AMPO: Active Multi-Preference Optimization for Self-play Preference Selection
作者: Taneesh Gupta, Rahul Madhavan, Xuchao Zhang, Chetan Bansal, Saravan Rajmohan
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-02-25 (更新: 2025-06-08)
备注: Accepted at ICML 2025
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
提出AMPO,通过主动多偏好优化实现自博弈偏好选择,提升语言模型对齐效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型对齐 自博弈学习 多偏好优化 主动学习 对比学习 奖励模型 在线学习 子集选择
📋 核心要点
- 现有自博弈对齐方法难以处理大量候选回复,计算成本高昂,限制了训练效果。
- AMPO通过主动选择信息量大的回复子集,降低计算负担,同时保留关键的偏好信息。
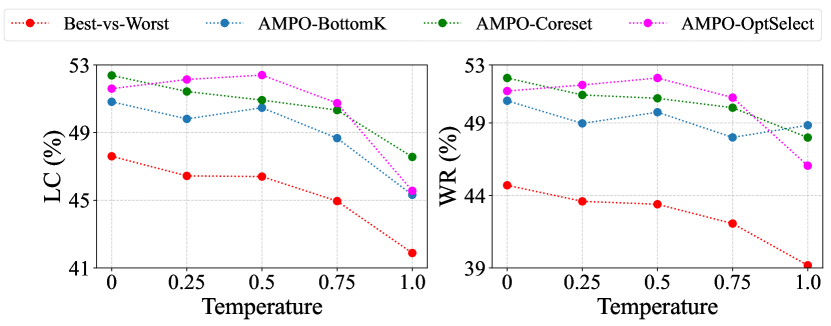
- 实验表明,AMPO在AlpacaEval上使用Llama 8B和Mistral 7B模型取得了领先的性能。
📝 摘要(中文)
多偏好优化通过对比整套有益和不良的回复,丰富了语言模型对齐,超越了成对偏好,从而为大型语言模型提供了更丰富的训练信号。在自博弈对齐期间,这些模型通常为每个查询生成大量候选答案,使得将所有回复都包含在训练目标中在计算上是不可行的。本文提出了主动多偏好优化(AMPO),这是一种结合了在线生成、多偏好组对比损失和主动子集选择的新方法。具体来说,我们对大型候选回复池进行评分和嵌入,然后选择一个小的但信息丰富的子集,该子集涵盖奖励极值和不同的语义聚类,以进行偏好优化。我们的对比训练方案不仅能够识别最佳和最差答案,还能识别对于鲁棒对齐至关重要的微妙的、未充分探索的模式。在理论上,我们为使用我们的主动选择方法实现预期奖励最大化提供了保证,并且在经验上,AMPO在使用Llama 8B和Mistral 7B的AlpacaEval上实现了最先进的结果。我们在此处发布我们的数据集。
🔬 方法详解
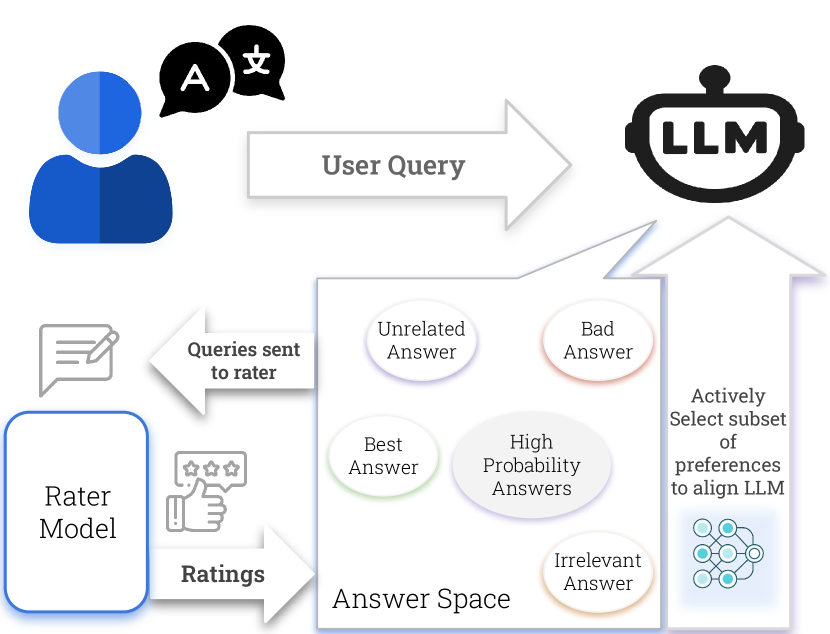
问题定义:在语言模型自博弈对齐中,模型会为每个问题生成多个候选答案。直接使用所有答案进行训练(多偏好优化)计算量巨大,难以实现。现有方法通常只考虑成对偏好,忽略了更丰富的多偏好信息,可能导致模型对齐不充分。
核心思路:AMPO的核心在于主动选择最具信息量的回复子集进行训练。通过对所有候选回复进行评分和嵌入,然后选择既包含奖励极值又覆盖不同语义聚类的子集,从而在降低计算成本的同时,保留了关键的偏好信息。
技术框架:AMPO包含以下几个主要阶段:1) 使用在线策略生成大量候选回复;2) 对候选回复进行评分和嵌入;3) 使用主动子集选择算法选择信息量最大的子集;4) 使用多偏好组对比损失函数进行训练。整体流程旨在高效地利用有限的计算资源,提升模型对齐效果。
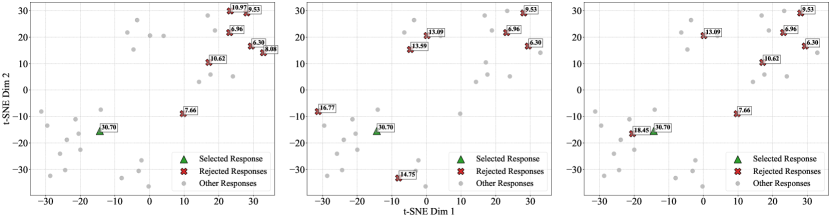
关键创新:AMPO的关键创新在于主动子集选择策略。它不同于随机选择或简单地选择最佳/最差回复,而是通过考虑奖励和语义信息,选择能够代表整体分布的子集。这种策略能够更好地捕捉细微的偏好差异,提升模型的鲁棒性。
关键设计:AMPO使用多偏好组对比损失函数,鼓励模型区分不同偏好等级的回复。主动子集选择算法的具体实现可能涉及聚类算法(例如k-means)和奖励值排序。论文中可能还包含关于嵌入向量维度、损失函数权重等超参数的设置。
