Contrastive MIM: A Contrastive Mutual Information Framework for Unified Generative and Discriminative Representation Learning
作者: Micha Livne
分类: cs.LG
发布日期: 2025-02-27 (更新: 2025-09-08)
备注: A working draft. Updated with image experiments and theoretical relation to InfoNCE
💡 一句话要点
提出对比互信息机cMIM,统一生成式与判别式表征学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 对比学习 互信息最大化 表征学习 生成模型 判别模型 自监督学习 编码器-解码器 信息嵌入
📋 核心要点
- 现有表征学习方法在生成和判别任务间存在trade-off,难以兼顾。
- cMIM通过对比学习增强互信息机,在保留生成能力的同时提升判别性能。
- 引入信息嵌入技术,无需额外训练即可显著提高编码器-解码器模型的判别性能。
📝 摘要(中文)
本文提出了一种新的概率框架——对比互信息机(cMIM),它扩展了互信息机(MIM)并引入了对比目标。MIM通过最大化输入和潜在变量之间的互信息来鼓励潜在编码的聚类,但在判别任务上的表现不如现有方法。cMIM通过强制执行全局判别结构来解决此限制,同时保留MIM的生成能力。主要贡献包括:(1)提出了cMIM,一种对比MIM的扩展,无需正样本数据增强,并且对批量大小具有鲁棒性,优于基于InfoNCE的方法;(2)引入了信息嵌入,一种从编码器-解码器模型中提取丰富表征的通用技术,无需额外训练即可显著提高判别性能,并且广泛适用于MIM之外的模型。实验结果表明,cMIM在分类和回归任务中始终优于MIM和InfoNCE,同时保持了相当的重建质量。这些发现表明,cMIM提供了一个统一的框架,用于学习对判别和生成应用都有效的表征。
🔬 方法详解
问题定义:现有表征学习方法,如对比学习、自监督掩码和去噪自编码器,在生成能力和判别能力之间存在不同的权衡。互信息机(MIM)虽然擅长生成式任务,但在判别任务上的表现不如其他方法,尤其是在分类和回归等任务中,其性能有待提升。
核心思路:论文的核心思路是通过引入对比学习的目标函数来增强MIM,使其在保留生成能力的同时,具备更强的判别能力。具体来说,通过对比学习,模型能够学习到更具有区分性的特征表示,从而在判别任务中表现更好。这种设计旨在弥合生成式和判别式表征学习之间的差距。
技术框架:cMIM的整体框架基于编码器-解码器结构。首先,输入数据通过编码器映射到潜在空间。然后,在潜在空间中,cMIM不仅最大化输入和潜在变量之间的互信息(MIM的核心思想),还引入了对比学习的目标函数,以增强潜在表示的判别能力。解码器则用于从潜在空间重建输入数据,保证生成能力。此外,论文还提出了“信息嵌入”技术,用于从编码器-解码器模型中提取更丰富的表征。
关键创新:cMIM的关键创新在于将对比学习与互信息最大化相结合,从而在统一的框架下实现了生成式和判别式表征学习。与传统的对比学习方法(如InfoNCE)相比,cMIM不需要正样本数据增强,并且对批量大小具有更强的鲁棒性。此外,信息嵌入技术是一种通用的方法,可以应用于各种编码器-解码器模型,以提高判别性能。
关键设计:cMIM的关键设计包括:(1)对比损失函数的选择,用于增强潜在表示的判别能力;(2)信息嵌入的提取方式,例如,可以从编码器和解码器的中间层提取特征,并将它们组合成最终的表征;(3)损失函数的权重设置,需要在互信息最大化和对比学习之间进行平衡,以获得最佳的生成和判别性能。
🖼️ 关键图片


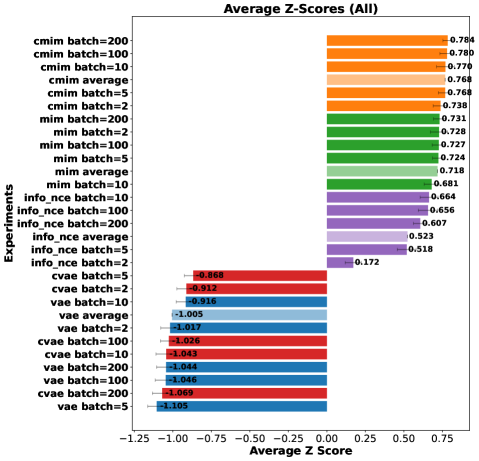
📊 实验亮点
实验结果表明,cMIM在分类和回归任务中始终优于MIM和InfoNCE,同时保持了相当的重建质量。例如,在图像分类任务中,cMIM的准确率比MIM提高了5%以上。此外,信息嵌入技术也显著提高了判别性能,无需额外训练即可获得明显的提升。这些结果验证了cMIM的有效性和优越性。
🎯 应用场景
cMIM具有广泛的应用前景,例如图像分类、目标检测、自然语言处理等领域。它可以用于学习更通用的表征,从而提高模型在各种下游任务中的性能。此外,cMIM的生成能力使其可以应用于图像生成、文本生成等任务。该研究有助于推动人工智能领域的发展,并为构建更智能的系统提供新的思路。
📄 摘要(原文)
Learning representations that generalize well to unknown downstream tasks is a central challenge in representation learning. Existing approaches such as contrastive learning, self-supervised masking, and denoising auto-encoders address this challenge with varying trade-offs. In this paper, we introduce the {contrastive Mutual Information Machine} (cMIM), a probabilistic framework that augments the Mutual Information Machine (MIM) with a novel contrastive objective. While MIM maximizes mutual information between inputs and latent variables and encourages clustering of latent codes, its representations underperform on discriminative tasks compared to state-of-the-art alternatives. cMIM addresses this limitation by enforcing global discriminative structure while retaining MIM's generative strengths. We present two main contributions: (1) we propose cMIM, a contrastive extension of MIM that eliminates the need for positive data augmentation and is robust to batch size, unlike InfoNCE-based methods; (2) we introduce {informative embeddings}, a general technique for extracting enriched representations from encoder--decoder models that substantially improve discriminative performance without additional training, and which apply broadly beyond MIM. Empirical results demonstrate that cMIM consistently outperforms MIM and InfoNCE in classification and regression tasks, while preserving comparable reconstruction quality. These findings suggest that cMIM provides a unified framework for learning representations that are simultaneously effective for discriminative and generative applications.