When Continue Learning Meets Multimodal Large Language Model: A Survey
作者: Yukang Huo, Hao Tang
分类: cs.LG, cs.AI
发布日期: 2025-02-27
备注: 42 pages, 6 figures, 37 tables
💡 一句话要点
综述多模态大语言模型持续学习,应对灾难性遗忘难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 持续学习 灾难性遗忘 模型微调 知识保留
📋 核心要点
- 现有MLLM在适应动态数据和新任务时,微调易导致灾难性遗忘,损失模型原有知识。
- 该综述系统性地分析了MLLM持续学习的研究现状,连接了理论、方法和应用。
- 论文总结了MLLM持续学习的挑战和未来方向,旨在激发该领域的研究和发展。
📝 摘要(中文)
人工智能的最新进展推动了多模态大语言模型(MLLM)的发展。然而,如何有效地使这些预训练模型适应动态数据分布和各种任务仍然是一个挑战。针对特定任务微调MLLM通常会导致模型先前知识领域的性能下降,这个问题被称为“灾难性遗忘”。虽然这个问题在持续学习(CL)领域已经得到了充分的研究,但它给MLLM带来了新的挑战。这篇综述论文是MLLM持续学习领域的首篇,概述并分析了该领域的440篇研究论文。该综述分为四个部分。首先,讨论了MLLM的最新研究,涵盖了模型创新、基准测试以及在各个领域的应用。其次,对持续学习的最新研究进行了分类和概述,分为三个部分:非大语言模型单模态持续学习(Non-LLM Unimodal CL)、非大语言模型多模态持续学习(Non-LLM Multimodal CL)以及大语言模型中的持续学习(CL in LLM)。第三部分详细分析了当前MLLM持续学习研究的现状,包括基准评估、架构创新以及理论和实证研究的总结。最后,讨论了MLLM中持续学习的挑战和未来方向,旨在激发未来在该领域的研究和发展。本综述将多模态大型模型的持续学习的基础概念、理论见解、方法创新和实际应用联系起来,全面理解该领域的研究进展和挑战,旨在激发该领域的研究人员并促进相关技术的进步。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在持续学习过程中遇到的灾难性遗忘问题。现有方法在针对特定任务微调MLLM时,往往会损害模型在先前知识领域的性能,导致模型忘记已经学习过的知识。这种现象严重限制了MLLM在实际应用中的适应性和泛化能力。
核心思路:论文的核心思路是对现有的MLLM持续学习研究进行全面的梳理和分析,从模型创新、基准测试、理论研究和实际应用等多个维度,总结该领域的研究进展、挑战和未来方向。通过连接持续学习的基础概念、理论见解、方法创新和实际应用,为研究人员提供一个全面的理解框架,从而激发新的研究思路。
