RIZE: Adaptive Regularization for Imitation Learning
作者: Adib Karimi, Mohammad Mehdi Ebadzadeh
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-02-27 (更新: 2025-11-19)
备注: Camera-ready version. Published in Transactions on Machine Learning Research (2025). Official version: https://openreview.net/forum?id=a6DWqXJZCZ
期刊: Transactions on Machine Learning Research (11/2025)
🔗 代码/项目: GITHUB
💡 一句话要点
RIZE:基于自适应正则化的模仿学习方法,提升复杂环境下的决策鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 逆强化学习 自适应正则化 时序差分学习 分布强化学习
📋 核心要点
- 现有模仿学习方法在奖励函数设计上存在局限性,要么过于固定,要么缺乏灵活性,难以适应复杂环境。
- RIZE通过引入自适应TD正则化器,动态调整奖励边界,增强了模型对环境变化的适应能力和决策的鲁棒性。
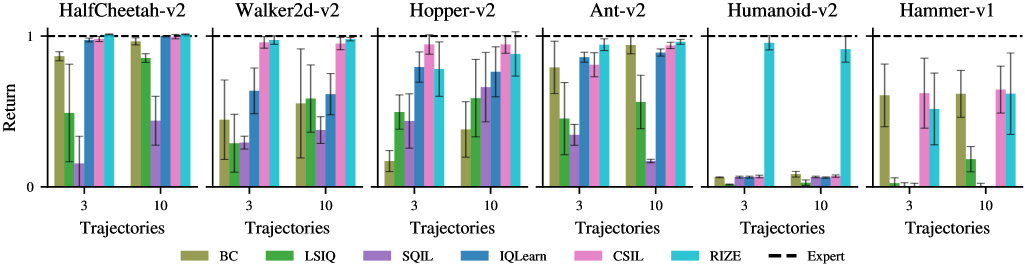
- 实验表明,RIZE在MuJoCo和Adroit等复杂环境中表现出色,尤其是在Humanoid-v2任务上超越了现有基线方法。
📝 摘要(中文)
本文提出了一种新颖的逆强化学习(IRL)方法,旨在缓解固定奖励结构的僵化性和隐式奖励正则化有限的灵活性。该方法基于最大熵IRL框架,并结合了具有自适应目标的平方时序差分(TD)正则化器,这些目标在训练过程中动态演变,从而对恢复的奖励施加自适应边界,并促进稳健的决策。为了捕获更丰富的回报信息,我们将分布强化学习集成到学习过程中。实验结果表明,我们的方法在复杂的MuJoCo和Adroit环境中实现了专家级的性能,在使用有限的专家演示的情况下,在Humanoid-v2任务上超越了基线方法。大量的实验和消融研究进一步验证了该方法的有效性,并提供了对模仿学习中奖励动态的深入了解。源代码可在https://github.com/adibka/RIZE 获取。
🔬 方法详解
问题定义:传统的逆强化学习方法通常依赖于固定的奖励函数或隐式的奖励正则化,这限制了它们在复杂环境中的表现。固定的奖励函数可能无法捕捉到专家行为的细微差别,而隐式正则化则缺乏足够的灵活性来适应不同的任务需求。因此,如何设计一种能够动态适应环境变化并有效学习专家策略的奖励函数是当前面临的关键问题。
核心思路:RIZE的核心思路是引入一个自适应的奖励正则化器,该正则化器基于时序差分(TD)误差的平方,并具有动态调整的目标值。通过在训练过程中不断更新这些目标值,RIZE能够对恢复的奖励函数施加自适应的约束,从而避免奖励函数过于僵化或缺乏灵活性。这种自适应的正则化机制使得模型能够更好地学习专家策略,并在复杂环境中做出更稳健的决策。
技术框架:RIZE建立在最大熵逆强化学习(Maximum Entropy IRL)框架之上。其主要流程包括:1) 从专家演示数据中学习奖励函数;2) 使用学习到的奖励函数训练策略;3) 计算TD误差并更新自适应目标值;4) 使用更新后的目标值对奖励函数进行正则化。该框架通过迭代执行这些步骤,不断优化奖励函数和策略,最终实现模仿学习的目标。此外,为了捕获更丰富的回报信息,RIZE还集成了分布强化学习,从而能够更准确地估计状态-动作价值函数。
关键创新:RIZE最重要的技术创新点在于其自适应的TD正则化器。与传统的固定正则化方法不同,RIZE的正则化目标值在训练过程中动态演变,从而能够更好地适应环境变化和任务需求。这种自适应的正则化机制使得模型能够学习到更准确、更鲁棒的奖励函数,并在复杂环境中做出更明智的决策。
关键设计:RIZE的关键设计包括:1) 使用平方TD误差作为正则化项,以惩罚与专家行为不一致的奖励函数;2) 使用指数移动平均(EMA)来更新自适应目标值,以平滑训练过程并提高稳定性;3) 将分布强化学习集成到学习过程中,以捕获更丰富的回报信息。此外,RIZE还采用了标准的神经网络结构来表示奖励函数和策略,并使用Adam优化器进行训练。
🖼️ 关键图片


📊 实验亮点
RIZE在Humanoid-v2任务上取得了显著的性能提升,在使用有限的专家演示的情况下,超越了现有的基线方法。具体来说,RIZE在MuJoCo和Adroit等复杂环境中实现了专家级的性能,证明了其在复杂环境下的有效性和鲁棒性。消融实验进一步验证了自适应TD正则化器的重要性,表明其对性能提升起到了关键作用。
🎯 应用场景
RIZE具有广泛的应用前景,例如机器人控制、自动驾驶、游戏AI等领域。它可以用于训练机器人完成复杂的任务,例如在拥挤的环境中导航或执行精细的操作。在自动驾驶领域,RIZE可以用于学习人类驾驶员的驾驶习惯,从而提高自动驾驶系统的安全性和舒适性。在游戏AI领域,RIZE可以用于训练AI玩家,使其能够模仿人类玩家的行为,从而提高游戏的趣味性和挑战性。
📄 摘要(原文)
We propose a novel Inverse Reinforcement Learning (IRL) method that mitigates the rigidity of fixed reward structures and the limited flexibility of implicit reward regularization. Building on the Maximum Entropy IRL framework, our approach incorporates a squared temporal-difference (TD) regularizer with adaptive targets that evolve dynamically during training, thereby imposing adaptive bounds on recovered rewards and promoting robust decision-making. To capture richer return information, we integrate distributional RL into the learning process. Empirically, our method achieves expert-level performance on complex MuJoCo and Adroit environments, surpassing baseline methods on the Humanoid-v2 task with limited expert demonstrations. Extensive experiments and ablation studies further validate the effectiveness of the approach and provide insights into reward dynamics in imitation learning. Our source code is available at https://github.com/adibka/RIZE.