Towards Understanding Distilled Reasoning Models: A Representational Approach
作者: David D. Baek, Max Tegmark
分类: cs.LG
发布日期: 2025-03-05 (更新: 2025-03-25)
备注: 13 pages, 9 figures
期刊: ICLR 2025 Workshop on Building Trust in Language Models and Applications
💡 一句话要点
通过表征分析理解蒸馏推理模型:揭示模型蒸馏对LLM推理能力的影响
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型蒸馏 大型语言模型 表征分析 推理能力 互译器
📋 核心要点
- 大型语言模型的推理能力受模型蒸馏影响,但具体机制尚不明确,缺乏对蒸馏后模型内部表征变化的深入理解。
- 论文提出一种基于表征分析的方法,通过训练互译器来研究蒸馏模型中推理特征的演变,从而理解蒸馏过程的影响。
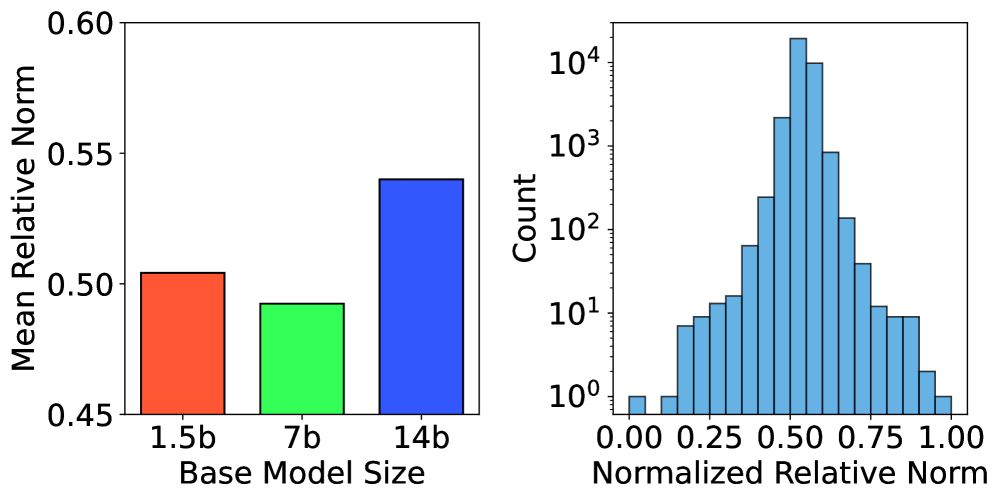
- 实验结果表明,蒸馏模型包含独特的推理特征方向,且更大的蒸馏模型可能发展出更结构化的表征,与蒸馏性能提升相关。
📝 摘要(中文)
本文研究了模型蒸馏如何影响大型语言模型(LLM)中推理特征的发展。为了探索这一点,我们在Qwen系列模型及其微调变体上训练了一个互译器(crosscoder)。结果表明,该互译器学习了对应于各种推理类型的特征,包括自我反思和计算验证。此外,我们观察到蒸馏模型包含独特的推理特征方向,这些方向可用于引导模型进入过度思考或敏锐思考模式。我们对四个特定的推理类别进行了分析:(a)自我反思,(b)演绎推理,(c)替代推理,和(d)对比推理。最后,我们检查了蒸馏过程导致的特征几何形状的变化,并发现迹象表明,较大的蒸馏模型可能会开发出更结构化的表示,这与增强的蒸馏性能相关。通过深入了解蒸馏如何修改模型,我们的研究有助于提高AI系统的透明度和可靠性。
🔬 方法详解
问题定义:论文旨在理解模型蒸馏对大型语言模型(LLM)推理能力的影响。现有方法缺乏对蒸馏后模型内部表征变化的深入理解,难以解释蒸馏如何影响模型的推理能力。
核心思路:论文的核心思路是通过表征分析,研究蒸馏模型中推理特征的演变。具体来说,通过训练一个互译器(crosscoder)来学习不同模型之间的特征映射,从而揭示蒸馏过程对推理特征的影响。这样可以更直观地理解蒸馏如何改变模型的内部表征,进而影响其推理能力。
技术框架:整体框架包括以下几个主要步骤:1) 选择Qwen系列模型及其微调变体作为研究对象;2) 训练一个互译器(crosscoder),用于学习不同模型之间的特征映射;3) 分析互译器学习到的特征,识别对应于不同推理类型的特征方向,例如自我反思、演绎推理等;4) 研究蒸馏过程对特征几何形状的影响,例如特征方向的变化、特征表示的结构化程度等;5) 将特征几何形状的变化与蒸馏性能联系起来,分析其对模型推理能力的影响。
关键创新:论文的关键创新在于使用互译器来研究蒸馏模型中推理特征的演变。与传统的黑盒方法不同,该方法能够更直观地揭示蒸馏过程对模型内部表征的影响,从而更深入地理解蒸馏如何影响模型的推理能力。此外,论文还发现蒸馏模型包含独特的推理特征方向,可以用于引导模型进入不同的思考模式。
关键设计:互译器的具体结构未知,但其目标是学习不同模型之间的特征映射。论文分析了互译器学习到的特征,识别对应于不同推理类型的特征方向。此外,论文还研究了蒸馏过程对特征几何形状的影响,例如特征方向的变化、特征表示的结构化程度等。具体的参数设置、损失函数、网络结构等技术细节在摘要中未提及,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,互译器能够学习到对应于各种推理类型的特征,包括自我反思和计算验证。此外,论文还观察到蒸馏模型包含独特的推理特征方向,这些方向可用于引导模型进入过度思考或敏锐思考模式。更大的蒸馏模型可能发展出更结构化的表征,这与增强的蒸馏性能相关。
🎯 应用场景
该研究成果可应用于提升AI系统的透明度和可靠性,例如,通过理解蒸馏过程对模型推理能力的影响,可以更好地设计蒸馏策略,提高蒸馏模型的性能。此外,该方法还可以用于分析其他类型的模型压缩技术,例如剪枝和量化,从而更好地理解这些技术对模型内部表征的影响。
📄 摘要(原文)
In this paper, we investigate how model distillation impacts the development of reasoning features in large language models (LLMs). To explore this, we train a crosscoder on Qwen-series models and their fine-tuned variants. Our results suggest that the crosscoder learns features corresponding to various types of reasoning, including self-reflection and computation verification. Moreover, we observe that distilled models contain unique reasoning feature directions, which could be used to steer the model into over-thinking or incisive-thinking mode. In particular, we perform analysis on four specific reasoning categories: (a) self-reflection, (b) deductive reasoning, (c) alternative reasoning, and (d) contrastive reasoning. Finally, we examine the changes in feature geometry resulting from the distillation process and find indications that larger distilled models may develop more structured representations, which correlate with enhanced distillation performance. By providing insights into how distillation modifies the model, our study contributes to enhancing the transparency and reliability of AI systems.