(Mis)Fitting: A Survey of Scaling Laws
作者: Margaret Li, Sneha Kudugunta, Luke Zettlemoyer
分类: cs.LG, cs.AI, cs.CL, stat.ME
发布日期: 2025-02-26
备注: 41 pages, 3 figure, first two authors contributed equally. ICLR, 2025
💡 一句话要点
揭示缩放定律拟合中的偏差:一项关于缩放定律的综述研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 缩放定律 基础模型 模型训练 超参数优化 实验复现 文献综述 偏差分析
📋 核心要点
- 现有基础模型训练依赖缩放定律,但不同研究在公式、训练设置和优化方法上存在差异,导致结论不一致。
- 该研究深入分析了这些差异对缩放研究结论的影响,并探讨了特定细节变化如何改变研究结果。
- 通过对50多篇论文的调查,发现多数论文未充分报告关键细节,并提出了作者在缩放定律研究中应考虑的清单。
📝 摘要(中文)
现代基础模型严重依赖缩放定律来指导关键的训练决策。研究人员通常通过描述损失或任务性能与规模之间的关系,从较小的训练运行中推断出最佳的架构和超参数设置。这个过程的各个组成部分都存在差异,从拟合的具体公式到训练设置再到优化方法。这些因素都可能影响拟合的定律,从而影响给定研究的结论。我们讨论了先前工作在诸如最佳token参数比等问题上得出的结论的差异。我们通过对特定细节变化可能在缩放研究中产生的影响以及由此产生的结论的改变进行分析来补充这一讨论。此外,我们调查了50多篇研究缩放趋势的论文:虽然其中45篇论文使用幂律来量化这些趋势,但大多数论文都未充分报告重现其发现所需的关键细节。为了缓解这种情况,我们为作者在为缩放定律研究做出贡献时应考虑的清单。
