Probabilistic Insights for Efficient Exploration Strategies in Reinforcement Learning
作者: Ernesto Garcia, Paola Bermolen, Matthieu Jonckheere, Seva Shneer
分类: math.PR, cs.LG
发布日期: 2025-03-05 (更新: 2026-01-15)
💡 一句话要点
针对稀疏奖励强化学习,提出基于概率洞察的高效探索策略
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 探索策略 稀疏奖励 并行模拟 重启机制
📋 核心要点
- 现有强化学习方法在稀疏奖励环境中探索效率低,难以发现罕见但重要的状态。
- 论文提出利用并行模拟和重启机制,优化探索过程,提升发现罕见状态的概率。
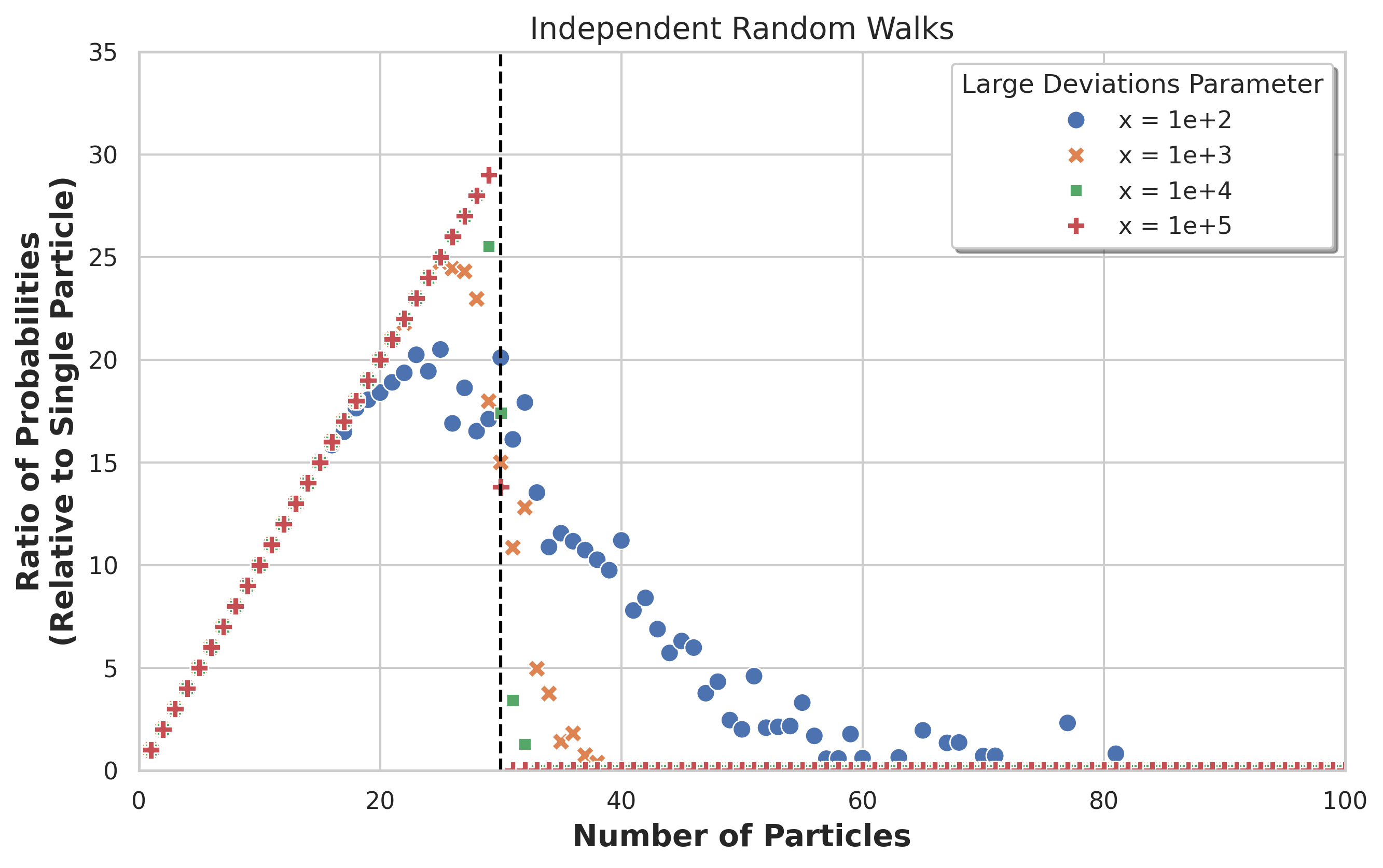
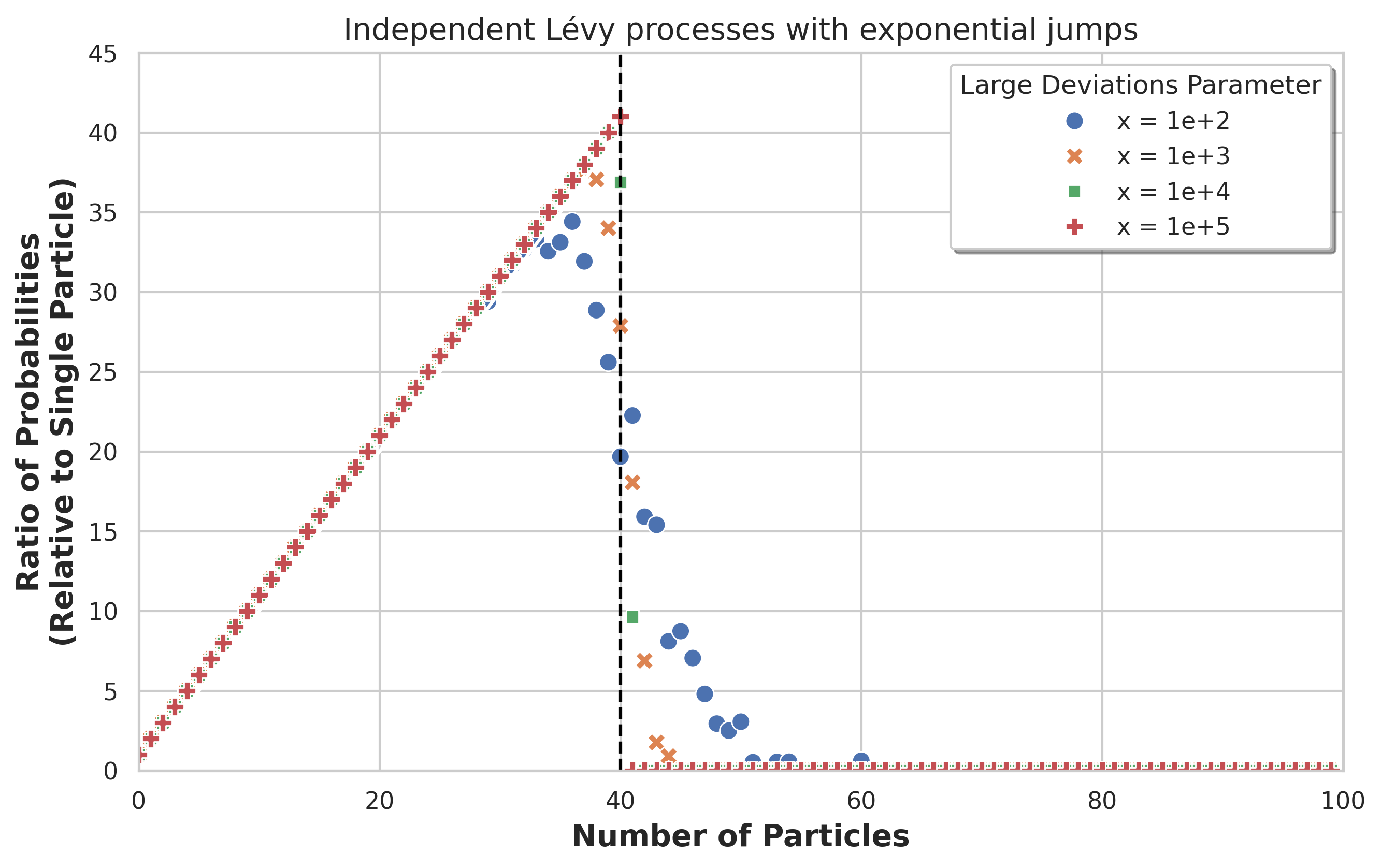
- 通过理论分析和简化模型,揭示了并行模拟数量与探索效率之间的关系,并找到了最优值。
📝 摘要(中文)
本文研究了具有未知随机动态和稀疏奖励环境中的高效探索策略。具体而言,我们首先分析了并行模拟对在有限时间预算内达到罕见状态概率的影响。利用基于随机游走和Lévy过程的简化模型,我们提供了分析结果,表明达到概率存在一个相变,该相变是并行模拟数量的函数。我们确定了平衡探索多样性和时间分配的最佳并行模拟数量。此外,我们分析了一种重启机制,该机制通过将努力重新导向更有希望的状态空间区域,从而指数级地提高成功概率。我们的发现为强化学习中一些探索方案的定性和定量理论做出了贡献,为开发以罕见事件为特征的环境的更有效策略提供了见解。
🔬 方法详解
问题定义:论文旨在解决强化学习中,智能体在具有未知随机动态和稀疏奖励的环境下进行高效探索的问题。现有方法在面对稀疏奖励时,探索效率低下,难以发现那些罕见但至关重要的状态,导致学习过程缓慢甚至失败。
