Language Models can Self-Improve at State-Value Estimation for Better Search
作者: Ethan Mendes, Alan Ritter
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-03-04 (更新: 2025-10-29)
💡 一句话要点
提出自学习前瞻(STL)框架,提升语言模型在状态值估计上的能力,从而改进搜索。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自监督学习 价值函数 语言模型 状态值估计 链式思维 多步推理 Web代理
📋 核心要点
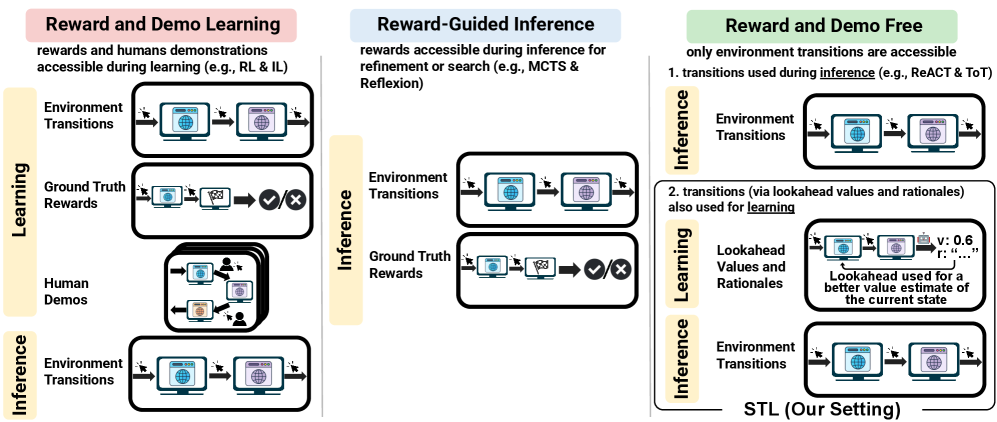
- 多步推理任务中,获取奖励信号或人工演示成本高昂,限制了语言模型在交互式任务中的应用。
- 提出自学习前瞻(STL)框架,通过自监督学习,使语言模型能够模拟状态转移并改进价值估计。
- 实验表明,STL显著提升了Web代理的成功率,并能推广到多跳问答和数学难题,降低推理成本。
📝 摘要(中文)
针对多步推理任务,尤其是在Web任务等交互式领域中,获取真实奖励或人工演示的成本通常过高。本文提出了一种免奖励框架——自学习前瞻(STL),通过显式地推理状态转移来改进基于语言模型的值函数。STL可以被视为思维链版本的价值迭代算法:值语言模型不是直接回归数值,而是被训练来模拟自然语言中的前瞻步骤——预测下一个动作、结果状态以及其价值的理由,从而在没有任何标注数据的情况下改进价值估计。这种自监督过程产生更准确的状态值预测,进而使轻量级搜索算法能够在保持强大性能的同时扩展更少的状态。实验结果表明,基于中等规模(80亿参数)的开源语言模型构建的STL训练值模型,将Web代理的成功率提高了39%,达到了与专有模型相当的性能。STL还推广到多跳问答和数学难题。我们发现,STL使小型开源模型能够指导高效搜索,通过将显式推理与价值学习相结合来降低推理成本。
🔬 方法详解
问题定义:论文旨在解决多步推理任务中,由于缺乏标注数据导致语言模型难以准确估计状态值,进而影响搜索效率的问题。现有方法依赖大量人工标注或奖励信号,成本高昂,限制了其在交互式环境中的应用。
核心思路:论文的核心思路是利用自监督学习,让语言模型通过模拟状态转移过程来学习价值函数。模型通过预测下一步动作、结果状态以及价值理由,实现对状态值的迭代改进,无需人工标注数据。这种“自学习”的方式降低了对外部监督信号的依赖。
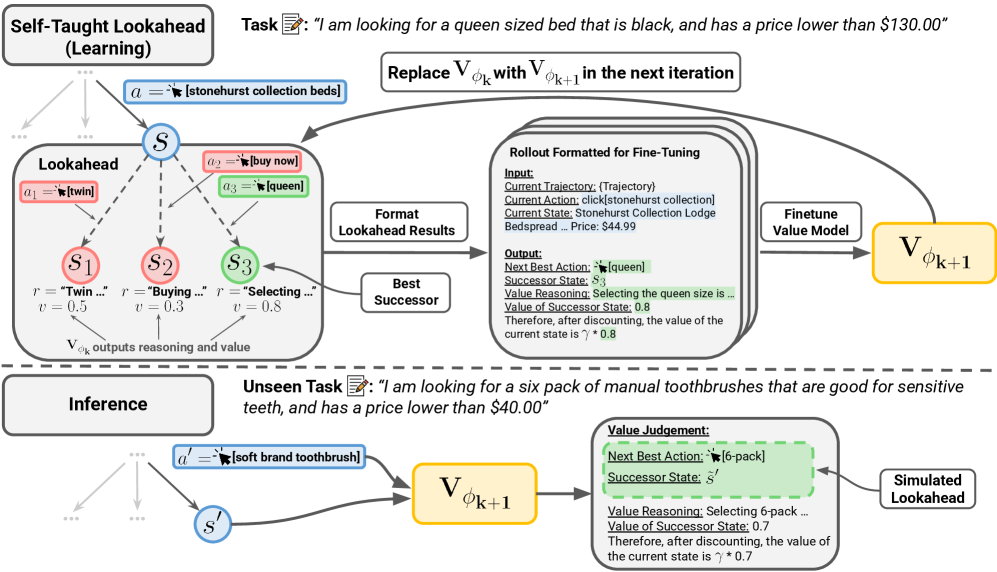
技术框架:STL框架的核心是一个值语言模型,该模型被训练来预测给定状态下的最优动作、执行该动作后的状态以及该状态的价值。训练过程采用自监督方式,通过迭代地模拟状态转移,不断优化值函数的预测能力。整体流程类似于价值迭代算法的链式思维版本。
关键创新:STL的关键创新在于将价值迭代算法的思想与链式思维相结合,通过语言模型模拟状态转移过程,实现免奖励的价值函数学习。与传统的直接回归数值的方法不同,STL通过预测动作、状态和理由,引入了显式的推理过程,提高了价值估计的准确性和可解释性。
关键设计:STL的关键设计包括:1) 使用链式思维提示工程,引导语言模型进行状态转移的模拟;2) 设计合适的损失函数,鼓励模型预测准确的动作、状态和价值理由;3) 通过迭代训练,不断优化值函数的预测能力。具体的参数设置和网络结构取决于所使用的语言模型。
🖼️ 关键图片
📊 实验亮点
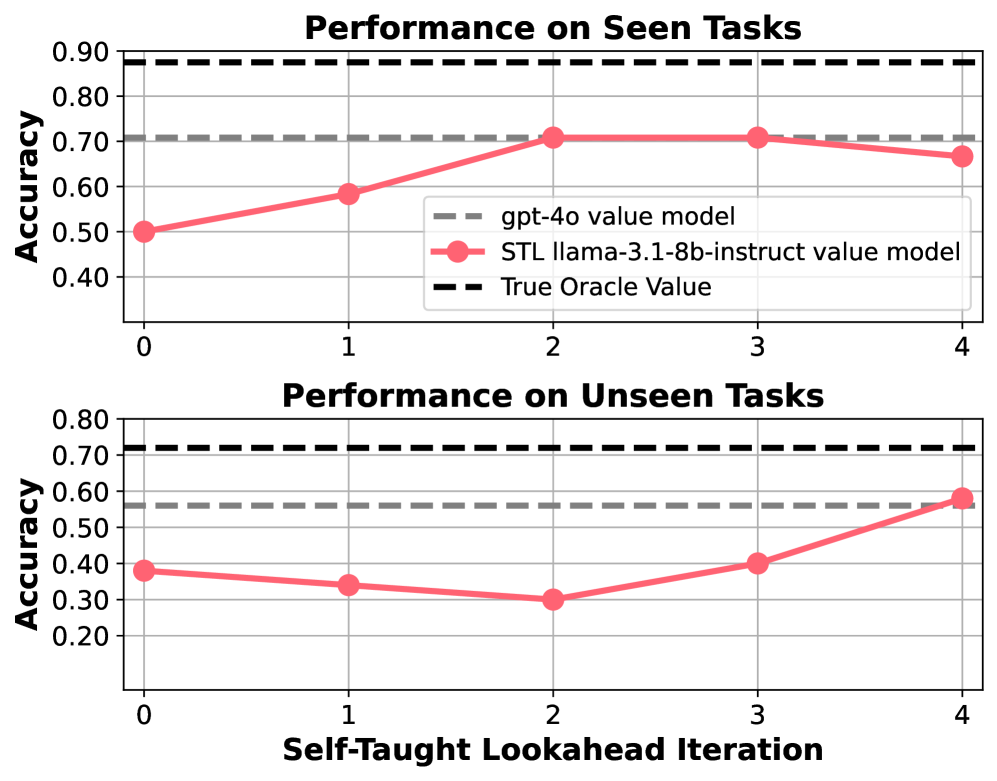