🔬 方法详解
问题定义:论文旨在解决缩放定律研究中结论不一致的问题。现有方法在拟合缩放定律时,由于公式选择、训练设置、优化方法等细节差异,导致对模型架构、超参数等关键决策的指导产生偏差。此外,现有研究在报告实验细节方面存在不足,难以复现。
核心思路:论文的核心思路是系统性地分析不同因素对缩放定律拟合的影响,并提供一个更全面的视角来理解和应用缩放定律。通过对比不同研究的结论,并进行额外的实验分析,揭示了细节差异如何导致结论差异。同时,提出了一个作者清单,旨在提高缩放定律研究的可复现性。
技术框架:该研究主要采用综述和实验分析相结合的方法。首先,对现有缩放定律研究进行广泛的文献调研,识别出不同研究在方法和结论上的差异。然后,通过实验分析,验证特定细节变化对缩放定律拟合结果的影响。最后,基于分析结果,提出了一个作者清单,用于指导未来的缩放定律研究。
关键创新:该研究的关键创新在于系统性地分析了缩放定律研究中存在的偏差,并提出了一个作者清单来提高研究的可复现性。与现有研究相比,该研究更关注细节差异对结论的影响,并强调了实验细节报告的重要性。
关键设计:论文的关键设计包括:1) 对比不同研究中使用的缩放定律公式、训练设置和优化方法;2) 设计实验来验证特定细节变化对缩放定律拟合结果的影响,例如改变数据集大小、训练时长等;3) 提出一个包含多个方面的作者清单,例如数据预处理、模型架构、超参数设置、优化算法等,以确保研究的可复现性。
🖼️ 关键图片
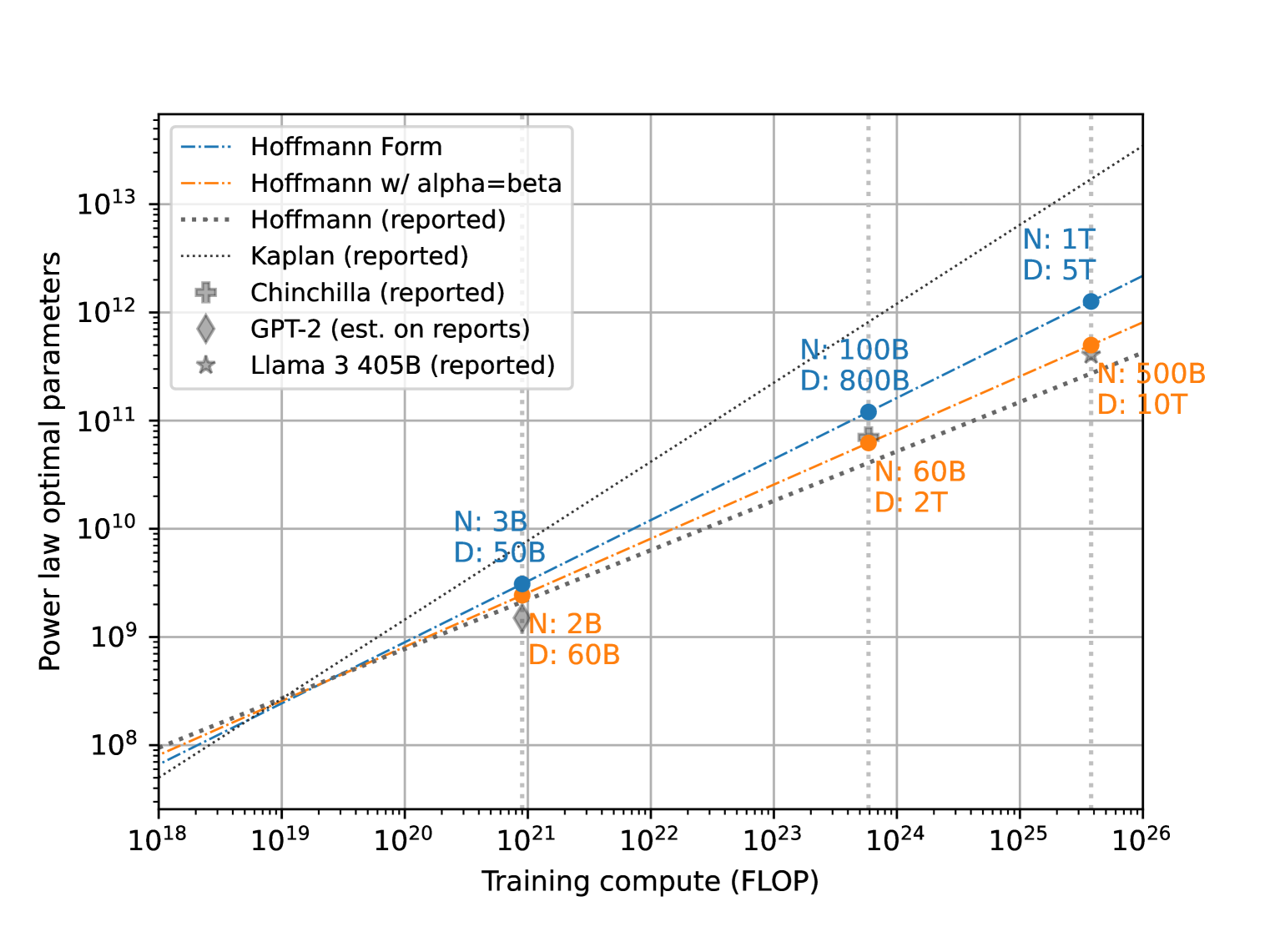
