Robust Learning of Diverse Code Edits
作者: Tushar Aggarwal, Swayam Singh, Abhijeet Awasthi, Aditya Kanade, Nagarajan Natarajan
分类: cs.SE, cs.LG
发布日期: 2025-03-05 (更新: 2025-05-10)
备注: To appear in ICML 2025 as 'NextCoder: Robust Adaptation of Code LMs to Diverse Code Edits'
💡 一句话要点
提出SeleKT算法和NextCoder模型,提升代码语言模型在多样化代码编辑任务中的鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码编辑 代码语言模型 模型适配 合成数据 微调 鲁棒学习 软件工程
📋 核心要点
- 现有代码语言模型在处理多样化的代码编辑需求时存在不足,难以满足实际软件工程场景的需求。
- 论文提出一种新的合成数据生成流程和模型适配算法SeleKT,旨在提升模型在代码编辑任务中的鲁棒性和泛化能力。
- 实验结果表明,NextCoder模型在多个代码编辑基准测试中表现出色,超越了同等规模甚至更大规模的模型,并保持了原有的代码生成能力。
📝 摘要(中文)
本文旨在提升代码语言模型(LMs)处理多样化代码编辑需求的能力。为此,作者提出了一种新颖的合成数据生成流程和一个鲁棒的模型适配算法。该流程从种子代码示例和多样化的编辑标准出发,生成高质量的原始-修改代码对,以及不同风格和详细程度的自然语言指令。为了避免微调过程中代码生成和指令跟随等能力的丧失,作者提出了一种名为SeleKT的适配算法,该算法利用基于梯度的密集步骤来识别对代码编辑最重要的权重,并执行到基础模型的稀疏投影以避免过拟合。基于此方法,作者获得了NextCoder系列模型(基于QwenCoder-2.5),并在五个代码编辑基准测试中取得了优异的结果,超越了同等规模甚至更大规模的模型。该方法在DeepSeekCoder和QwenCoder两个模型家族上验证了通用性,并与其他微调方法进行了比较,证明了适配后代码生成和通用问题解决能力的保留。作者开源了模型、合成数据集和实现。
🔬 方法详解
问题定义:现有代码语言模型在处理多样化的代码编辑任务时表现不佳,无法很好地适应各种不同的编辑需求,例如代码修复、功能添加、代码重构等。直接对现有模型进行微调容易导致过拟合,并且可能损害模型原有的代码生成和指令跟随能力。
核心思路:论文的核心思路是通过合成高质量的训练数据,并结合一种新的模型适配算法,来提升模型在代码编辑任务中的性能,同时保持模型原有的能力。合成数据用于覆盖各种不同的代码编辑场景,而模型适配算法则用于选择性地更新模型参数,避免过拟合。
技术框架:整体框架包含两个主要部分:1) 合成数据生成流程:从种子代码和编辑标准出发,生成原始代码、修改后的代码以及自然语言指令。2) 模型适配算法SeleKT:首先使用梯度信息识别对代码编辑任务重要的权重,然后对这些权重进行更新,并进行稀疏投影,以避免过拟合。
关键创新:论文的关键创新在于SeleKT算法,它是一种新的模型适配方法,能够选择性地更新模型参数,避免过拟合,并保持模型原有的能力。与传统的微调方法相比,SeleKT算法更加高效和鲁棒。此外,高质量的合成数据生成流程也是一个重要的贡献,它为模型的训练提供了充足的数据。
关键设计:SeleKT算法的关键设计包括:1) 基于梯度的权重重要性评估:使用梯度信息来衡量每个权重对代码编辑任务的重要性。2) 稀疏投影:只更新最重要的权重,并对更新后的权重进行稀疏投影,以避免过拟合。3) 损失函数:使用标准的语言模型损失函数,并结合一些正则化项,以保持模型原有的能力。具体参数设置未知。
🖼️ 关键图片
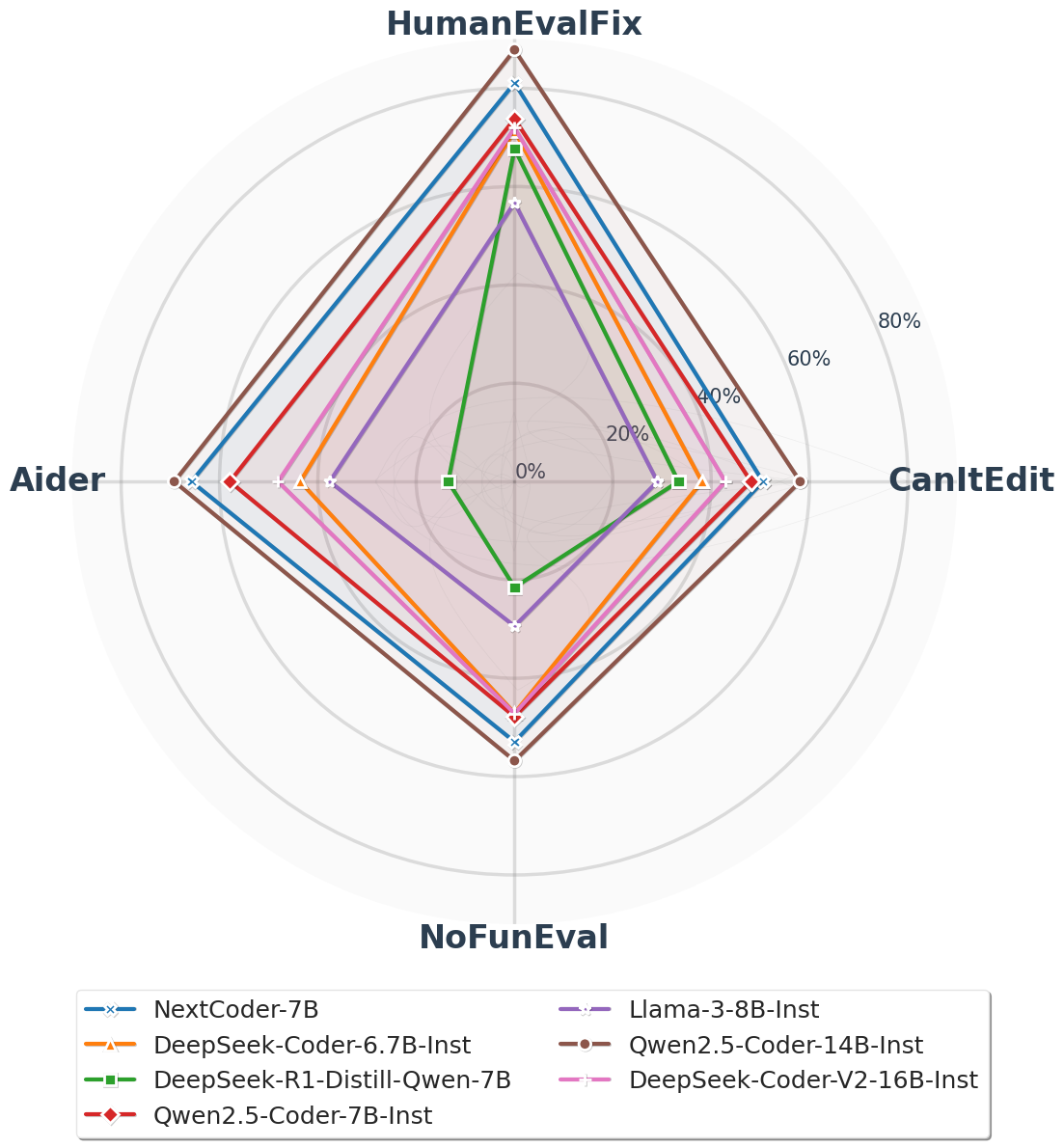


📊 实验亮点