实验结果表明,基于80亿参数的开源语言模型,使用STL训练的值模型将Web代理的成功率提高了39%,达到了与专有模型相当的性能。此外,STL还成功推广到多跳问答和数学难题,证明了其泛化能力。实验还表明,STL能够指导高效搜索,降低推理成本。
🎯 应用场景
该研究成果可应用于Web任务、机器人导航、游戏AI等需要多步推理和决策的领域。通过提升语言模型的状态值估计能力,可以构建更智能、更高效的智能体,降低人工干预成本,并有望推动人机协作的进一步发展。此外,该方法在教育领域也有潜在应用,例如辅助学生进行问题解决和决策。
📄 摘要(原文)
Collecting ground-truth rewards or human demonstrations for multi-step reasoning tasks is often prohibitively expensive, particularly in interactive domains such as web tasks. We introduce Self-Taught Lookahead (STL), a reward-free framework that improves language model-based value functions by reasoning explicitly about state transitions. STL can be viewed as a chain-of-thought analogue of the value iteration algorithm: instead of regressing directly on numeric values, a value LLM is trained to simulate a step of lookahead in natural language - predicting the next action, resulting state, and rationale for its value, thereby refining value estimates without any labeled data. This self-supervised procedure yields more accurate state-value predictions, which in turn enable lightweight search algorithms to expand fewer states while maintaining strong performance. Empirically, STL-trained value models built on moderately sized (8B parameter) open-weight LLMs boost web agent success rates by 39%, achieving comparable performance with proprietary models. STL also generalizes to multi-hop QA and math puzzles. We find that STL enables small open-source models to guide efficient search, reducing inference costs by integrating explicit reasoning with value learning.