The Sharpness Disparity Principle in Transformers for Accelerating Language Model Pre-Training
作者: Jinbo Wang, Mingze Wang, Zhanpeng Zhou, Junchi Yan, Weinan E, Lei Wu
分类: cs.LG, cs.AI, math.OC, stat.ML
发布日期: 2025-02-26 (更新: 2025-06-13)
备注: 21 pages, accepted by ICML 2025
💡 一句话要点
揭示Transformer块间Sharpness Disparity,提出Blockwise LR加速大语言模型预训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 预训练 Sharpness Disparity Blockwise Learning Rate 优化算法 Transformer 模型加速
📋 核心要点
- 现有Transformer训练方法忽略了不同模块间Sharpness的差异,导致训练效率低下。
- 论文提出Blockwise LR策略,根据各模块Sharpness自适应调整学习率,优化训练过程。
- 实验表明,Blockwise LR在多种模型和数据集上实现了近2倍的加速,并降低了终端损失。
📝 摘要(中文)
Transformer由嵌入层、归一化层、自注意力机制和前馈网络等多种构建块组成。本文揭示了这些块之间存在明显的Sharpness Disparity,这种差异在训练早期出现,并持续存在于整个训练过程中。受此发现的启发,我们提出了一种Blockwise Learning Rate (LR)策略,该策略根据每个块的sharpness调整LR,从而加速大型语言模型(LLM)的预训练。通过将Blockwise LR集成到AdamW中,与vanilla AdamW相比,我们始终能够获得更低的终端损失和近2倍的加速。我们在GPT-2和LLaMA上验证了这种加速效果,模型大小从0.12B到2B,数据集包括OpenWebText、MiniPile和C4。最后,我们将Blockwise LR集成到Adam-mini中,这是一种最近提出的内存高效的Adam变体,实现了2倍的加速和2倍的内存节省。这些结果突出了利用sharpness disparity来改进LLM训练的潜力。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)预训练方法通常对Transformer中的所有模块使用相同的学习率,忽略了不同模块在训练过程中可能具有不同的Sharpness。这种一刀切的方法可能导致训练效率低下,因为某些模块可能需要更小或更大的学习率才能达到最佳性能。现有方法的痛点在于无法充分利用Transformer内部结构的多样性,从而限制了训练速度和最终模型性能。
核心思路:论文的核心思路是观察到Transformer的不同模块(如嵌入层、归一化层、自注意力机制和前馈网络)在训练过程中表现出显著的Sharpness Disparity。基于此,论文提出为每个模块单独设置学习率,即Blockwise Learning Rate (LR)。通过根据每个模块的Sharpness自适应地调整学习率,可以更有效地优化模型参数,从而加速训练过程并提高模型性能。
技术框架:该方法的核心在于计算和利用Transformer各个模块的Sharpness信息。整体流程如下:1) 在训练过程中,周期性地估计每个模块的Sharpness;2) 根据估计的Sharpness,为每个模块设置相应的学习率;3) 使用调整后的学习率进行模型参数更新。该方法可以与现有的优化器(如AdamW和Adam-mini)相结合,形成Blockwise AdamW和Blockwise Adam-mini等变体。
关键创新:最重要的技术创新点在于发现了Transformer块间的Sharpness Disparity现象,并提出了Blockwise LR策略来利用这一现象。与现有方法相比,Blockwise LR能够更精细地控制每个模块的学习率,从而实现更高效的训练。这种方法的核心在于对Transformer内部结构差异性的深刻理解和有效利用。
