KodCode: A Diverse, Challenging, and Verifiable Synthetic Dataset for Coding
作者: Zhangchen Xu, Yang Liu, Yueqin Yin, Mingyuan Zhou, Radha Poovendran
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-03-04 (更新: 2025-07-12)
备注: Accepted by ACL 2025. Codes and Data: https://kodcode-ai.github.io/
💡 一句话要点
KodCode:一个多样、具挑战性且可验证的代码合成数据集,用于提升代码大语言模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大语言模型 合成数据集 自验证 代码智能
📋 核心要点
- 现有代码数据集在覆盖范围和可验证性上存在不足,难以满足大语言模型训练需求。
- KodCode通过合成问题、生成解决方案和测试用例,并进行自验证,构建高质量数据集。
- 实验表明,使用KodCode微调的模型在多个代码基准测试中取得了领先性能。
📝 摘要(中文)
本文介绍KodCode,一个合成数据集,旨在解决训练用于代码生成的大语言模型时,获取高质量、可验证的训练数据的难题,尤其是在覆盖不同难度和领域方面。现有的代码资源通常无法保证覆盖范围的广度(例如,从简单的编码任务到高级算法问题)或可验证的正确性(例如,单元测试)。相比之下,KodCode包含问题-解决方案-测试三元组,这些三元组通过自验证程序进行系统验证。该流程首先合成各种编码问题,然后生成解决方案和测试用例,并为具有挑战性的问题分配额外的尝试机会。最后,通过将问题改写成不同的格式,并从推理模型(DeepSeek R1)中进行基于测试的拒绝采样,来完成训练后数据合成。该流程产生了一个大规模、鲁棒且多样化的编码数据集。KodCode适用于监督微调,配对的单元测试也为强化学习微调提供了巨大的潜力。在代码基准测试(HumanEval(+), MBPP(+), BigCodeBench, and LiveCodeBench)上的微调实验表明,KodCode微调的模型实现了最先进的性能,超过了Qwen2.5-Coder-32B-Instruct和DeepSeek-R1-Distill-Llama-70B等模型。
🔬 方法详解
问题定义:现有代码数据集通常缺乏足够的广度和可验证性。广度不足体现在难以覆盖从简单到复杂的各类编程任务,而可验证性缺失则使得模型难以学习到正确的代码逻辑。这限制了代码大语言模型的训练效果和泛化能力。
