MMSciBench: Benchmarking Language Models on Chinese Multimodal Scientific Problems
作者: Xinwu Ye, Chengfan Li, Siming Chen, Wei Wei, Xiangru Tang
分类: cs.LG, cs.CL
发布日期: 2025-02-27 (更新: 2025-06-01)
备注: Accepted to the Findings of the Association for Computational Linguistics (ACL 2025)
💡 一句话要点
MMSciBench:中文多模态科学问题语言模型评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 科学推理 语言模型 评测基准 中文数据集 视觉-语言模型 数学物理
📋 核心要点
- 现有大型语言模型在科学推理能力,尤其是在多模态场景下,缺乏充分的测试和评估。
- MMSciBench通过构建包含文本和图像的数学、物理问题,提供难度分级和详细解答,来评估模型的推理能力。
- 实验结果表明,现有模型在复杂推理和视觉-文本整合方面存在明显不足,为未来研究指明方向。
📝 摘要(中文)
本文提出了MMSciBench,一个用于评估大型语言模型(LLMs)和视觉-语言模型(LVLMs)在数学和物理推理能力上的基准。该基准包含纯文本和文本-图像两种格式的问题,并提供人工标注的难度等级、带有详细解释的解答以及分类映射。对现有最佳模型的评估结果表明,模型在科学推理方面存在显著局限性,即使是表现最好的模型也仅达到63.77%的准确率,尤其是在视觉推理任务上表现不佳。分析揭示了模型在复杂推理和视觉-文本整合方面的关键差距。MMSciBench旨在成为衡量多模态科学理解进展的严格标准。该基准的代码已在GitHub上开源,数据集可在Hugging Face上获取。
🔬 方法详解
问题定义:论文旨在解决现有大型语言模型(LLMs)和视觉-语言模型(LVLMs)在中文多模态科学问题上的推理能力评估问题。现有方法缺乏一个专门针对中文科学领域、同时包含文本和图像信息的综合性评测基准,难以准确衡量模型在理解和解决复杂科学问题方面的能力。
