CodeIF: Benchmarking the Instruction-Following Capabilities of Large Language Models for Code Generation
作者: Kaiwen Yan, Hongcheng Guo, Xuanqing Shi, Shaosheng Cao, Donglin Di, Zhoujun Li
分类: cs.SE, cs.LG
发布日期: 2025-02-26 (更新: 2025-08-04)
备注: Accepted as an ACL 2025 Industry Track paper (15 pages)
🔗 代码/项目: GITHUB
💡 一句话要点
CodeIF:首个面向代码生成任务,评估大语言模型指令遵循能力的基准评测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 指令遵循 基准评测 软件工程
📋 核心要点
- 现有代码生成模型在遵循复杂、多样的指令方面存在不足,难以满足实际软件开发需求。
- CodeIF基准旨在全面评估LLMs在函数合成、调试、重构和解释等任务中的指令遵循能力。
- 实验结果揭示了现有LLMs在代码生成中指令遵循的优势与局限性,为未来研究指明方向。
📝 摘要(中文)
随着大型语言模型(LLMs)的快速发展,代码生成任务中对鲁棒的指令遵循能力的需求显著增长。代码生成不仅促进了更快的原型设计和自动化测试,还通过改进代码的可维护性和可重用性来提高开发人员的效率。本文提出了CodeIF,这是第一个专门用于评估LLMs在各种代码生成场景中遵循面向任务的指令能力的基准。CodeIF涵盖了广泛的任务,包括函数合成、错误调试、算法重构和代码解释,从而提供了一个全面的套件来评估模型在不同复杂程度和编程领域中的性能。我们使用LLMs进行了广泛的实验,分析了它们在满足这些任务需求方面的优势和局限性。实验结果为当前模型与人类指令的对齐程度,以及它们生成一致、可维护和上下文相关的代码的能力提供了有价值的见解。我们的发现不仅强调了指令遵循LLMs在现代软件开发中可以发挥的关键作用,而且阐明了未来研究的途径,旨在提高它们在自动化代码生成中的适应性、可靠性和整体有效性。
🔬 方法详解
问题定义:现有的大型语言模型在代码生成任务中,虽然表现出了强大的生成能力,但在理解和严格遵循复杂、多样的指令方面仍然存在不足。这导致生成的代码可能不符合预期,难以维护和复用。现有的代码生成评测基准往往侧重于代码的正确性,而忽略了模型对指令的理解和执行能力。
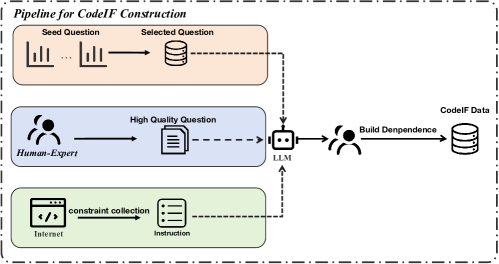
核心思路:CodeIF的核心思路是构建一个包含多种代码生成任务的基准,这些任务需要模型具备良好的指令遵循能力。通过评估模型在这些任务上的表现,可以更全面地了解模型在代码生成方面的能力,并为未来的研究提供指导。
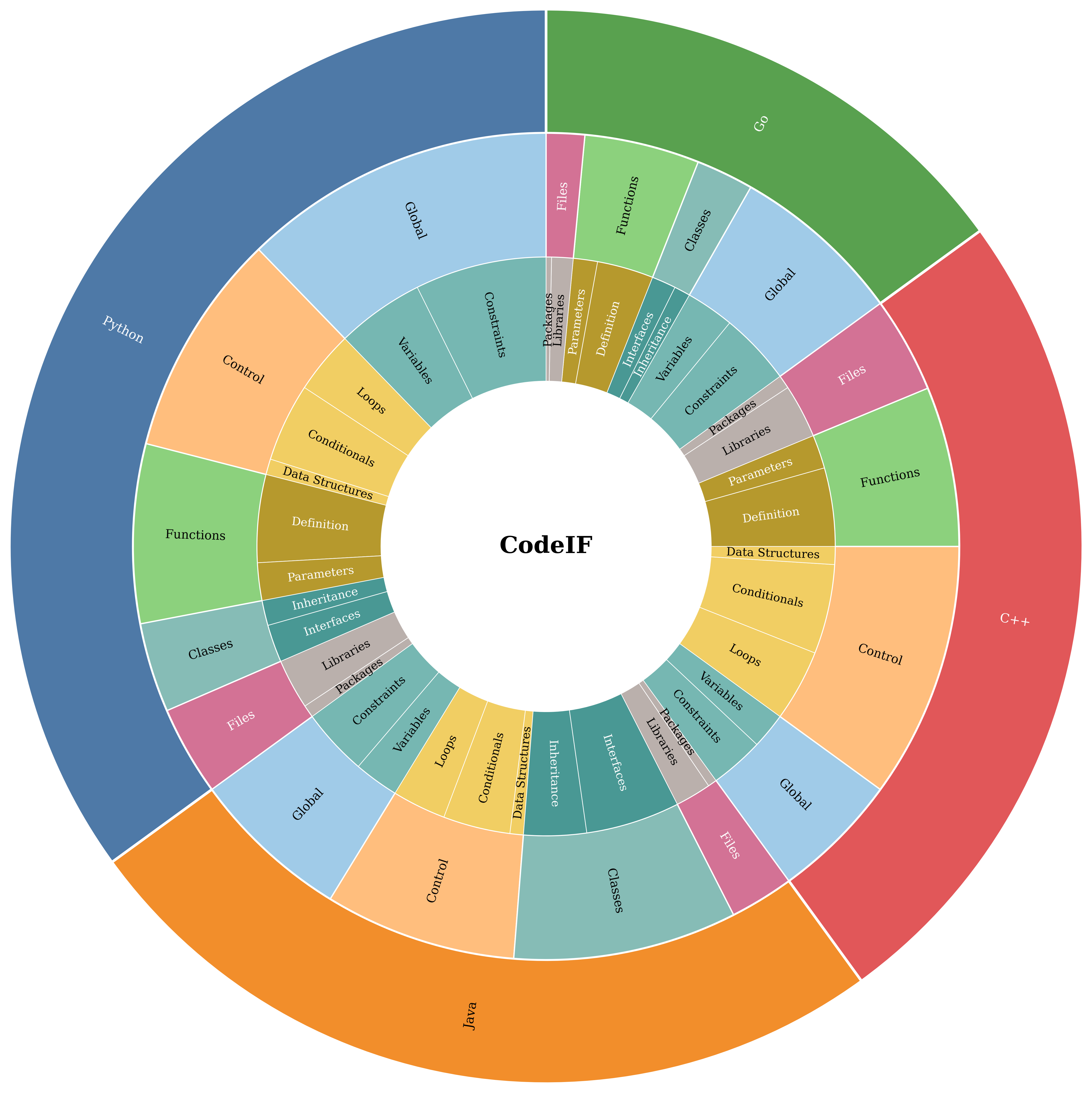
技术框架:CodeIF基准包含四个主要任务:函数合成(Function Synthesis)、错误调试(Error Debugging)、算法重构(Algorithmic Refactoring)和代码解释(Code Explanation)。每个任务都包含多个测试用例,每个用例都包含一段代码和一个或多个指令。模型需要根据指令生成相应的代码或解释。
关键创新:CodeIF的关键创新在于其专注于评估模型在代码生成任务中的指令遵循能力。与现有的代码生成评测基准相比,CodeIF更加注重模型对指令的理解和执行,而不仅仅是代码的正确性。此外,CodeIF还涵盖了多种不同的代码生成任务,可以更全面地评估模型的代码生成能力。
关键设计:CodeIF中的每个任务都经过精心设计,以确保其能够有效地评估模型的指令遵循能力。例如,在函数合成任务中,指令可能包含函数的功能描述、输入输出示例等信息。在错误调试任务中,指令可能包含错误的描述、错误的位置等信息。这些指令的设计旨在考察模型对指令的理解和推理能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有LLMs在CodeIF基准上的表现参差不齐,部分模型在特定任务上表现出色,但在其他任务上则表现较差。这表明现有模型在指令遵循能力方面仍有很大的提升空间。CodeIF的发布将促进相关研究,推动LLMs在代码生成领域的应用。
