Using (Not-so) Large Language Models to Generate Simulation Models in a Formal DSL: A Study on Reaction Networks
作者: Justin N. Kreikemeyer, Miłosz Jankowski, Pia Wilsdorf, Adelinde M. Uhrmacher
分类: cs.LG, cs.CL
发布日期: 2025-03-03 (更新: 2025-10-22)
备注: 27 pages, 5 figures; supplemental material available at https://doi.org/10.1145/3733719
期刊: ACM Trans. Model. Comput. Simul. 35, 4, Article 31 (October 2025), 27 pages
DOI: 10.1145/3733719
💡 一句话要点
利用小型语言模型生成形式化DSL中的仿真模型,以反应网络为例。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 反应网络 领域特定语言 模型微调 自然语言处理
📋 核心要点
- 现有方法依赖大型商业LLM进行自然语言到形式化模型的转换,成本高且缺乏灵活性。
- 本文提出微调一个开源的、参数量较小的Mistral模型,使其能够将自然语言描述转换为反应网络模型。
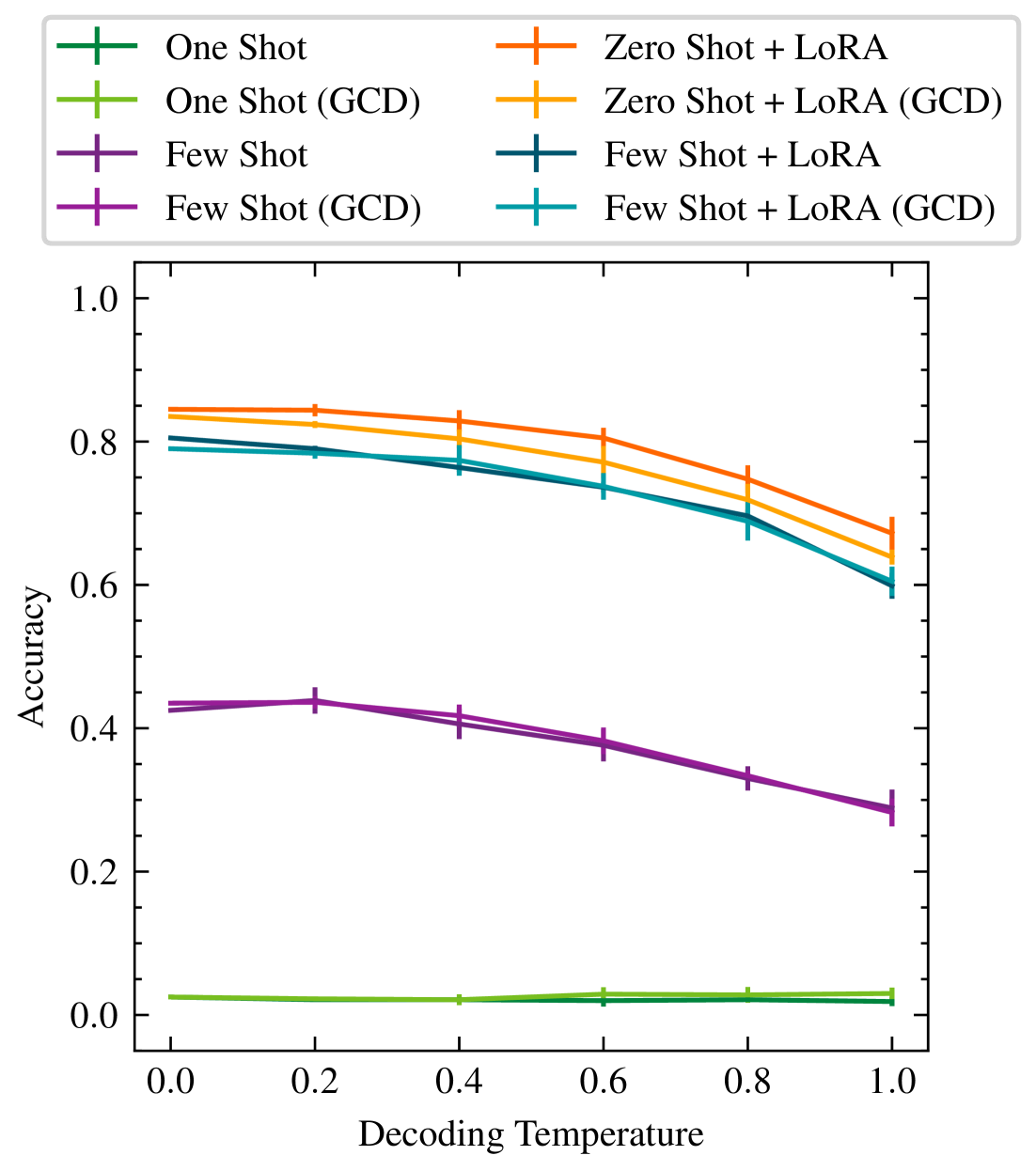
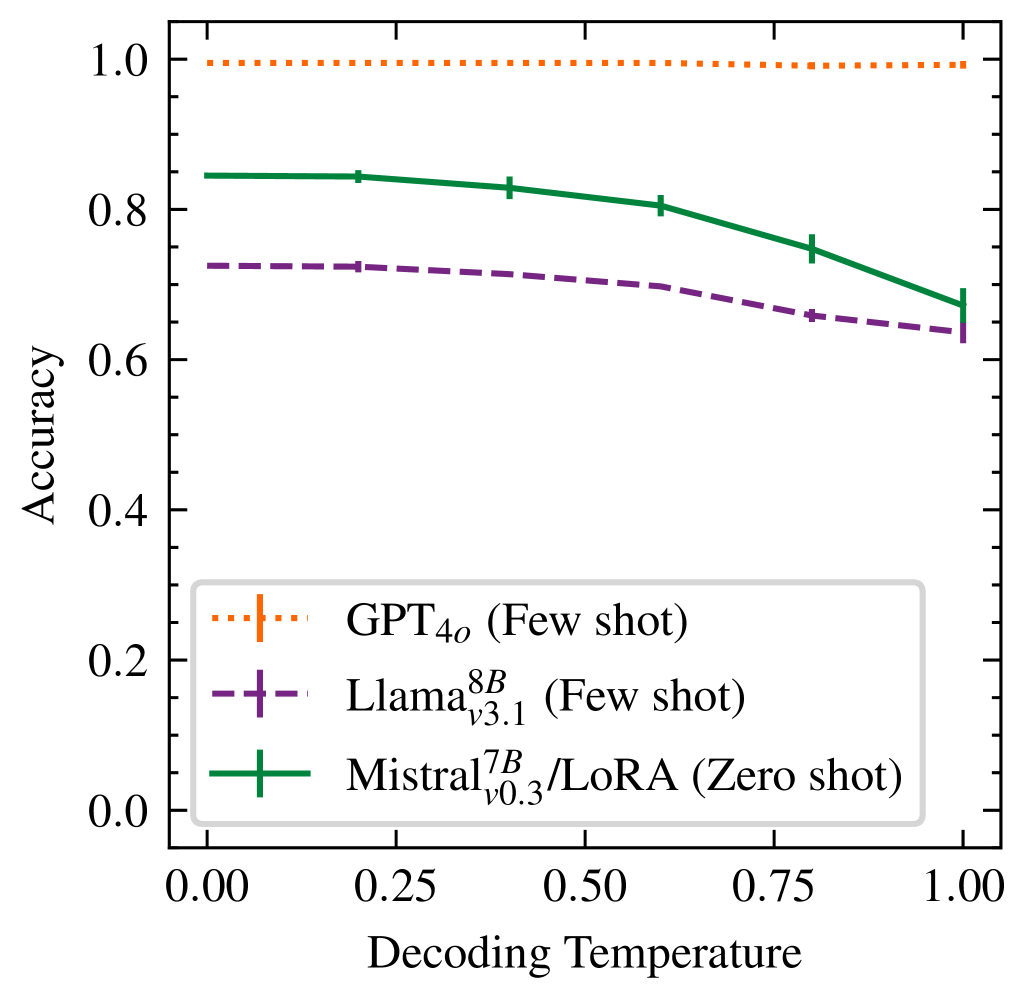
- 实验结果表明,微调后的Mistral模型在高达84.5%的情况下可以恢复ground truth仿真模型。
📝 摘要(中文)
形式化语言是建模与仿真的重要组成部分,它允许将知识提炼成简洁的仿真模型,以便自动执行、解释和分析。然而,人类最容易理解的表达模型的方式是通过自然语言,但计算机不容易解释自然语言。本文评估了如何使用大型语言模型(LLM)将自然语言形式化为仿真模型。现有研究仅探索了使用非常大的LLM,如商业GPT模型,而没有微调模型权重。