SpikeRL: A Scalable and Energy-efficient Framework for Deep Spiking Reinforcement Learning
作者: Tokey Tahmid, Mark Gates, Piotr Luszczek, Catherine D. Schuman
分类: cs.LG, cs.AI, cs.NE
发布日期: 2025-02-21
💡 一句话要点
SpikeRL:一种可扩展且节能的深度脉冲强化学习框架,用于复杂连续控制任务。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 脉冲神经网络 深度强化学习 连续控制 分布式训练 混合精度训练
📋 核心要点
- 现有深度强化学习方法在复杂连续控制任务中面临能源效率和可扩展性的挑战,尤其是在脉冲神经网络(SNN)的应用中。
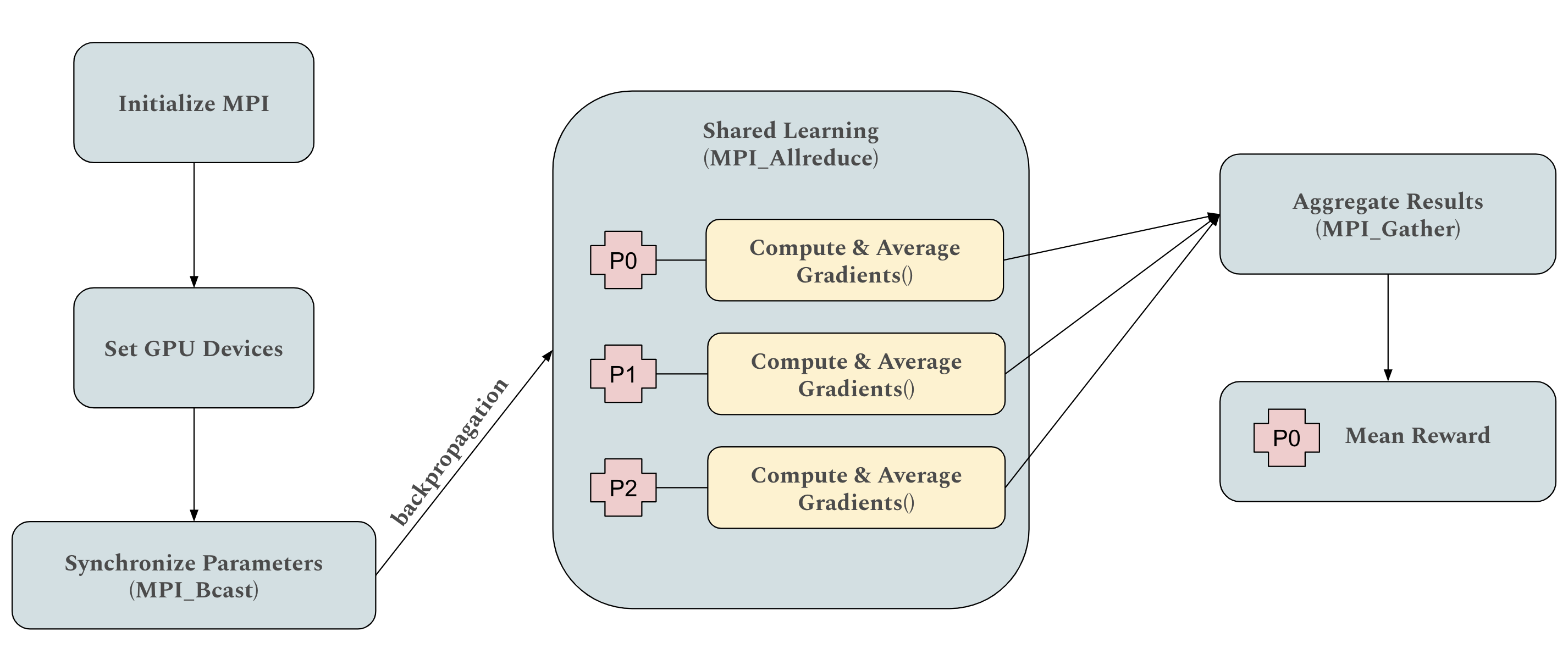
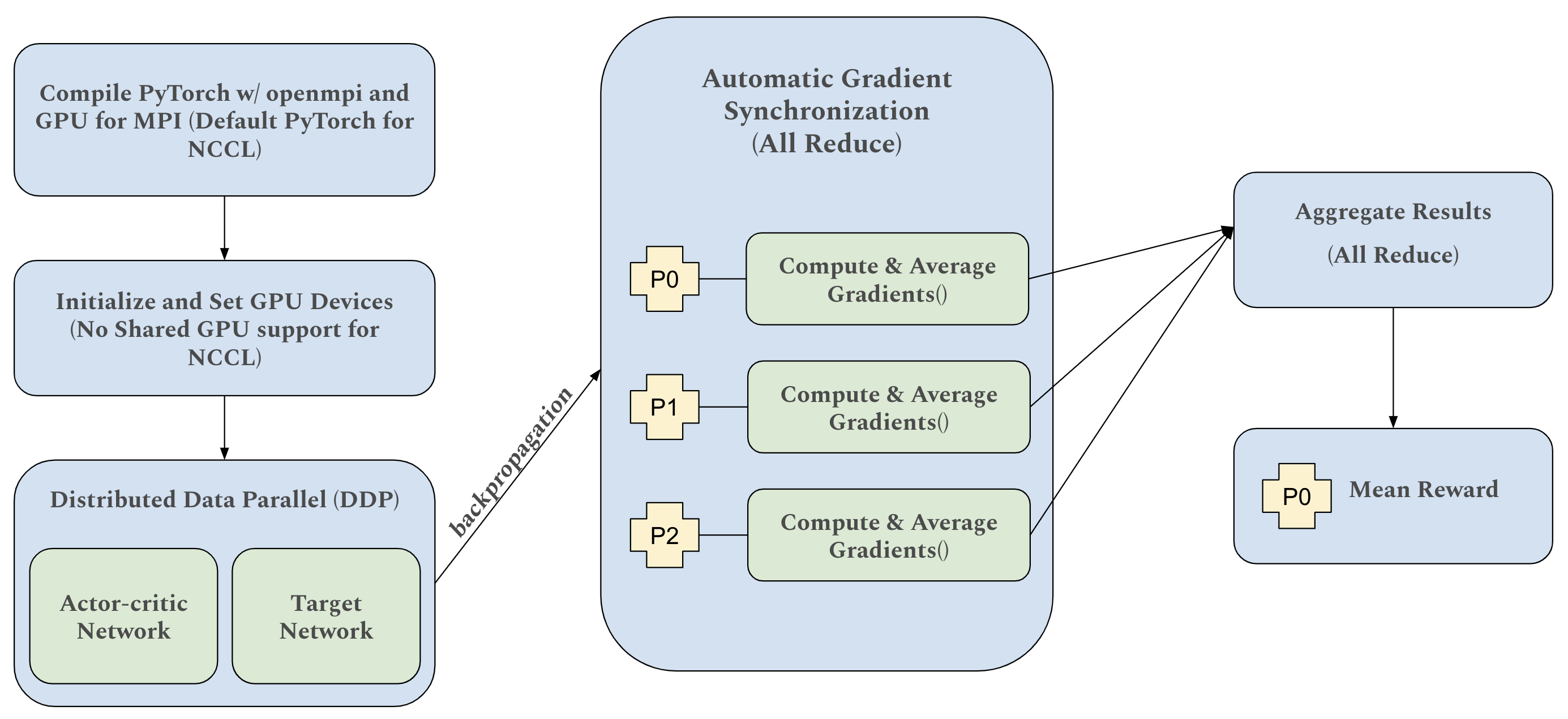
- SpikeRL框架通过结合群体编码的SNN和PyTorch Distributed进行分布式训练,并采用混合精度优化,实现了更高的能源效率和可扩展性。
- 实验结果表明,SpikeRL在性能上优于现有DeepRL-SNN方法,速度提升4.26倍,能效提升2.25倍,为实际应用提供了可持续的解决方案。
📝 摘要(中文)
在人工智能革命时代,对大规模数据驱动的人工智能系统的巨额投资需要高性能计算,消耗大量的能源和资源。这种趋势对优化可持续性提出了新的挑战,同时不能牺牲可扩展性或性能。在传统冯·诺依曼架构的节能替代方案中,神经形态计算及其脉冲神经网络(SNN)由于其固有的能源效率而成为一种有希望的选择。然而,在某些实际应用场景中,例如复杂的连续控制任务,SNN通常缺乏传统人工神经网络所具有的性能优化。研究人员通过将SNN与深度强化学习(DeepRL)相结合来解决这个问题,但可扩展性仍未得到探索。在本文中,我们扩展了我们之前关于SpikeRL的工作,SpikeRL是一个可扩展且节能的基于DeepRL的SNN框架,用于连续控制。在我们最初的SpikeRL框架实现中,我们依赖于来自Population-coded Spiking Actor Network(PopSAN)方法的群体编码作为我们的SNN模型,并通过mpi4py使用消息传递接口(MPI)实现分布式训练。