关键设计:关键设计包括:1) Sharpness的估计方法(具体方法未知,论文中可能未详细描述);2) 如何根据Sharpness确定每个模块的学习率(例如,可以使用一个简单的线性或非线性映射);3) 调整学习率的频率(例如,每隔几个epoch或step调整一次)。此外,如何将Blockwise LR有效地集成到现有的优化器中也是一个关键的设计考虑因素。
🖼️ 关键图片
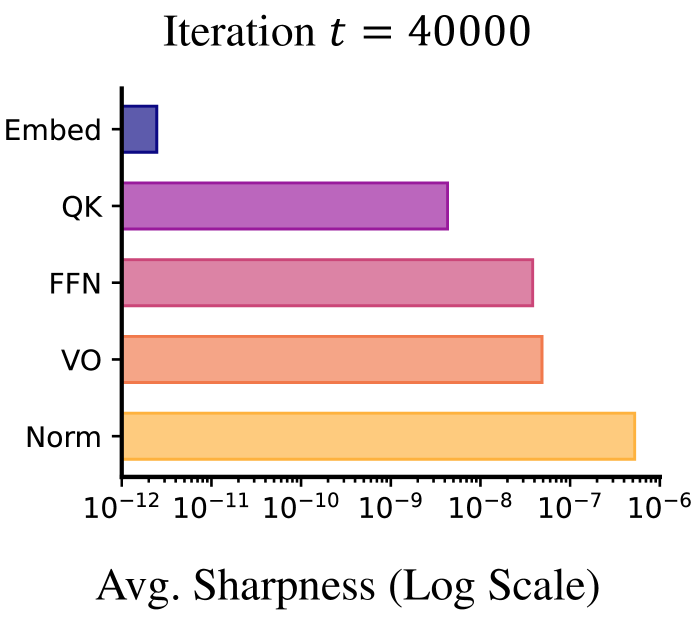
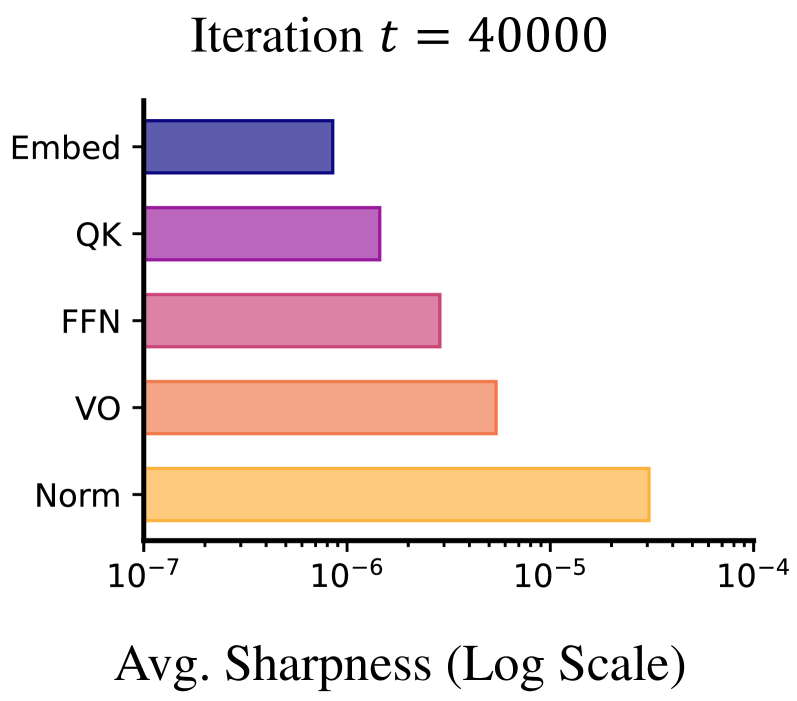

📊 实验亮点
实验结果表明,Blockwise LR在GPT-2和LLaMA等模型上实现了近2倍的加速,并降低了终端损失。例如,在2B参数的LLaMA模型上,使用Blockwise LR的AdamW相比于vanilla AdamW,能够更快地达到相同的性能水平。此外,Blockwise LR与Adam-mini结合使用,实现了2倍的加速和2倍的内存节省,进一步提升了训练效率。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的预训练,尤其是在计算资源有限的情况下,能够显著加速训练过程,降低训练成本。此外,该方法也可能推广到其他深度学习模型,通过利用模型内部结构的多样性来提高训练效率和模型性能。未来,该研究可能促进更高效、更经济的大语言模型训练方法的发展。
📄 摘要(原文)
Transformers consist of diverse building blocks, such as embedding layers, normalization layers, self-attention mechanisms, and point-wise feedforward networks. Thus, understanding the differences and interactions among these blocks is important. In this paper, we uncover a clear Sharpness Disparity across these blocks, which emerges early in training and intriguingly persists throughout the training process. Motivated by this finding, we propose Blockwise Learning Rate (LR), a strategy that tailors the LR to each block's sharpness, accelerating large language model (LLM) pre-training. By integrating Blockwise LR into AdamW, we consistently achieve lower terminal loss and nearly $2\times$ speedup compared to vanilla AdamW. We demonstrate this acceleration across GPT-2 and LLaMA, with model sizes ranging from 0.12B to 2B and datasets of OpenWebText, MiniPile, and C4. Finally, we incorporate Blockwise LR into Adam-mini (Zhang et al., 2024), a recently proposed memory-efficient variant of Adam, achieving a combined $2\times$ speedup and $2\times$ memory saving. These results underscore the potential of exploiting the sharpness disparity to improve LLM training.