🎯 应用场景
CodeIF的研究成果可应用于自动化代码生成、智能编程助手、代码质量评估等领域。通过提升LLMs的指令遵循能力,可以显著提高软件开发的效率和质量,降低开发成本。未来,该研究有望推动软件工程领域的智能化发展。
📄 摘要(原文)
With the rapid advancement of Large Language Models (LLMs), the demand for robust instruction-following capabilities in code generation tasks has grown significantly. Code generation not only facilitates faster prototyping and automated testing, but also augments developer efficiency through improved maintainability and reusability of code. In this paper, we introduce CodeIF, the first benchmark specifically designed to assess the abilities of LLMs to adhere to task-oriented instructions within diverse code generation scenarios. CodeIF encompasses a broad range of tasks, including function synthesis, error debugging, algorithmic refactoring, and code explanation, thereby providing a comprehensive suite to evaluate model performance across varying complexity levels and programming domains. We conduct extensive experiments with LLMs, analyzing their strengths and limitations in meeting the demands of these tasks. The experimental results offer valuable insights into how well current models align with human instructions, as well as the extent to which they can generate consistent, maintainable, and contextually relevant code. Our findings not only underscore the critical role that instruction-following LLMs can play in modern software development, but also illuminate pathways for future research aimed at enhancing their adaptability, reliability, and overall effectiveness in automated code generation. CodeIF data and code are publicly available: https://github.com/lin-rany/codeIF