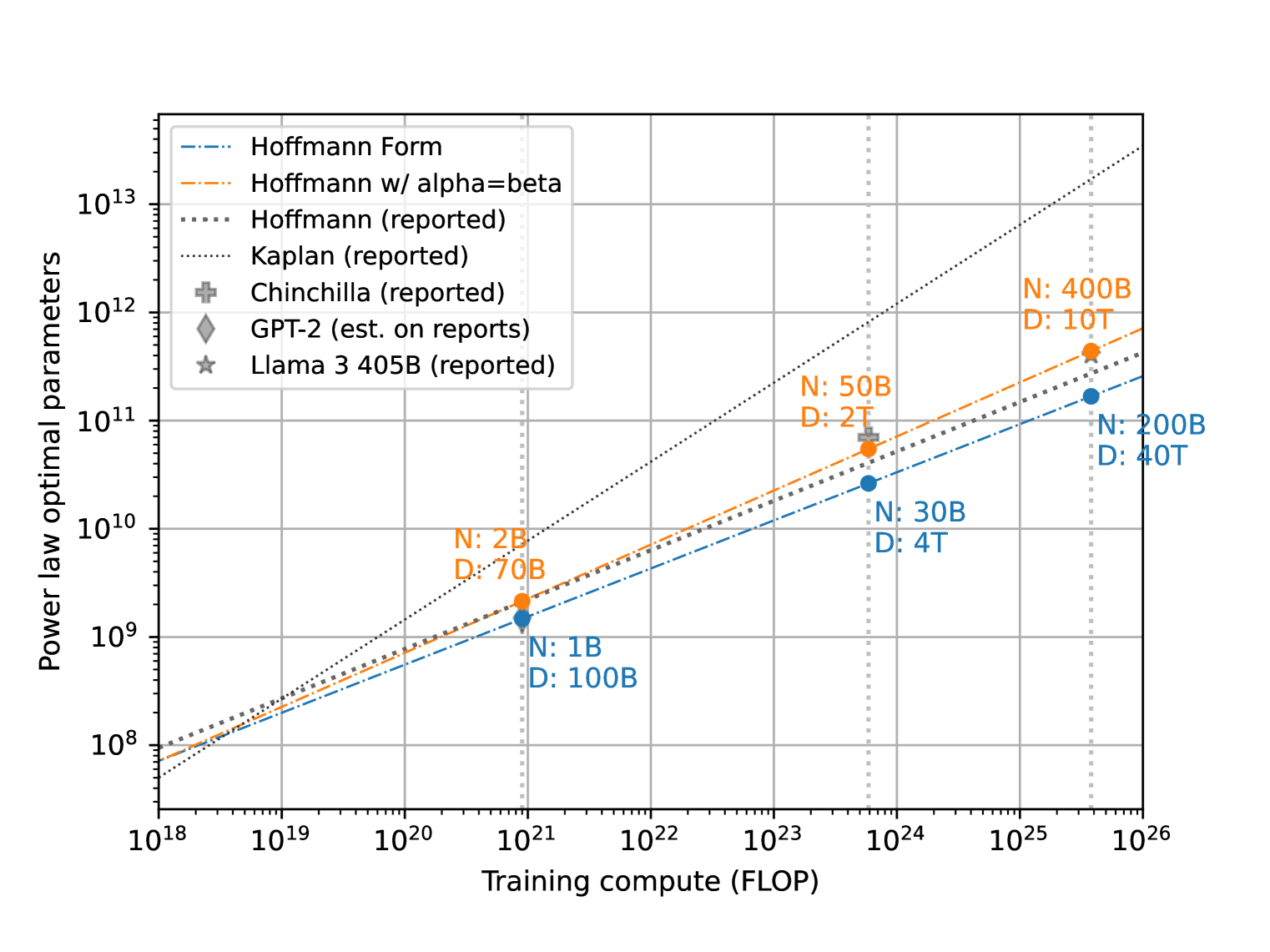
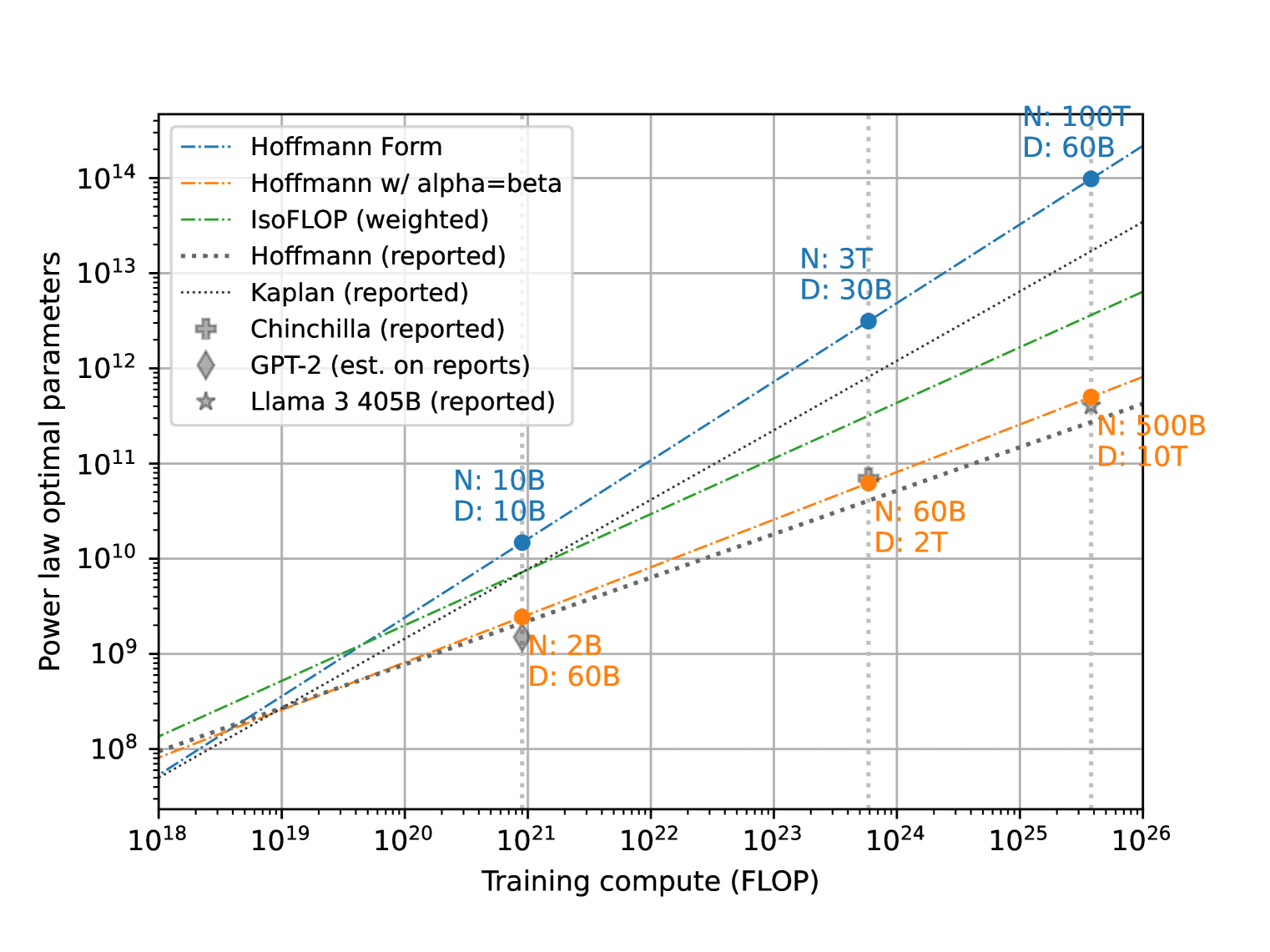
📊 实验亮点
该研究通过分析发现,缩放定律的拟合结果对训练数据量、训练时长等细节非常敏感,即使是微小的变化也可能导致结论的显著差异。此外,研究还发现,许多已发表的缩放定律研究缺乏足够的实验细节,难以复现。提出的作者清单有望改善这一现状。
🎯 应用场景
该研究成果可应用于指导大型语言模型等基础模型的训练和优化。通过更准确地理解缩放定律,可以更有效地选择模型架构、设置超参数,从而降低训练成本,提高模型性能。此外,该研究提出的作者清单有助于提高缩放定律研究的可复现性,促进该领域的发展。
📄 摘要(原文)
Modern foundation models rely heavily on using scaling laws to guide crucial training decisions. Researchers often extrapolate the optimal architecture and hyper parameters settings from smaller training runs by describing the relationship between, loss, or task performance, and scale. All components of this process vary, from the specific equation being fit, to the training setup, to the optimization method. Each of these factors may affect the fitted law, and therefore, the conclusions of a given study. We discuss discrepancies in the conclusions that several prior works reach, on questions such as the optimal token to parameter ratio. We augment this discussion with our own analysis of the critical impact that changes in specific details may effect in a scaling study, and the resulting altered conclusions. Additionally, we survey over 50 papers that study scaling trends: while 45 of these papers quantify these trends using a power law, most under-report crucial details needed to reproduce their findings. To mitigate this, we we propose a checklist for authors to consider while contributing to scaling law research.