此外,通过使用混合精度进行参数更新来进一步优化我们的模型训练。在我们新的SpikeRL框架中,我们已经实现了我们自己的带有群体编码的DeepRL-SNN组件,以及使用带有NCCL后端的PyTorch Distributed包进行分布式训练,同时仍然使用混合精度训练进行优化。我们新的SpikeRL实现比最先进的DeepRL-SNN方法快4.26倍,节能2.25倍。我们提出的SpikeRL框架展示了一种真正可扩展和可持续的解决方案,用于实际应用中复杂的连续控制任务。
🔬 方法详解
问题定义:论文旨在解决深度强化学习在复杂连续控制任务中,使用脉冲神经网络(SNN)时面临的能源效率和可扩展性问题。现有的DeepRL-SNN方法在处理大规模问题时,计算成本高昂,难以实现高效的分布式训练。
核心思路:论文的核心思路是构建一个可扩展且节能的DeepRL-SNN框架,名为SpikeRL。该框架通过优化SNN的结构和训练方式,并结合高效的分布式训练策略,从而在保证性能的同时,显著降低能源消耗。
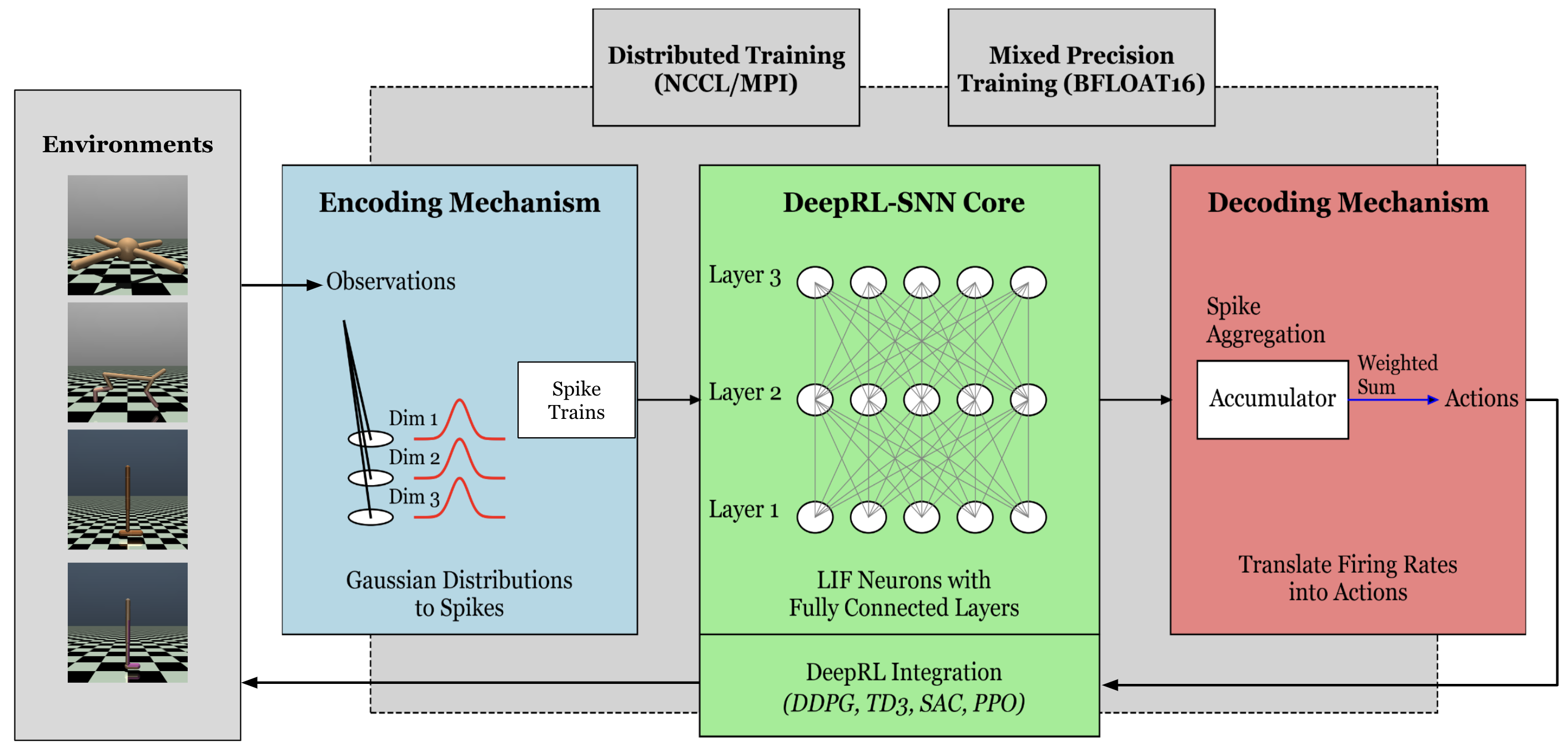
技术框架:SpikeRL框架包含以下主要模块:1) 基于群体编码的SNN模型,用于表示状态和动作;2) 使用PyTorch Distributed包和NCCL后端实现的分布式训练模块,用于加速模型训练;3) 混合精度训练优化模块,用于进一步降低计算成本和内存占用。整体流程是:首先,SNN模型接收环境状态作为输入,通过前向传播计算动作;然后,根据环境反馈更新模型参数;最后,通过分布式训练和混合精度优化,提高训练效率和降低能耗。
关键创新:SpikeRL的关键创新在于其对SNN模型和分布式训练策略的优化。与传统的DeepRL-SNN方法相比,SpikeRL采用了更高效的群体编码方式,并利用PyTorch Distributed实现了高度并行的训练。此外,混合精度训练的引入进一步降低了计算复杂度,从而实现了更高的能源效率。
关键设计:SpikeRL的关键设计包括:1) 使用群体编码来表示连续的状态和动作空间,每个神经元代表一个特定的动作或状态范围;2) 使用PyTorch Distributed的NCCL后端进行分布式训练,实现高效的通信和同步;3) 采用混合精度训练,使用FP16和FP32混合存储和计算,以降低内存占用和加速计算。
🖼️ 关键图片
📊 实验亮点