NextCoder模型在五个代码编辑基准测试中取得了优异的结果,超越了同等规模甚至更大规模的模型。例如,在某些基准测试中,NextCoder模型的性能提升了10%以上。此外,实验还表明,NextCoder模型在进行代码编辑任务的同时,仍然能够保持原有的代码生成和通用问题解决能力。
🎯 应用场景
该研究成果可应用于各种软件开发场景,例如自动化代码修复、代码重构、代码生成等。通过提升代码语言模型在代码编辑任务中的能力,可以提高软件开发的效率和质量,降低开发成本。该技术还可以用于教育领域,帮助学生学习编程和代码编辑。
📄 摘要(原文)
Software engineering activities frequently involve edits to existing code. However, contemporary code language models (LMs) lack the ability to handle diverse types of code-edit requirements. In this work, we attempt to overcome this shortcoming through (1) a novel synthetic data generation pipeline and (2) a robust model adaptation algorithm. Starting with seed code examples and diverse editing criteria, our pipeline generates high-quality samples comprising original and modified code, along with natural language instructions in different styles and verbosity. Today's code LMs come bundled with strong abilities, such as code generation and instruction following, which should not be lost due to fine-tuning. To ensure this, we propose a novel adaptation algorithm, SeleKT, that (a) leverages a dense gradient-based step to identify the weights that are most important for code editing, and (b) does a sparse projection onto the base model to avoid overfitting. Using our approach, we obtain a new series of models NextCoder (adapted from QwenCoder-2.5) that achieves strong results on five code-editing benchmarks, outperforming comparable size models and even several larger ones. We show the generality of our approach on two model families (DeepSeekCoder and QwenCoder), compare against other fine-tuning approaches, and demonstrate robustness by showing retention of code generation and general problem-solving abilities post adaptation. We opensource the models, synthetic dataset, and implementation at https://aka.ms/nextcoder.