为了弥补这一差距,我们展示了如何微调一个开放权重、70亿参数的Mistral模型,以将自然语言描述翻译成领域特定语言的反应网络模型,从而提供一个可自托管、计算高效且内存高效的替代方案。为此,我们开发了一个合成数据生成器,作为微调和评估的基础。我们的定量评估表明,我们微调的Mistral模型在高达84.5%的情况下可以恢复ground truth仿真模型。此外,我们的小规模用户研究证明了该模型在各种领域中一次性生成以及交互式建模的实际潜力。虽然前景广阔,但就目前的形式而言,微调的小型LLM无法赶上大型LLM。我们得出结论,需要更高质量的训练数据,并期望未来小型和开源LLM提供新的机会。
🔬 方法详解
问题定义:论文旨在解决将自然语言描述的反应网络模型自动转换为形式化领域特定语言(DSL)模型的问题。现有方法主要依赖于大型商业LLM,例如GPT系列,这些模型计算成本高昂,且用户无法完全控制模型。此外,这些大型模型通常未经针对特定领域的微调,可能导致转换精度不足。
核心思路:论文的核心思路是利用一个相对较小的、开源的LLM(Mistral 7B)进行微调,使其能够有效地将自然语言描述转换为反应网络DSL模型。通过微调,模型可以更好地适应特定领域的知识和语法规则,从而提高转换的准确性和效率。这种方法旨在提供一种更经济、更可控的替代方案,以替代大型商业LLM。
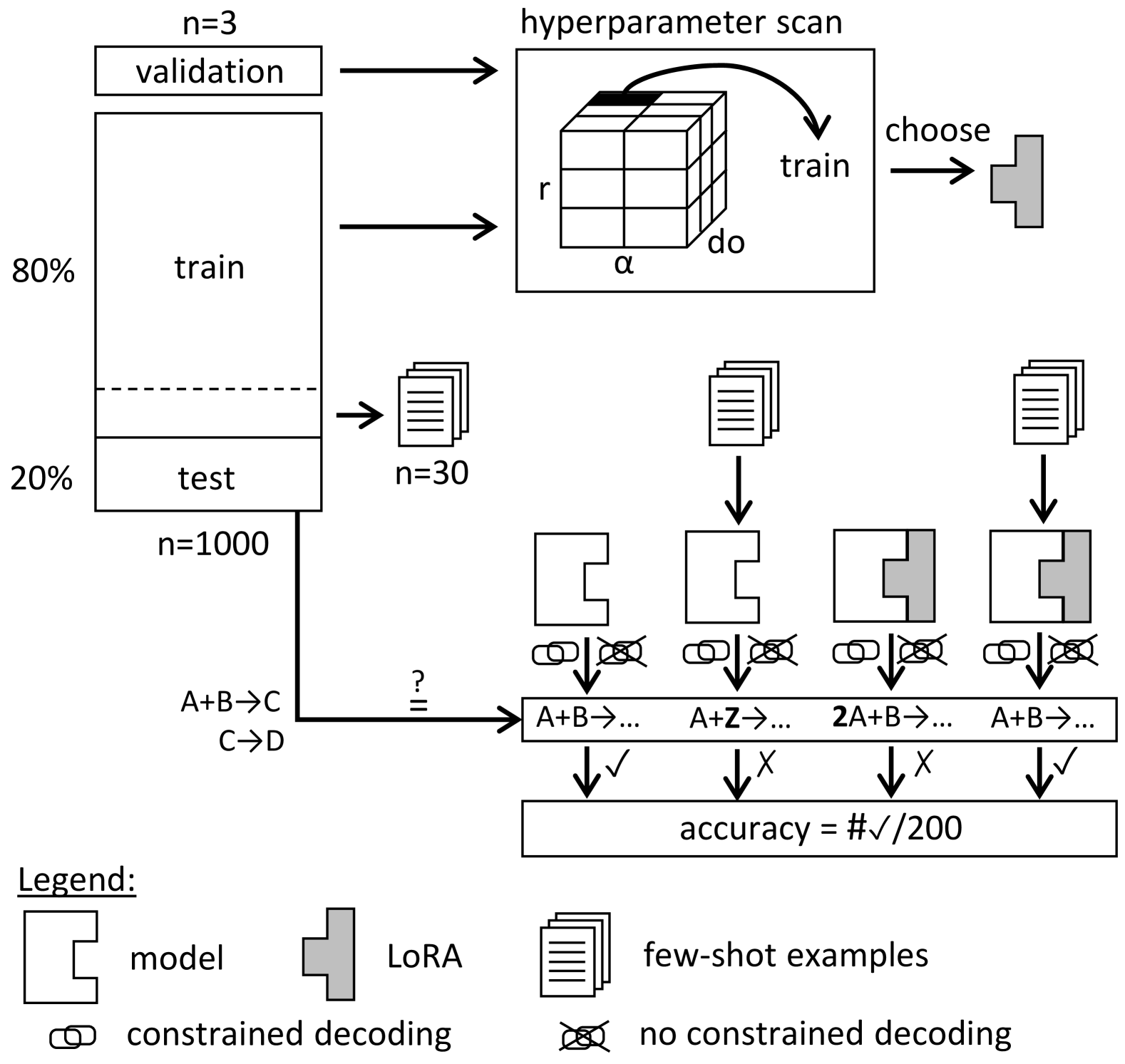
技术框架:整体框架包括以下几个主要步骤:1) 构建合成数据生成器,用于生成自然语言描述及其对应的反应网络DSL模型;2) 使用生成的数据集对Mistral 7B模型进行微调;3) 使用测试数据集评估微调后的模型性能;4) 进行小规模用户研究,评估模型在实际应用中的可用性。该框架的核心是数据生成和模型微调,旨在使小型LLM能够胜任特定领域的自然语言到形式化模型的转换任务。
关键创新:论文的关键创新在于证明了小型、开源的LLM经过微调后,可以在特定领域内达到与大型商业LLM相媲美的性能。这打破了以往认为只有大型模型才能胜任复杂自然语言处理任务的固有观念。此外,论文还提出了一个合成数据生成方法,用于生成高质量的训练数据,这对于微调小型LLM至关重要。
