Smoothing the Shift: Towards Stable Test-Time Adaptation under Complex Multimodal Noises
作者: Zirun Guo, Tao Jin
分类: cs.LG, cs.CV
发布日期: 2025-03-04
备注: Accepted at ICLR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出SuMi方法,解决复杂多模态噪声下的稳定测试时自适应问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 测试时自适应 多模态学习 分布偏移 噪声鲁棒性 互信息 四分位距 样本选择
📋 核心要点
- 现有测试时自适应方法在复杂多模态噪声(如模态缺失、同时损坏)下,由于突变分布偏移导致性能显著下降。
- 提出SuMi方法,通过四分位距平滑自适应过程,并利用单模态信息辅助选择高质量样本,实现稳定自适应。
- 实验结果表明,SuMi在多模态数据集上,面对复杂噪声时,显著优于现有测试时自适应方法。
📝 摘要(中文)
本文旨在解决测试时自适应(TTA)在多模态数据中面临的复杂噪声问题,包括多模态的同时损坏和模态缺失。作者揭示了一个新的挑战,即多模态野外TTA,现有TTA方法在这种情况下失效,因为突变分布偏移会破坏源模型的先验知识,导致性能下降。为此,作者提出了两种新策略:基于四分位距平滑的样本识别和单模态辅助,以及互信息共享(SuMi)。SuMi通过四分位距平滑自适应过程,避免了突变分布偏移。然后,SuMi充分利用单模态特征来选择具有丰富多模态信息的低熵样本进行优化。此外,引入互信息共享来对齐信息,减少差异,并增强不同模态之间的信息利用。在两个公共数据集上的大量实验表明,该方法在复杂噪声模式下优于现有方法。
🔬 方法详解
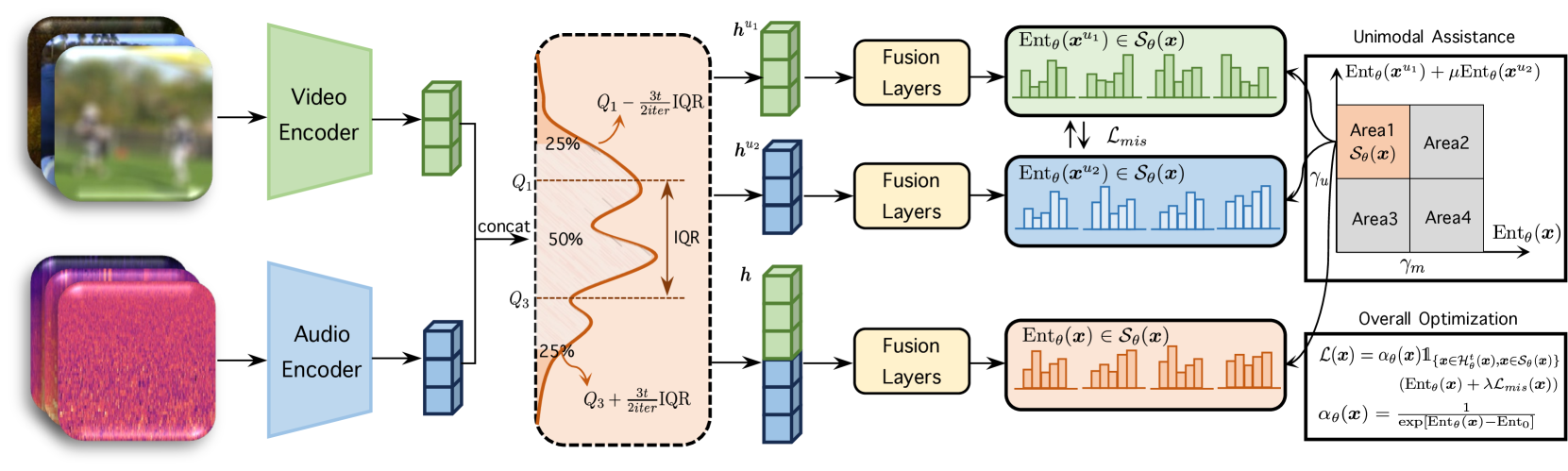
问题定义:论文旨在解决多模态数据在测试时自适应(TTA)过程中,由于复杂的噪声模式(如多模态同时损坏、模态缺失以及混合分布偏移)导致的性能下降问题。现有的TTA方法在处理单模态数据时已经面临挑战,而在多模态场景下,由于模态间的依赖关系和噪声的复杂性,现有方法难以有效利用源模型的先验知识,从而导致性能急剧下降。这种问题被称为“多模态野外TTA”。
核心思路:论文的核心思路是通过平滑自适应过程来避免突变分布偏移,并充分利用单模态信息来辅助选择高质量样本。具体来说,首先使用四分位距(Interquartile Range, IQR)来平滑自适应过程,减少每次迭代的更新幅度,从而避免模型参数的剧烈变化。其次,利用单模态特征来选择低熵样本,这些样本通常包含更丰富的多模态信息,更适合用于优化模型。最后,通过互信息共享(Mutual Information Sharing)来对齐不同模态的信息,减少模态间的差异,并增强信息利用。
技术框架:SuMi方法的整体框架包含以下几个主要步骤:1) 样本识别:利用四分位距平滑策略,识别出受噪声影响较小的样本。同时,利用单模态信息选择低熵样本。2) 模型更新:使用选择出的高质量样本,对模型参数进行更新。更新过程受到四分位距的约束,避免参数剧烈变化。3) 互信息共享:通过互信息最大化,对齐不同模态的信息,减少模态间的差异。这个过程通常通过添加互信息损失函数来实现。
关键创新:论文的关键创新在于以下几点:1) 提出了多模态野外TTA这一新的挑战。2) 提出了基于四分位距平滑的自适应策略,有效避免了突变分布偏移。3) 提出了利用单模态信息辅助选择高质量样本的方法,提高了样本选择的准确性。4) 引入了互信息共享机制,增强了不同模态之间的信息利用。与现有方法的本质区别在于,SuMi更加关注自适应过程的稳定性,并充分利用了单模态信息来辅助多模态学习。
关键设计:在关键设计方面,论文可能涉及以下细节:1) 四分位距的计算方式:如何根据历史参数变化来计算四分位距,并将其用于约束参数更新。2) 单模态信息的使用:如何利用单模态特征来计算样本的熵,并根据熵值选择高质量样本。3) 互信息损失函数的设计:如何设计互信息损失函数,以有效地对齐不同模态的信息。4) 模型架构:具体使用的多模态模型架构,例如,是否使用了Transformer或其他类型的神经网络。
