Reward Shaping to Mitigate Reward Hacking in RLHF
作者: Jiayi Fu, Xuandong Zhao, Chengyuan Yao, Heng Wang, Qi Han, Yanghua Xiao
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-02-26 (更新: 2026-01-08)
🔗 代码/项目: GITHUB
💡 一句话要点
提出Preference As Reward (PAR)方法,缓解RLHF中的奖励利用问题,提升对齐效果。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: RLHF 奖励塑造 奖励利用 偏好学习 大型语言模型
📋 核心要点
- RLHF易受奖励利用问题影响,智能体可能利用奖励函数的缺陷而非学习预期行为,导致对齐效果下降。
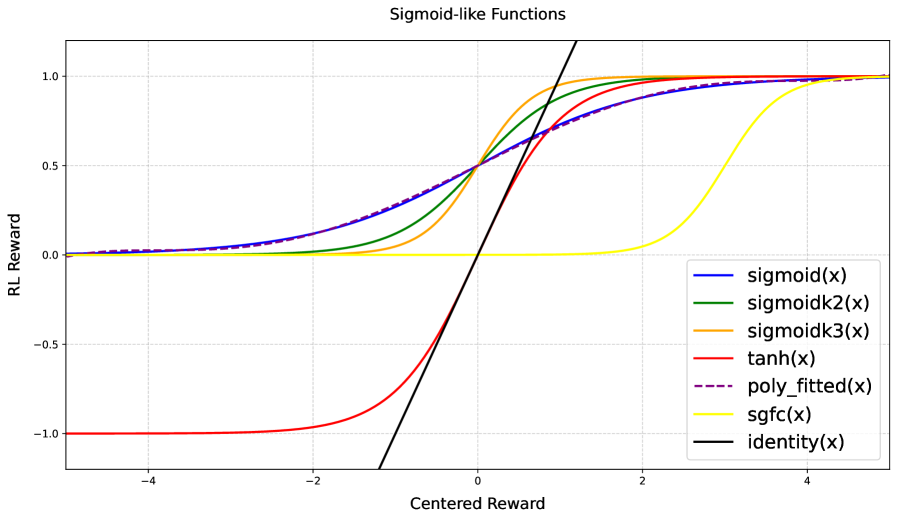
- 论文提出Preference As Reward (PAR)方法,利用奖励模型中蕴含的潜在偏好作为强化学习信号,并遵循奖励塑造的关键设计原则。
- 实验表明,PAR在AlpacaEval 2.0上胜率至少高5%,且具有数据高效性,仅需少量参考奖励即可达到最佳性能,并对奖励利用具有鲁棒性。
📝 摘要(中文)
从人类反馈中进行强化学习(RLHF)对于使大型语言模型(LLMs)与人类价值观对齐至关重要。然而,RLHF容易受到“奖励利用”的影响,即智能体利用奖励函数中的缺陷,而不是学习预期的行为,从而降低对齐效果。虽然奖励塑造有助于稳定RLHF并部分缓解奖励利用,但对塑造技术及其基本原理的系统研究仍然缺乏。为了弥合这一差距,我们对流行的奖励塑造方法进行了全面的研究。我们的分析提出了两个关键的设计原则:(1)RL奖励应该是有界的,(2)RL奖励受益于快速的初始增长,然后是逐渐的收敛。在这些见解的指导下,我们提出了一种新的方法Preference As Reward (PAR),它利用嵌入在奖励模型中的潜在偏好作为强化学习的信号。此外,PAR表现出两个关键的方差减少特性,有助于稳定RLHF训练过程,并有效地延长提前停止的容忍窗口。我们使用Gemma2-2B作为基础模型,并在Ultrafeedback-Binarized和HH-RLHF两个数据集上评估了PAR。实验结果表明,PAR优于其他奖励塑造方法。在AlpacaEval 2.0基准测试中,PAR的胜率比竞争方法至少高5个百分点。此外,PAR表现出卓越的数据效率,只需要一个参考奖励即可获得最佳性能,并且即使经过两个完整的训练周期,也能保持对奖励利用的鲁棒性。
🔬 方法详解
问题定义:RLHF旨在通过人类反馈对齐大型语言模型,但容易受到奖励利用(reward hacking)的影响。现有的奖励塑造方法虽然能部分缓解该问题,但缺乏系统性的研究和理论指导,难以保证训练的稳定性和最终的对齐效果。模型可能学习到利用奖励函数的漏洞,而非真正符合人类意图的行为。
核心思路:PAR的核心思路是将奖励模型中蕴含的潜在偏好作为强化学习的信号。不同于直接使用奖励模型的输出作为奖励,PAR利用奖励模型学习到的偏好信息,从而提供更稳定和更符合人类意图的奖励信号。这种方法旨在引导模型学习更泛化的策略,减少对奖励函数特定缺陷的依赖。
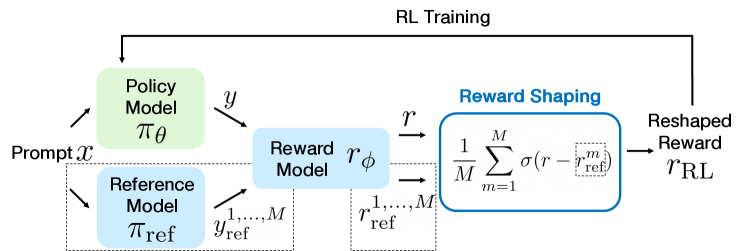
技术框架:PAR的整体框架包括以下几个主要步骤:1) 使用人类反馈数据训练奖励模型;2) 从奖励模型中提取潜在偏好信息;3) 将提取的偏好信息作为强化学习的奖励信号,训练语言模型。具体来说,PAR利用奖励模型对不同回复的排序信息,构建一个偏好概率分布,并将其作为强化学习的奖励。
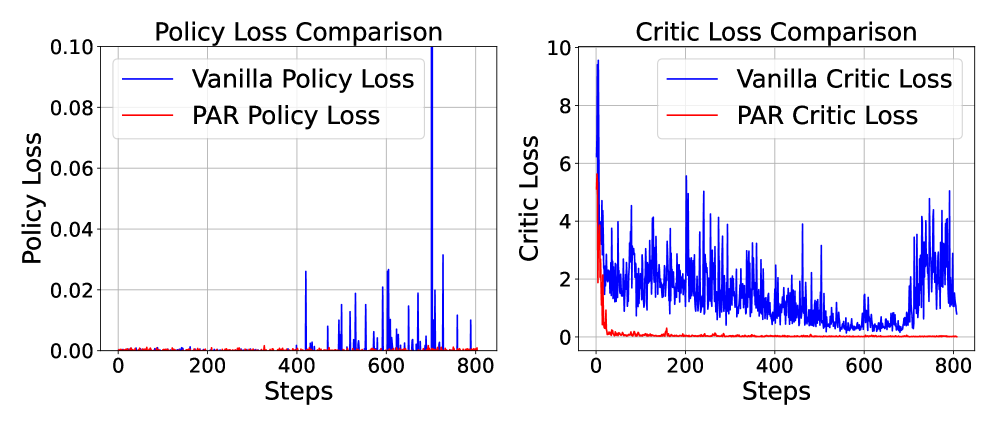
关键创新:PAR的关键创新在于将奖励模型学习到的偏好信息显式地用于奖励塑造。与传统的奖励塑造方法相比,PAR不直接依赖于奖励模型的绝对值,而是关注不同回复之间的相对偏好关系。这种方法能够减少奖励函数的噪声和偏差,从而提高训练的稳定性和泛化能力。此外,PAR还具有方差减少的特性,有助于稳定RLHF训练过程。
关键设计:PAR的关键设计包括:1) 使用Binarized Ultrafeedback数据集训练奖励模型;2) 利用奖励模型输出的排序信息构建偏好概率分布;3) 使用PPO算法进行强化学习,其中奖励信号为偏好概率分布。论文还强调了奖励的边界性和奖励增长的速率,并提出PAR只需要一个参考奖励即可达到最佳性能,这体现了其数据高效性。
🖼️ 关键图片
📊 实验亮点