关键设计:论文的关键设计包括:1) 合成数据生成器的设计,需要保证生成的数据既具有多样性,又能覆盖反应网络DSL的各种语法结构;2) 微调过程中的超参数设置,例如学习率、batch size等,需要仔细调整以获得最佳性能;3) 评估指标的选择,需要能够准确反映模型在实际应用中的性能,例如ground truth模型恢复率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,经过微调的Mistral模型在高达84.5%的情况下可以恢复ground truth仿真模型。这一结果表明,小型LLM经过适当的微调,可以在特定领域内达到与大型LLM相媲美的性能。此外,小规模用户研究也证明了该模型在实际应用中的潜力。
🎯 应用场景
该研究成果可应用于生物建模、化学工程等领域,帮助研究人员快速构建和分析复杂的反应网络模型。通过自动化自然语言到形式化模型的转换,可以显著提高建模效率,降低建模门槛,并促进跨学科的知识共享和协作。未来,该技术有望扩展到其他领域,例如控制系统设计、金融建模等。
📄 摘要(原文)
Formal languages are an integral part of modeling and simulation. They allow the distillation of knowledge into concise simulation models amenable to automatic execution, interpretation, and analysis. However, the arguably most humanly accessible means of expressing models is through natural language, which is not easily interpretable by computers. Here, we evaluate how a Large Language Model (LLM) might be used for formalizing natural language into simulation models. Existing studies only explored using very large LLMs, like the commercial GPT models, without fine-tuning model weights. To close this gap, we show how an open-weights, 7B-parameter Mistral model can be fine-tuned to translate natural language descriptions to reaction network models in a domain-specific language, offering a self-hostable, compute-efficient, and memory efficient alternative. To this end, we develop a synthetic data generator to serve as the basis for fine-tuning and evaluation. Our quantitative evaluation shows that our fine-tuned Mistral model can recover the ground truth simulation model in up to 84.5% of cases. In addition, our small-scale user study demonstrates the model's practical potential for one-time generation as well as interactive modeling in various domains. While promising, in its current form, the fine-tuned small LLM cannot catch up with large LLMs. We conclude that higher-quality training data are required, and expect future small and open-source LLMs to offer new opportunities.