🖼️ 关键图片
📊 实验亮点
AMPO在AlpacaEval基准测试中,使用Llama 8B和Mistral 7B模型取得了最先进的结果,表明其在语言模型对齐方面的有效性。具体性能数据(例如胜率或平均奖励)需要在论文中查找。该结果证明了主动多偏好优化策略在提升模型性能方面的优势。
🎯 应用场景
AMPO可应用于各种需要语言模型对齐的场景,例如对话系统、文本生成和问答系统。通过更有效地利用自博弈数据,AMPO能够提升语言模型的安全性、可靠性和有用性,使其更好地服务于人类用户。该方法在教育、客服、内容创作等领域具有广泛的应用前景。
📄 摘要(原文)
Multi-preference optimization enriches language-model alignment beyond pairwise preferences by contrasting entire sets of helpful and undesired responses, thereby enabling richer training signals for large language models. During self-play alignment, these models often produce numerous candidate answers per query, rendering it computationally infeasible to include all responses in the training objective. In this work, we propose $\textit{Active Multi-Preference Optimization}$ (AMPO), a novel approach that combines on-policy generation, a multi-preference group-contrastive loss, and active subset selection. Specifically, we score and embed large candidate pools of responses and then select a small, yet informative, subset that covers reward extremes and distinct semantic clusters for preference optimization. Our contrastive training scheme is capable of identifying not only the best and worst answers but also subtle, underexplored modes that are crucial for robust alignment. Theoretically, we provide guarantees for expected reward maximization using our active selection method, and empirically, AMPO achieves state-of-the-art results on $\textit{AlpacaEval}$ using Llama 8B and Mistral 7B. We release our datasets $\href{https://huggingface.co/Multi-preference-Optimization}{here}$.