PAR在AlpacaEval 2.0基准测试中,相较于其他奖励塑造方法,胜率至少提升了5个百分点。此外,PAR展现出卓越的数据效率,仅需单个参考奖励即可实现最佳性能,并且即使经过两个完整的训练周期,仍能保持对奖励利用的鲁棒性,表明其在实际应用中具有更强的稳定性和可靠性。
🎯 应用场景
PAR方法可广泛应用于各种需要通过人类反馈进行模型对齐的场景,例如对话系统、文本生成、推荐系统等。该方法能够提高模型的安全性和可靠性,减少模型产生有害或不符合人类价值观的内容的风险。此外,PAR的数据高效性使其在资源受限的情况下也能发挥作用,具有重要的实际应用价值。
📄 摘要(原文)
Reinforcement Learning from Human Feedback (RLHF) is essential for aligning large language models (LLMs) with human values. However, RLHF is susceptible to \emph{reward hacking}, where the agent exploits flaws in the reward function rather than learning the intended behavior, thus degrading alignment. Although reward shaping helps stabilize RLHF and partially mitigate reward hacking, a systematic investigation into shaping techniques and their underlying principles remains lacking. To bridge this gap, we present a comprehensive study of the prevalent reward shaping methods. Our analysis suggests two key design principles: (1) the RL reward should be bounded, and (2) the RL reward benefits from rapid initial growth followed by gradual convergence. Guided by these insights, we propose Preference As Reward (PAR), a novel approach that leverages the latent preferences embedded within the reward model as the signal for reinforcement learning. Moreover, PAR exhibits two critical variance-reduction properties that contribute to stabilizing the RLHF training process and effectively extending the tolerance window for early stopping. We evaluated PAR on the base model Gemma2-2B using two datasets, Ultrafeedback-Binarized and HH-RLHF. Experimental results demonstrate PAR's superior performance over other reward shaping methods. On the AlpacaEval 2.0 benchmark, PAR achieves a win rate of at least 5 percentage points higher than competing approaches. Furthermore, PAR exhibits remarkable data efficiency, requiring only a single reference reward for optimal performance, and maintains robustness against reward hacking even after two full epochs of training. The code is available at https://github.com/PorUna-byte/PAR.