技术框架:该综述论文的技术框架主要包含以下几个部分: 1. MLLM研究现状:概述MLLM的模型创新、基准测试和应用领域。 2. 持续学习研究分类:将持续学习研究分为非大语言模型单模态持续学习、非大语言模型多模态持续学习以及大语言模型中的持续学习三个类别。 3. MLLM持续学习分析:详细分析当前MLLM持续学习研究的现状,包括基准评估、架构创新以及理论和实证研究的总结。 4. 未来方向展望:讨论MLLM持续学习的挑战和未来方向。
关键创新:该论文的关键创新在于它是第一篇专门针对MLLM持续学习的综述论文。它系统性地整理和分析了该领域的研究成果,为研究人员提供了一个全面的视角,有助于他们更好地理解该领域的研究现状和发展趋势。此外,该综述还指出了MLLM持续学习领域面临的挑战和未来的研究方向,为未来的研究提供了指导。
关键设计:该综述的关键设计在于其结构化的组织方式,将MLLM、持续学习和MLLM持续学习三个主题有机地结合在一起。通过对不同类别的持续学习方法进行分类和比较,该综述能够更清晰地展示各种方法的优缺点和适用场景。此外,该综述还关注了MLLM持续学习的基准评估和架构创新,为研究人员提供了有价值的参考信息。
🖼️ 关键图片

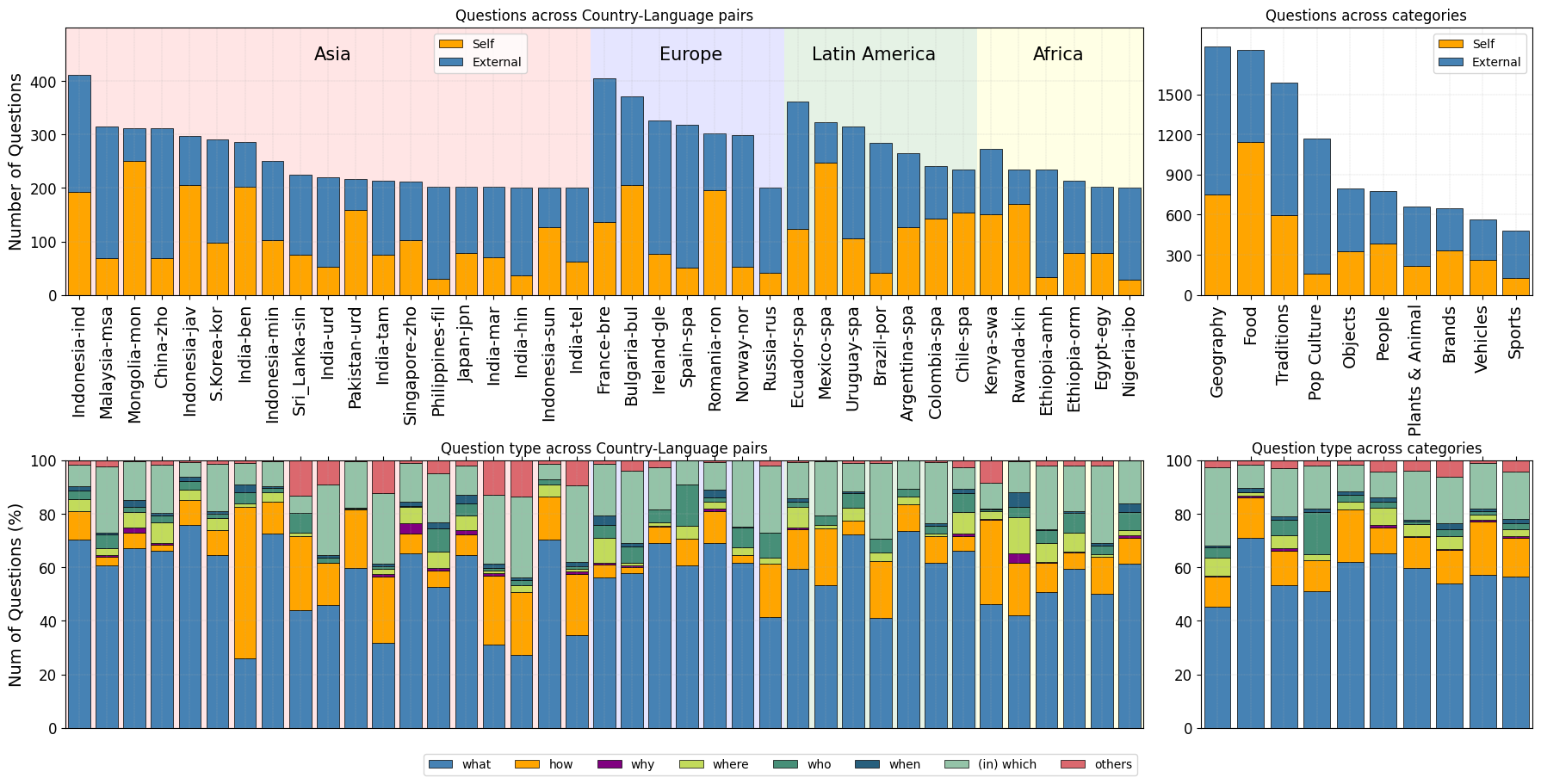
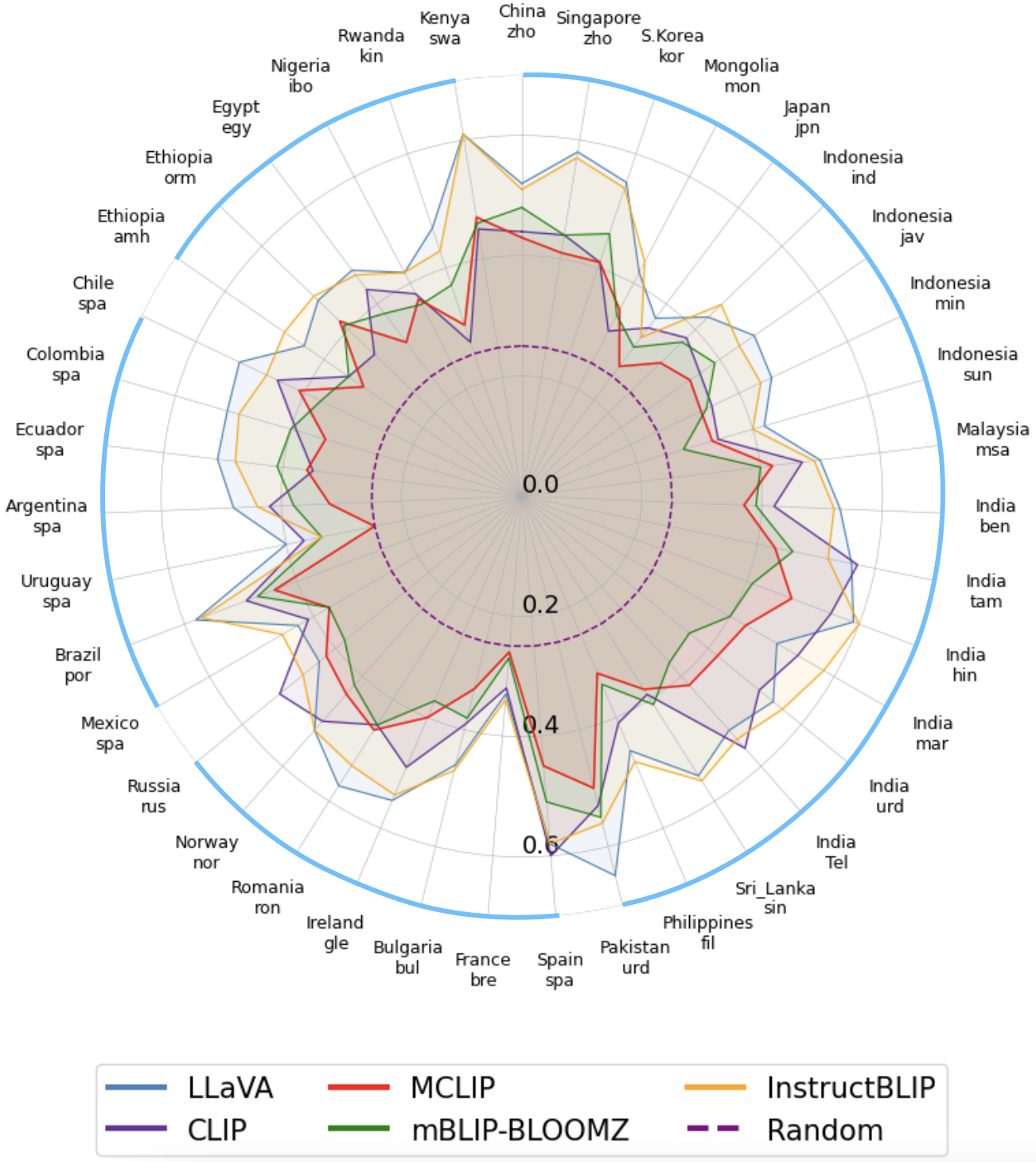
📊 实验亮点
该综述分析了440篇相关论文,全面梳理了MLLM持续学习领域的研究进展。总结了现有方法在基准测试上的表现,并对各种架构创新进行了比较分析。该综述还指出了MLLM持续学习领域面临的挑战和未来的研究方向,为未来的研究提供了重要的参考。
🎯 应用场景
该研究对多模态大语言模型在需要持续学习的场景中具有重要应用价值,例如智能客服、自动驾驶、医疗诊断等领域。通过解决灾难性遗忘问题,可以使模型在不断学习新知识的同时,保持对原有知识的掌握,从而提高模型的性能和可靠性。未来的影响在于推动通用人工智能的发展,使机器能够像人类一样持续学习和适应环境。
📄 摘要(原文)
Recent advancements in Artificial Intelligence have led to the development of Multimodal Large Language Models (MLLMs). However, adapting these pre-trained models to dynamic data distributions and various tasks efficiently remains a challenge. Fine-tuning MLLMs for specific tasks often causes performance degradation in the model's prior knowledge domain, a problem known as 'Catastrophic Forgetting'. While this issue has been well-studied in the Continual Learning (CL) community, it presents new challenges for MLLMs. This review paper, the first of its kind in MLLM continual learning, presents an overview and analysis of 440 research papers in this area.The review is structured into four sections. First, it discusses the latest research on MLLMs, covering model innovations, benchmarks, and applications in various fields. Second, it categorizes and overviews the latest studies on continual learning, divided into three parts: non-large language models unimodal continual learning (Non-LLM Unimodal CL), non-large language models multimodal continual learning (Non-LLM Multimodal CL), and continual learning in large language models (CL in LLM). The third section provides a detailed analysis of the current state of MLLM continual learning research, including benchmark evaluations, architectural innovations, and a summary of theoretical and empirical studies.Finally, the paper discusses the challenges and future directions of continual learning in MLLMs, aiming to inspire future research and development in the field. This review connects the foundational concepts, theoretical insights, method innovations, and practical applications of continual learning for multimodal large models, providing a comprehensive understanding of the research progress and challenges in this field, aiming to inspire researchers in the field and promote the advancement of related technologies.