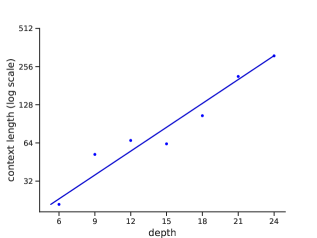
📊 实验亮点
论文通过实验验证了理论分析的有效性。针对正则语言识别任务,实验结果表明,理论推导的深度要求与实际训练Transformer的深度需求高度吻合。具体来说,当Transformer的深度接近log n时,模型能够成功学习并识别正则语言,而当深度不足时,模型则无法收敛。这表明,论文提出的对数深度Transformer具有实际意义,并为深度选择提供了有价值的参考。
🎯 应用场景
该研究成果可应用于需要长序列推理的各种领域,例如自然语言处理中的阅读理解、机器翻译,以及生物信息学中的基因序列分析等。通过合理选择Transformer的深度,可以提高模型在这些任务上的性能,并降低计算成本。此外,该研究也为设计更高效的Transformer架构提供了理论指导。
📄 摘要(原文)
Recent theoretical results show transformers cannot express sequential reasoning problems over long inputs, intuitively because their computational depth is bounded. However, prior work treats the depth as a constant, leaving it unclear to what degree bounded depth may suffice for solving problems over short inputs, or how increasing the transformer's depth affects its expressive power. We address these questions by analyzing transformers whose depth can grow minimally with context length $n$. We show even highly uniform transformers with depth $Θ(\log n)$ can express two important problems: recognizing regular languages, which captures state tracking abilities and was known to be expressible only by an unconventional, non-uniform model of transformers, and graph connectivity, which underlies multi-step reasoning. Notably, both of these problems cannot be expressed by fixed-depth transformers under standard complexity conjectures, demonstrating the expressivity benefit of growing depth. Moreover, our theory quantitatively predicts how depth must grow with input length to express these problems, showing that depth scaling is more efficient than scaling width or chain-of-thought steps. Empirically, our detailed experiments designed to bridge the expressivity vs. learnability gap reveal that our theoretical depth requirements for regular language recognition closely match the practical depth requirements for successfully training transformers. Thus, our results clarify how depth affects a transformer's reasoning capabilities, and provide practical guidance for effective depth selection for sequential reasoning.