🖼️ 关键图片

📊 实验亮点
论文在两个公共数据集上进行了大量实验,结果表明SuMi方法在复杂噪声模式下显著优于现有TTA方法。具体的性能提升数据需要在论文中查找,但摘要中明确指出SuMi在复杂噪声模式下表现出优越性,证明了其在多模态野外TTA问题上的有效性。
🎯 应用场景
该研究成果可应用于自动驾驶、医疗诊断、机器人等领域,这些领域通常涉及多模态数据,且数据分布可能随时间变化。通过SuMi方法,可以提高模型在实际应用中的鲁棒性和泛化能力,降低模型部署和维护成本,具有重要的实际应用价值和潜在的商业前景。
📄 摘要(原文)
Test-Time Adaptation (TTA) aims to tackle distribution shifts using unlabeled test data without access to the source data. In the context of multimodal data, there are more complex noise patterns than unimodal data such as simultaneous corruptions for multiple modalities and missing modalities. Besides, in real-world applications, corruptions from different distribution shifts are always mixed. Existing TTA methods always fail in such multimodal scenario because the abrupt distribution shifts will destroy the prior knowledge from the source model, thus leading to performance degradation. To this end, we reveal a new challenge named multimodal wild TTA. To address this challenging problem, we propose two novel strategies: sample identification with interquartile range Smoothing and unimodal assistance, and Mutual information sharing (SuMi). SuMi smooths the adaptation process by interquartile range which avoids the abrupt distribution shifts. Then, SuMi fully utilizes the unimodal features to select low-entropy samples with rich multimodal information for optimization. Furthermore, mutual information sharing is introduced to align the information, reduce the discrepancies and enhance the information utilization across different modalities. Extensive experiments on two public datasets show the effectiveness and superiority over existing methods under the complex noise patterns in multimodal data. Code is available at https://github.com/zrguo/SuMi.