SpikeRL框架在实验中表现出色,与最先进的DeepRL-SNN方法相比,速度提升了4.26倍,能效提升了2.25倍。这些结果表明,SpikeRL在保证性能的同时,显著降低了能源消耗,为实际应用提供了更具可持续性的解决方案。实验结果充分验证了SpikeRL框架的可行性和有效性。
🎯 应用场景
SpikeRL框架适用于需要高能效和可扩展性的复杂连续控制任务,例如机器人控制、自动驾驶、智能电网等。该框架的实际价值在于降低了AI系统的能源消耗,提高了计算效率,为可持续人工智能的发展提供了新的途径。未来,SpikeRL有望在更多领域得到应用,推动人工智能技术的普及和发展。
📄 摘要(原文)
In this era of AI revolution, massive investments in large-scale data-driven AI systems demand high-performance computing, consuming tremendous energy and resources. This trend raises new challenges in optimizing sustainability without sacrificing scalability or performance. Among the energy-efficient alternatives of the traditional Von Neumann architecture, neuromorphic computing and its Spiking Neural Networks (SNNs) are a promising choice due to their inherent energy efficiency. However, in some real-world application scenarios such as complex continuous control tasks, SNNs often lack the performance optimizations that traditional artificial neural networks have. Researchers have addressed this by combining SNNs with Deep Reinforcement Learning (DeepRL), yet scalability remains unexplored. In this paper, we extend our previous work on SpikeRL, which is a scalable and energy efficient framework for DeepRL-based SNNs for continuous control. In our initial implementation of SpikeRL framework, we depended on the population encoding from the Population-coded Spiking Actor Network (PopSAN) method for our SNN model and implemented distributed training with Message Passing Interface (MPI) through mpi4py. Also, further optimizing our model training by using mixed-precision for parameter updates. In our new SpikeRL framework, we have implemented our own DeepRL-SNN component with population encoding, and distributed training with PyTorch Distributed package with NCCL backend while still optimizing with mixed precision training. Our new SpikeRL implementation is 4.26X faster and 2.25X more energy efficient than state-of-the-art DeepRL-SNN methods. Our proposed SpikeRL framework demonstrates a truly scalable and sustainable solution for complex continuous control tasks in real-world applications.