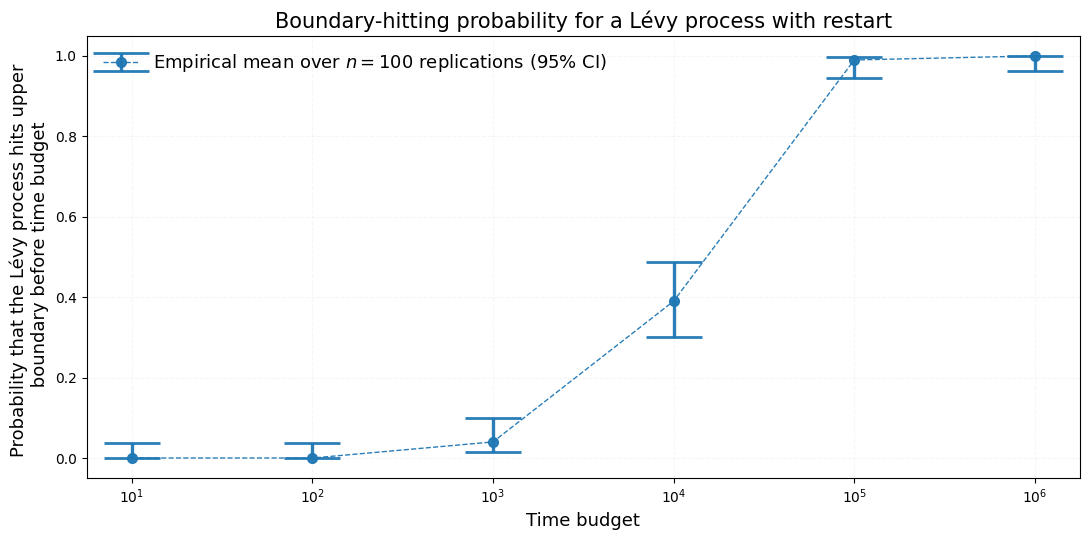
核心思路:论文的核心思路是通过并行模拟和重启机制来提高探索效率。并行模拟允许智能体同时探索多个不同的轨迹,增加发现罕见状态的机会。重启机制则是在探索停滞时,将智能体重新放置到更有希望的区域,避免无效探索。
技术框架:论文的技术框架主要包括以下几个部分:1) 使用随机游走和Lévy过程构建简化环境模型;2) 分析并行模拟数量对达到罕见状态概率的影响;3) 提出并分析重启机制对探索效率的提升;4) 通过理论分析和实验验证所提出的策略。
关键创新:论文的关键创新在于:1) 通过理论分析揭示了并行模拟数量与探索效率之间的关系,并确定了最优的并行模拟数量;2) 提出了一种基于重启机制的探索策略,能够有效地将探索导向更有希望的区域,从而提高探索效率。
关键设计:论文的关键设计包括:1) 使用随机游走和Lévy过程来简化环境模型,便于进行理论分析;2) 定义了达到罕见状态的概率作为评估探索效率的指标;3) 设计了重启机制的具体实现方式,例如如何选择重启的位置。
🖼️ 关键图片
📊 实验亮点
论文通过理论分析和简化模型验证了所提出策略的有效性。研究表明,存在一个最优的并行模拟数量,能够最大化达到罕见状态的概率。此外,重启机制能够指数级地提高成功概率,显著提升探索效率。这些结果为实际应用中设计高效的探索策略提供了理论指导。
🎯 应用场景
该研究成果可应用于机器人导航、游戏AI、药物发现等领域。在这些领域中,智能体需要在复杂且未知的环境中进行探索,并发现罕见但重要的事件。通过应用论文提出的高效探索策略,可以显著提高智能体的学习效率和性能,从而解决实际问题。
📄 摘要(原文)
We investigate efficient exploration strategies of environments with unknown stochastic dynamics and sparse rewards. Specifically, we analyze first the impact of parallel simulations on the probability of reaching rare states within a finite time budget. Using simplified models based on random walks and Lévy processes, we provide analytical results that demonstrate a phase transition in reaching probabilities as a function of the number of parallel simulations. We identify an optimal number of parallel simulations that balances exploration diversity and time allocation. Additionally, we analyze a restarting mechanism that exponentially enhances the probability of success by redirecting efforts toward more promising regions of the state space. Our findings contribute to a more qualitative and quantitative theory of some exploration schemes in reinforcement learning, offering insights into developing more efficient strategies for environments characterized by rare events.