Bridging Molecular Graphs and Large Language Models
作者: Runze Wang, Mingqi Yang, Yanming Shen
分类: cs.LG
发布日期: 2025-03-05 (更新: 2025-03-10)
备注: AAAI 2025 camera ready version
💡 一句话要点
提出Graph2Token,将分子图与大语言模型对齐,实现分子性质预测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分子图 大语言模型 图神经网络 分子性质预测 少样本学习 图文对齐 药物发现
📋 核心要点
- 现有大语言模型在处理分子图等图数据时存在局限性,无法有效利用其强大的泛化能力。
- Graph2Token 通过将分子图表示为 LLM 可理解的 tokens,无需微调 LLM 主干网络,实现图与文本的对齐。
- 实验结果表明,该方法在分子分类和回归任务上表现出色,验证了其在分子少样本学习中的有效性。
📝 摘要(中文)
大语言模型(LLMs)展现了卓越的泛化能力,但处理分子结构等图数据的能力仍然有限。为了弥合这一差距,本文提出了Graph2Token,一种将图 tokens 与 LLM tokens 对齐的有效解决方案。核心思想是用 LLM token 词汇表来表示图 token,而无需微调 LLM 主干。为此,我们首先从 CHEBI 和 HMDB 等多源数据构建分子-文本配对数据集,以训练图结构编码器,从而缩小特征空间中图和文本表示之间的距离。然后,我们提出了一种新颖的对齐策略,将图 token 与 LLM tokens 相关联。为了进一步释放 LLM 的潜力,我们收集了分子 IUPAC 名称标识符,并将其纳入 LLM 提示中。通过将分子图对齐为特殊 tokens,我们可以激活 LLM 对分子少样本学习的泛化能力。在分子分类和回归任务上的大量实验证明了我们提出的 Graph2Token 的有效性。
🔬 方法详解
问题定义:现有的大语言模型虽然在自然语言处理任务上表现出色,但在直接处理分子图结构数据时存在困难。它们无法有效地利用分子图的结构信息进行推理和预测,导致在分子性质预测等任务上的性能受限。现有的图神经网络方法虽然可以处理图数据,但缺乏大语言模型的泛化能力。
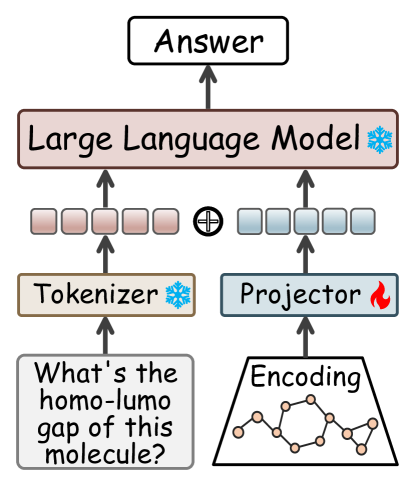
核心思路:Graph2Token 的核心思路是将分子图转换为大语言模型可以理解的 tokens,从而利用大语言模型的强大能力。通过学习图 tokens 和 LLM tokens 之间的映射关系,使得 LLM 可以像处理文本一样处理分子图数据。这样既保留了分子图的结构信息,又充分利用了 LLM 的泛化能力。
技术框架:Graph2Token 的整体框架包括以下几个主要模块:1) 分子-文本配对数据集构建:从 CHEBI 和 HMDB 等数据库构建分子结构和对应文本描述的数据集。2) 图结构编码器训练:使用配对数据集训练一个图结构编码器,将分子图编码为向量表示。3) 图 tokens 与 LLM tokens 对齐:提出一种新的对齐策略,将图 tokens 与 LLM tokens 相关联,学习它们之间的映射关系。4) LLM 提示构建:将分子 IUPAC 名称等信息加入 LLM 提示中,以增强 LLM 的理解能力。
关键创新:Graph2Token 的关键创新在于提出了一种将图 tokens 与 LLM tokens 对齐的策略,使得 LLM 可以在不进行微调的情况下处理分子图数据。这种方法避免了对 LLM 主干网络的修改,降低了计算成本,并保留了 LLM 的泛化能力。与现有方法相比,Graph2Token 更加高效和灵活。
关键设计:在分子-文本配对数据集构建中,需要仔细选择数据来源和构建策略,以保证数据的质量和多样性。在图结构编码器训练中,可以使用对比学习等方法来缩小图和文本表示之间的距离。在图 tokens 与 LLM tokens 对齐中,可以使用注意力机制等方法来学习它们之间的映射关系。在 LLM 提示构建中,需要选择合适的分子标识符,并设计有效的提示模板。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Graph2Token 在分子分类和回归任务上取得了显著的性能提升。例如,在某些分子性质预测任务上,Graph2Token 的性能超过了现有的图神经网络方法。此外,Graph2Token 在少样本学习场景下表现出色,证明了其能够有效利用大语言模型的泛化能力。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
Graph2Token 的潜在应用领域包括药物发现、材料科学和化学信息学。它可以用于预测分子的性质、筛选候选药物、设计新型材料等。通过将分子图与大语言模型相结合,可以加速新药和新材料的研发过程,并降低研发成本。未来,该方法还可以应用于其他类型的图数据,例如社交网络和知识图谱。
📄 摘要(原文)
While Large Language Models (LLMs) have shown exceptional generalization capabilities, their ability to process graph data, such as molecular structures, remains limited. To bridge this gap, this paper proposes Graph2Token, an efficient solution that aligns graph tokens to LLM tokens. The key idea is to represent a graph token with the LLM token vocabulary, without fine-tuning the LLM backbone. To achieve this goal, we first construct a molecule-text paired dataset from multisources, including CHEBI and HMDB, to train a graph structure encoder, which reduces the distance between graphs and texts representations in the feature space. Then, we propose a novel alignment strategy that associates a graph token with LLM tokens. To further unleash the potential of LLMs, we collect molecular IUPAC name identifiers, which are incorporated into the LLM prompts. By aligning molecular graphs as special tokens, we can activate LLM generalization ability to molecular few-shot learning. Extensive experiments on molecular classification and regression tasks demonstrate the effectiveness of our proposed Graph2Token.