核心思路:KodCode的核心思路是通过合成的方式构建一个多样、具挑战性且可验证的代码数据集。通过精心设计的生成流程,确保数据集覆盖各种难度和领域的编程问题,并利用单元测试进行严格的正确性验证。
技术框架:KodCode的整体框架包含以下几个主要阶段: 1. 问题合成:生成各种类型的编码问题。 2. 解决方案生成:为每个问题生成对应的解决方案。 3. 测试用例生成:为每个问题生成相应的测试用例。 4. 自验证:使用测试用例验证解决方案的正确性,并进行迭代优化。 5. 后训练数据合成:通过改写问题和基于测试的拒绝采样,增加数据的多样性。
关键创新:KodCode的关键创新在于其系统化的自验证流程和后训练数据合成方法。自验证流程确保了数据集的高质量和可靠性,而后训练数据合成则进一步提升了数据的多样性和泛化能力。与现有方法相比,KodCode不仅关注数据的数量,更注重数据的质量和多样性。
关键设计:KodCode的关键设计包括: 1. 问题合成策略:采用多种策略生成不同难度和类型的编程问题,例如算法题、数据结构题、以及实际应用场景题。 2. 测试用例生成策略:设计有效的测试用例,覆盖各种边界条件和异常情况,确保解决方案的正确性。 3. 拒绝采样策略:基于测试结果对生成的解决方案进行筛选,只保留通过测试的解决方案,保证数据集的质量。 4. 后训练数据合成策略:通过改写问题和基于测试的拒绝采样,增加数据的多样性。
🖼️ 关键图片

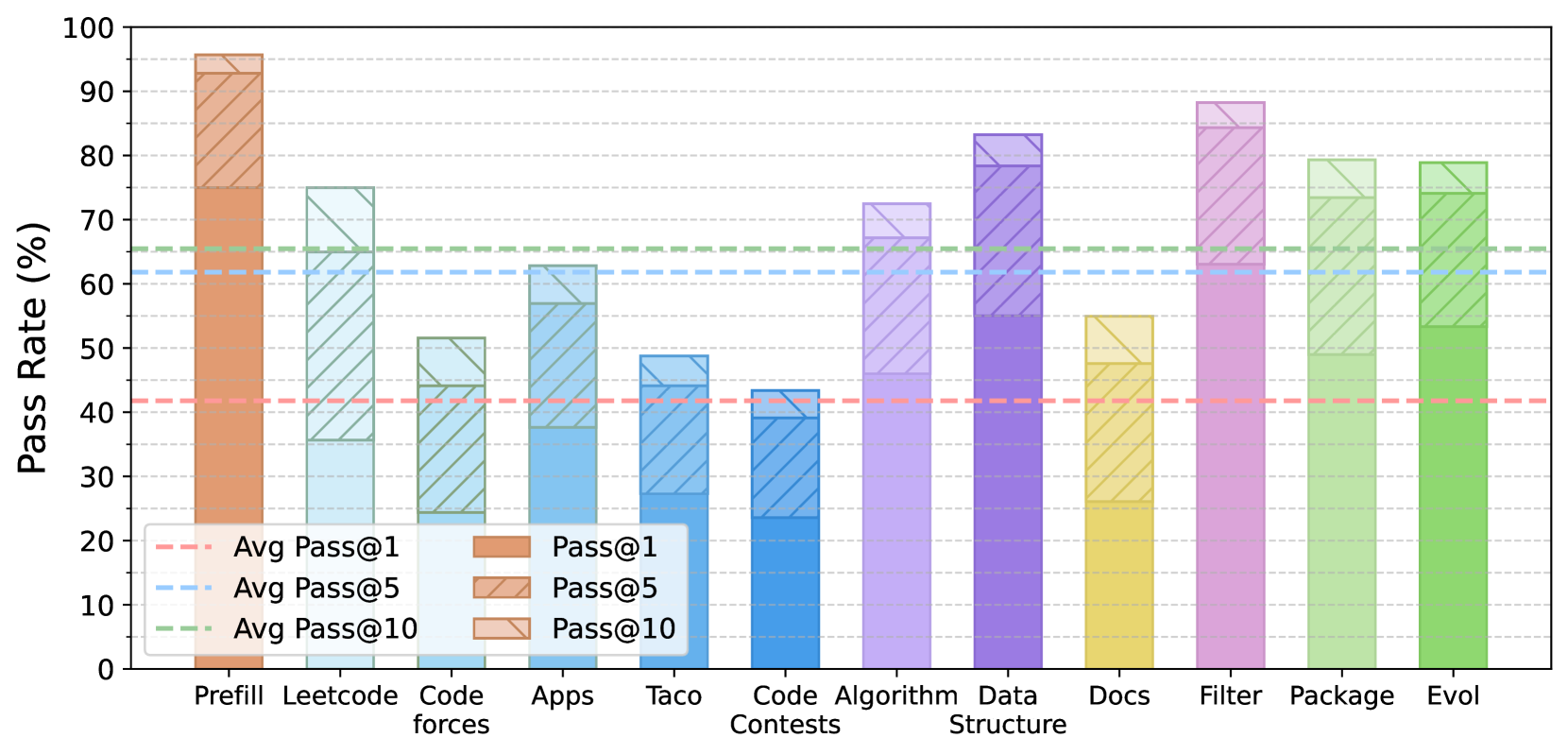
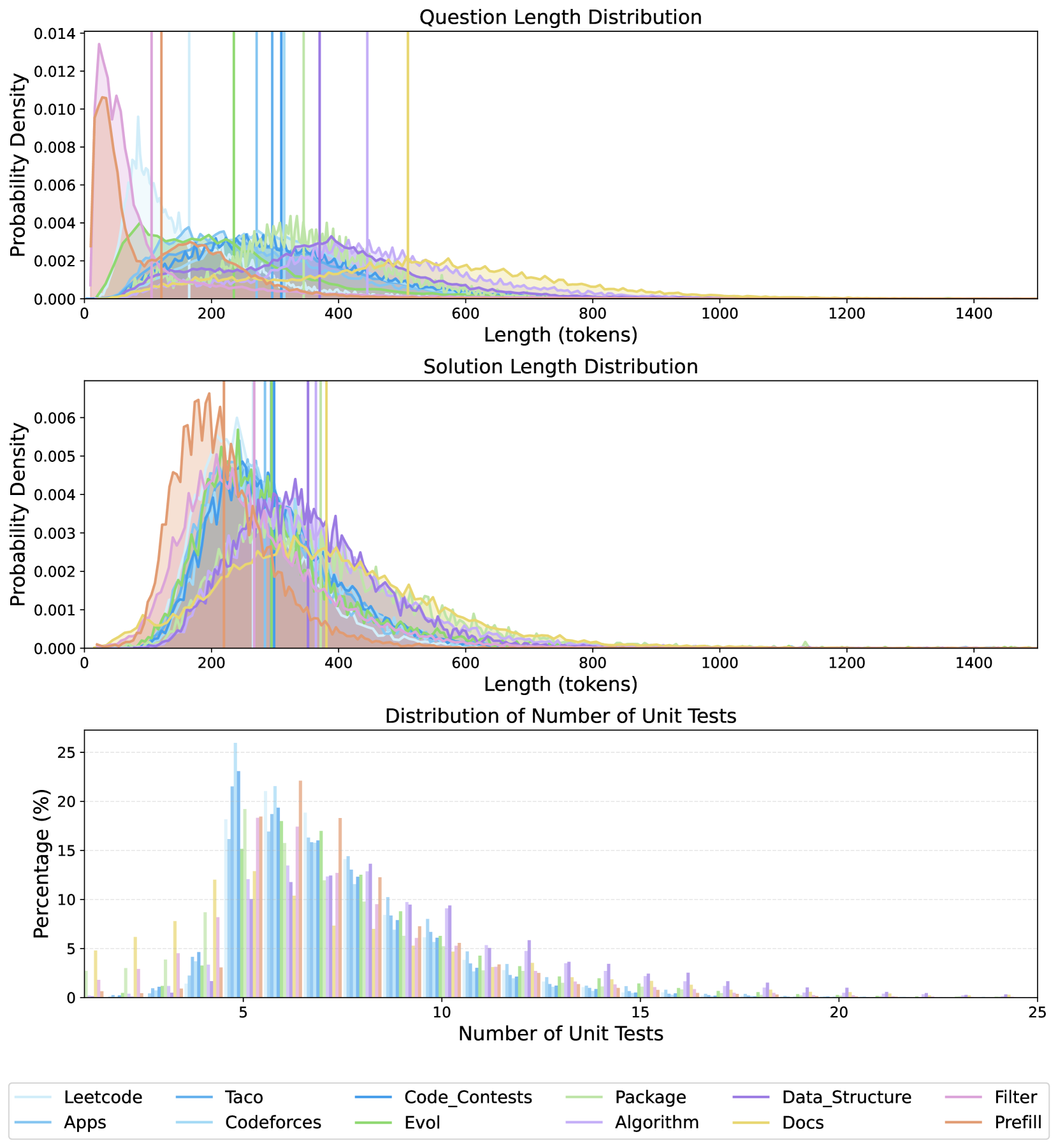
📊 实验亮点
实验结果表明,使用KodCode微调的模型在HumanEval(+), MBPP(+), BigCodeBench, 和 LiveCodeBench等代码基准测试中取得了最先进的性能,超越了Qwen2.5-Coder-32B-Instruct和DeepSeek-R1-Distill-Llama-70B等模型。这证明了KodCode数据集的有效性和优越性。
🎯 应用场景
KodCode数据集可广泛应用于代码大语言模型的预训练、微调和强化学习。它可以帮助模型学习更广泛的编程知识,提高代码生成质量和正确性,并促进代码智能在软件开发、自动化测试、教育等领域的应用。未来,该数据集可以进一步扩展到更多编程语言和领域,为代码智能的发展提供更强大的支持。
📄 摘要(原文)
We introduce KodCode, a synthetic dataset that addresses the persistent challenge of acquiring high-quality, verifiable training data across diverse difficulties and domains for training Large Language Models for coding. Existing code-focused resources typically fail to ensure either the breadth of coverage (e.g., spanning simple coding tasks to advanced algorithmic problems) or verifiable correctness (e.g., unit tests). In contrast, KodCode comprises question-solution-test triplets that are systematically validated via a self-verification procedure. Our pipeline begins by synthesizing a broad range of coding questions, then generates solutions and test cases with additional attempts allocated to challenging problems. Finally, post-training data synthesis is done by rewriting questions into diverse formats and generating responses under a test-based reject sampling procedure from a reasoning model (DeepSeek R1). This pipeline yields a large-scale, robust and diverse coding dataset. KodCode is suitable for supervised fine-tuning and the paired unit tests also provide great potential for RL tuning. Fine-tuning experiments on coding benchmarks (HumanEval(+), MBPP(+), BigCodeBench, and LiveCodeBench) demonstrate that KodCode-tuned models achieve state-of-the-art performance, surpassing models like Qwen2.5-Coder-32B-Instruct and DeepSeek-R1-Distill-Llama-70B.