核心思路:论文的核心思路是构建一个高质量、多样化的中文多模态科学问题数据集,并设计相应的评估指标,从而全面评估LLMs和LVLMs在科学推理方面的能力。通过分析模型在不同难度级别和不同类型问题上的表现,揭示模型在科学理解方面的优势和不足。
技术框架:MMSciBench包含以下几个主要组成部分:1) 问题收集与标注:收集涵盖数学和物理领域的科学问题,并标注难度等级和详细解答;2) 多模态数据构建:将问题转化为纯文本和文本-图像两种格式,以评估模型在不同模态下的推理能力;3) 模型评估:使用现有LLMs和LVLMs在MMSciBench上进行评估,并分析模型的性能表现;4) 错误分析:对模型的错误进行分类和分析,揭示模型在科学理解方面的局限性。
关键创新:MMSciBench的关键创新在于:1) 它是首个专门针对中文多模态科学问题的评测基准;2) 它提供了人工标注的难度等级和详细解答,方便研究人员进行深入分析;3) 它包含了纯文本和文本-图像两种格式的问题,可以全面评估模型在不同模态下的推理能力。
关键设计:数据集包含数学和物理领域的题目,难度分级由人工标注完成。评估指标包括准确率等。具体模型选择和训练细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
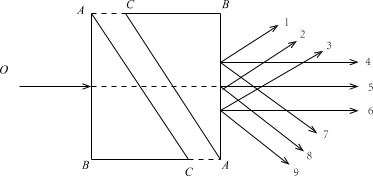
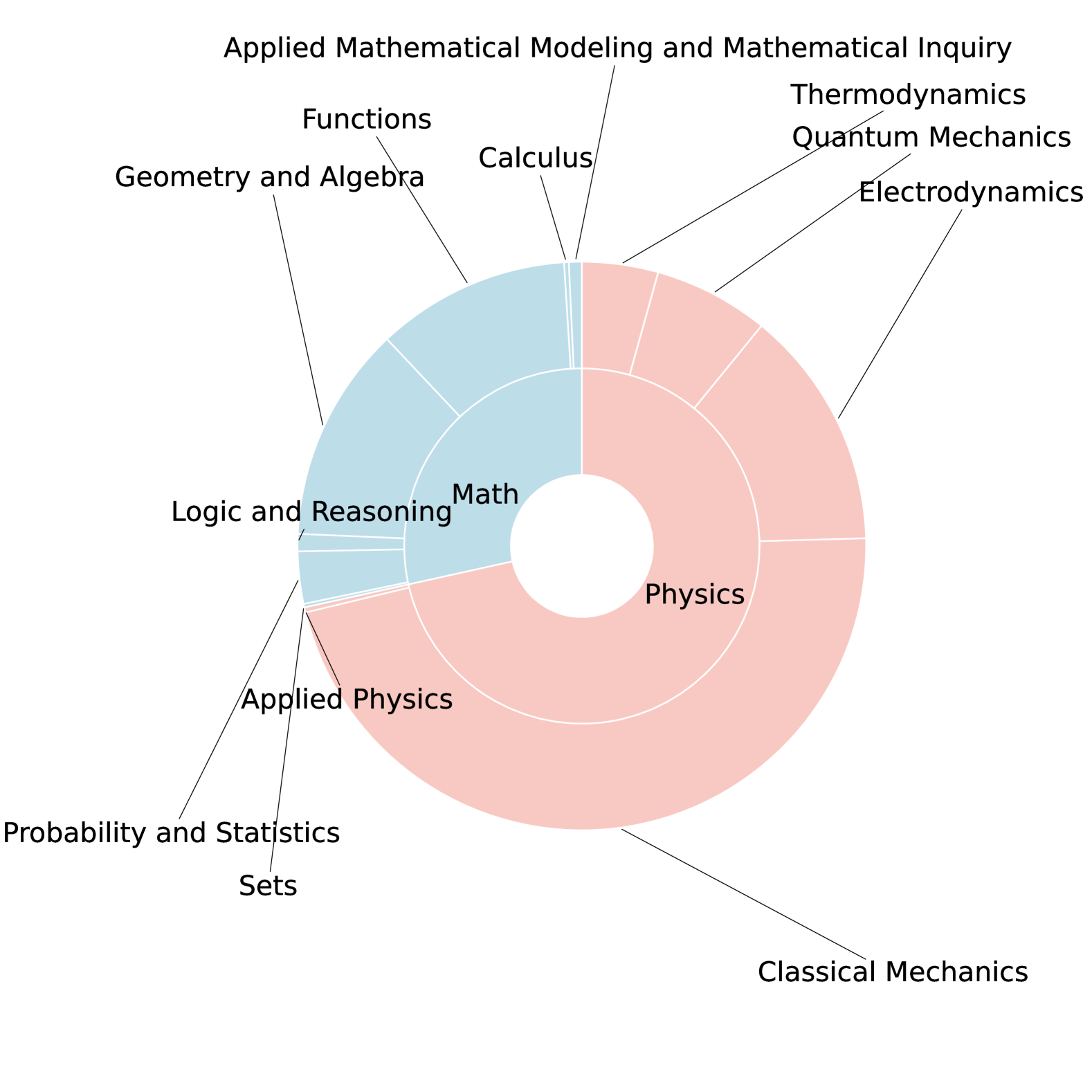
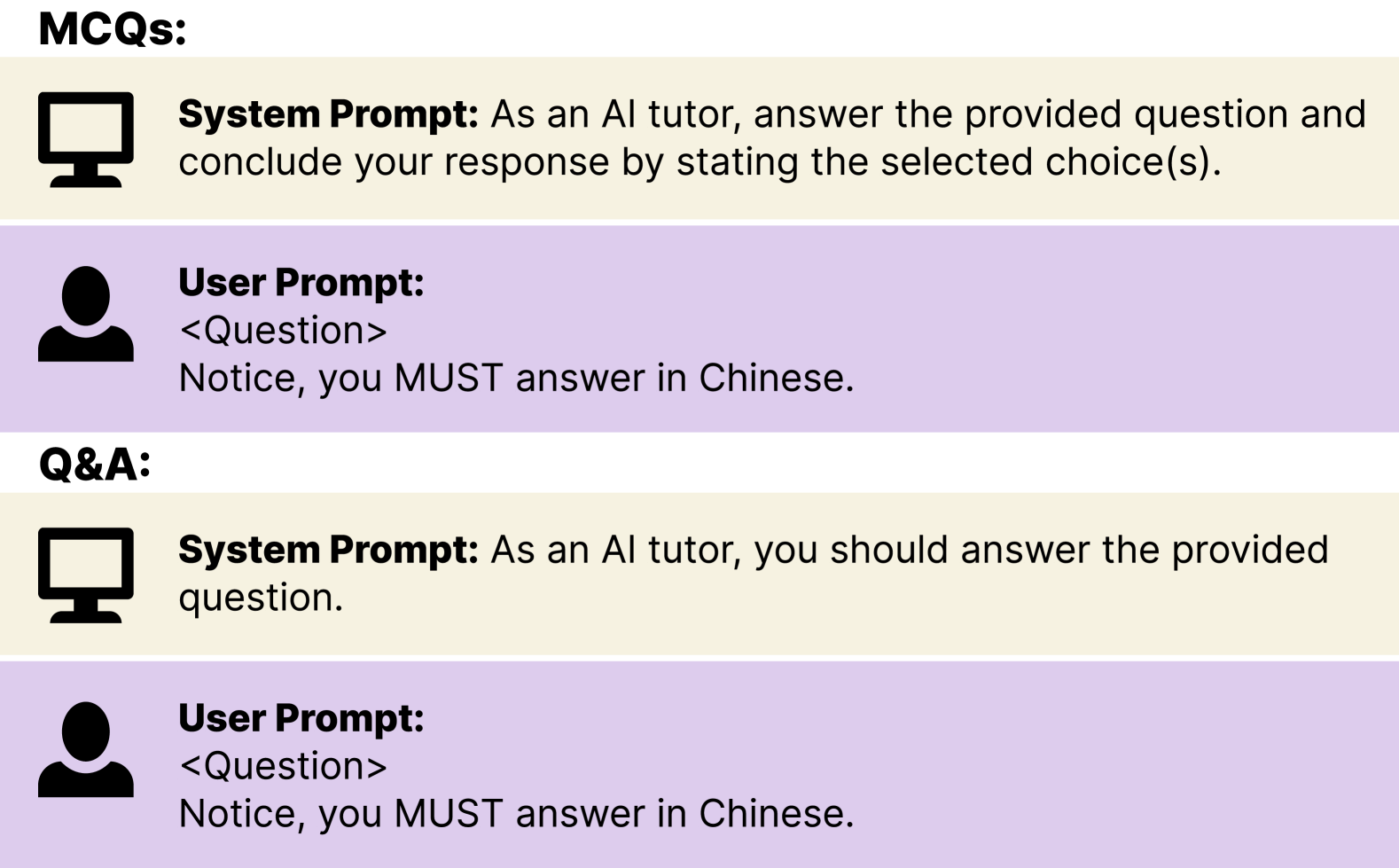
📊 实验亮点
实验结果表明,即使是当前最先进的模型在MMSciBench上的准确率也仅为63.77%,尤其是在视觉推理任务上表现不佳。这表明现有模型在复杂推理和视觉-文本整合方面存在显著差距,为未来的研究提供了明确的方向。
🎯 应用场景
MMSciBench可用于评估和提升大型语言模型在科学教育、智能辅导、科研助手等领域的应用能力。通过该基准,研究人员可以更好地了解模型的科学推理能力,并开发更有效的模型和算法,从而推动人工智能在科学领域的应用。
📄 摘要(原文)
Recent advances in large language models (LLMs) and vision-language models (LVLMs) have shown promise across many tasks, yet their scientific reasoning capabilities remain untested, particularly in multimodal settings. We present MMSciBench, a benchmark for evaluating mathematical and physical reasoning through text-only and text-image formats, with human-annotated difficulty levels, solutions with detailed explanations, and taxonomic mappings. Evaluation of state-of-the-art models reveals significant limitations, with even the best model achieving only \textbf{63.77\%} accuracy and particularly struggling with visual reasoning tasks. Our analysis exposes critical gaps in complex reasoning and visual-textual integration, establishing MMSciBench as a rigorous standard for measuring progress in multimodal scientific understanding. The code for MMSciBench is open-sourced at GitHub, and the dataset is available at Hugging Face.