M2-omni: Advancing Omni-MLLM for Comprehensive Modality Support with Competitive Performance
作者: Qingpei Guo, Kaiyou Song, Zipeng Feng, Ziping Ma, Qinglong Zhang, Sirui Gao, Xuzheng Yu, Yunxiao Sun, Tai-Wei Chang, Jingdong Chen, Ming Yang, Jun Zhou
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-02-26 (更新: 2025-04-07)
💡 一句话要点
M2-omni:一种具有竞争力的全模态多模态大语言模型,可媲美GPT-4o
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 全模态学习 跨模态理解 序列建模 步长平衡 动态自适应 指令调优 开源模型
📋 核心要点
- 现有全模态MLLM在训练时面临各模态数据量差异大和收敛速度不一致的挑战,影响模型整体性能。
- M2-omni通过步长平衡策略和动态自适应平衡策略,解决模态数据量差异和收敛速度不一致的问题。
- M2-omni在多模态任务上表现出与GPT-4o相媲美的性能,同时保持了强大的纯文本理解能力。
📝 摘要(中文)
本文提出了M2-omni,一种先进的开源全模态多模态大语言模型(omni-MLLM),其性能可与GPT-4o相媲美。M2-omni采用统一的多模态序列建模框架,使大型语言模型(LLM)能够获得全面的跨模态理解和生成能力。具体来说,M2-omni可以处理音频、视频、图像和文本模态的任意组合作为输入,并生成与音频、图像或文本输出交错的多模态序列,从而实现先进的交互式实时体验。训练这种全模态MLLM面临着跨模态数据量和收敛速度的显著差异带来的挑战。为了解决这些挑战,我们提出了一种预训练期间的步长平衡策略,以处理特定模态数据中的数量差异。此外,在指令调优阶段引入了一种动态自适应平衡策略,以同步模态训练进度,确保最佳收敛。值得注意的是,我们优先保持在纯文本任务上的强大性能,以在整个训练过程中保持M2-omni语言理解能力的鲁棒性。据我们所知,M2-omni目前是GPT-4o的一个非常有竞争力的开源模型,其特点是全面的模态和任务支持以及卓越的性能。我们期望M2-omni将推动全模态MLLM的发展,从而促进该领域未来的研究。
🔬 方法详解
问题定义:现有的大型语言模型在处理多模态数据时,面临着不同模态数据量差异巨大以及各模态收敛速度不一致的问题。这种不平衡性会导致模型在某些模态上表现不佳,影响整体的多模态理解和生成能力。此外,如何在训练过程中保持模型在纯文本任务上的强大性能也是一个挑战。
核心思路:M2-omni的核心思路是采用统一的多模态序列建模框架,并设计相应的训练策略来解决模态数据不平衡的问题。通过步长平衡策略来处理预训练阶段模态数据量的差异,并使用动态自适应平衡策略来同步指令调优阶段的模态训练进度。同时,在训练过程中优先保持模型在纯文本任务上的性能,以确保语言理解能力的鲁棒性。
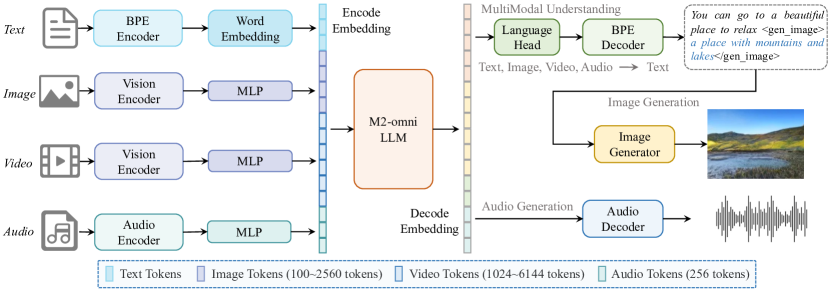
技术框架:M2-omni采用统一的多模态序列建模框架,可以处理任意组合的音频、视频、图像和文本模态作为输入,并生成与音频、图像或文本输出交错的多模态序列。整体训练流程包括预训练和指令调优两个阶段。在预训练阶段,使用步长平衡策略来处理模态数据量的差异。在指令调优阶段,使用动态自适应平衡策略来同步模态训练进度。
关键创新:M2-omni的关键创新在于提出了步长平衡策略和动态自适应平衡策略,有效地解决了多模态训练中数据量差异和收敛速度不一致的问题。步长平衡策略通过调整不同模态数据的训练步数,使得数据量较小的模态能够得到更充分的训练。动态自适应平衡策略则根据各模态的训练进度动态调整损失权重,以实现同步收敛。
关键设计:步长平衡策略的具体实现是根据各模态的数据量比例来调整训练步数。动态自适应平衡策略则是根据各模态的验证集损失来动态调整损失权重,使得损失较大的模态能够得到更多的关注。具体的损失函数和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
M2-omni在多模态任务上取得了与GPT-4o相媲美的性能,证明了其在全模态理解和生成方面的强大能力。同时,M2-omni在纯文本任务上保持了强大的性能,表明其在训练过程中有效地保留了语言理解能力。具体的性能数据和对比基线在摘要中未给出,属于未知信息。
🎯 应用场景
M2-omni具有广泛的应用前景,例如智能助手、多模态内容创作、跨模态信息检索、以及人机交互等领域。它可以应用于需要理解和生成多种模态信息的场景,例如根据用户的语音指令生成包含图像和文本的回复,或者根据视频内容生成相应的文本描述和音频提示。M2-omni的开源特性也将促进多模态大语言模型领域的研究和发展。
📄 摘要(原文)
We present M2-omni, a cutting-edge, open-source omni-MLLM that achieves competitive performance to GPT-4o. M2-omni employs a unified multimodal sequence modeling framework, which empowers Large Language Models(LLMs) to acquire comprehensive cross-modal understanding and generation capabilities. Specifically, M2-omni can process arbitrary combinations of audio, video, image, and text modalities as input, generating multimodal sequences interleaving with audio, image, or text outputs, thereby enabling an advanced and interactive real-time experience. The training of such an omni-MLLM is challenged by significant disparities in data quantity and convergence rates across modalities. To address these challenges, we propose a step balance strategy during pre-training to handle the quantity disparities in modality-specific data. Additionally, a dynamically adaptive balance strategy is introduced during the instruction tuning stage to synchronize the modality-wise training progress, ensuring optimal convergence. Notably, we prioritize preserving strong performance on pure text tasks to maintain the robustness of M2-omni's language understanding capability throughout the training process. To our best knowledge, M2-omni is currently a very competitive open-source model to GPT-4o, characterized by its comprehensive modality and task support, as well as its exceptional performance. We expect M2-omni will advance the development of omni-MLLMs, thus facilitating future research in this domain.