Enhancing PPO with Trajectory-Aware Hybrid Policies
作者: Qisai Liu, Zhanhong Jiang, Hsin-Jung Yang, Mahsa Khosravi, Joshua R. Waite, Soumik Sarkar
分类: cs.LG
发布日期: 2025-02-21
💡 一句话要点
提出HP3O算法,利用轨迹回放缓存增强PPO,提升强化学习性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 近端策略优化 轨迹回放 混合策略 连续控制
📋 核心要点
- PPO算法虽然稳定,但高方差和高样本复杂度限制了其性能。
- HP3O算法利用轨迹回放缓存,重用近期策略产生的轨迹,提升样本效率。
- 实验表明,HP3O在多个连续控制环境中优于基线算法,验证了其有效性。
📝 摘要(中文)
近端策略优化(PPO)是最流行的先进的在线算法之一,已成为现代强化学习的标准基线,并在众多领域得到应用。尽管它提供了稳定的性能和理论上的策略改进保证,但高方差和高样本复杂度仍然是在线算法中的关键挑战。为了缓解这些问题,我们提出了混合策略近端策略优化(HP3O),它利用轨迹回放缓存来有效地利用最近策略生成的轨迹。特别是,该缓存应用“先进先出”(FIFO)策略,以便仅保留最近的轨迹,从而减弱数据分布漂移。由具有最佳回报的轨迹和从缓存中随机抽样的其他轨迹组成的批次用于更新策略网络。该策略有助于智能体在最近的最佳性能之上提高其能力,从而在经验上降低方差。我们从理论上构建了所提出算法的策略改进保证。HP3O通过多个连续控制环境进行了验证,并与几种基线算法进行了比较。我们的代码已在此处提供。
🔬 方法详解
问题定义:PPO算法作为一种on-policy强化学习算法,存在样本利用率低和方差大的问题。每次策略更新都需要重新采样数据,导致学习效率不高。此外,策略梯度估计的方差也会影响训练的稳定性。
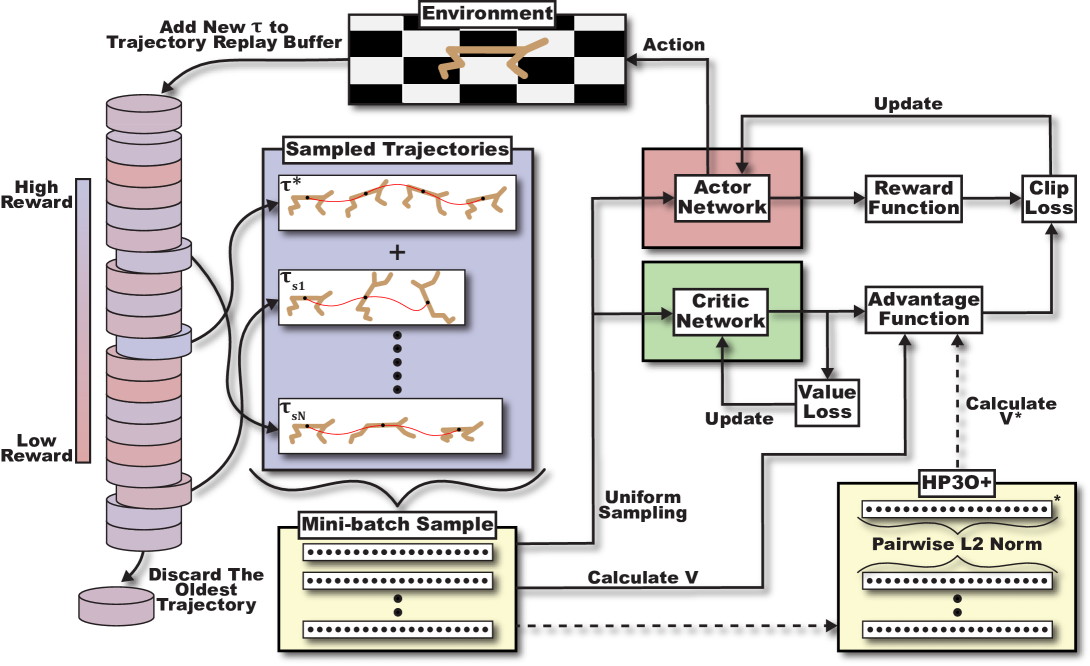
核心思路:HP3O的核心思路是引入一个轨迹回放缓存,存储近期策略产生的轨迹。通过重用这些轨迹,可以提高样本利用率,减少方差。同时,采用FIFO策略,保证缓存中的轨迹来自近期策略,从而减轻数据分布漂移的影响。
技术框架:HP3O的整体框架与PPO类似,主要包括策略网络、价值网络和环境交互三个部分。不同之处在于,HP3O增加了一个轨迹回放缓存。智能体与环境交互产生轨迹后,将其存入缓存。策略更新时,从缓存中选择一部分轨迹(包括最优轨迹和随机抽样轨迹)与当前策略产生的数据一起用于训练。
关键创新:HP3O的关键创新在于混合策略的使用,即同时利用当前策略产生的数据和回放缓存中的数据进行训练。这种混合策略可以兼顾探索和利用,提高学习效率和稳定性。此外,选择最优轨迹加入训练可以加速学习过程。
关键设计:HP3O采用FIFO缓存策略,保证缓存中的轨迹来自近期策略。在策略更新时,从缓存中选择一个最优轨迹和若干随机轨迹。最优轨迹的选择基于轨迹的累积回报。损失函数与PPO相同,包括策略损失、价值损失和熵正则化项。网络结构可以根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
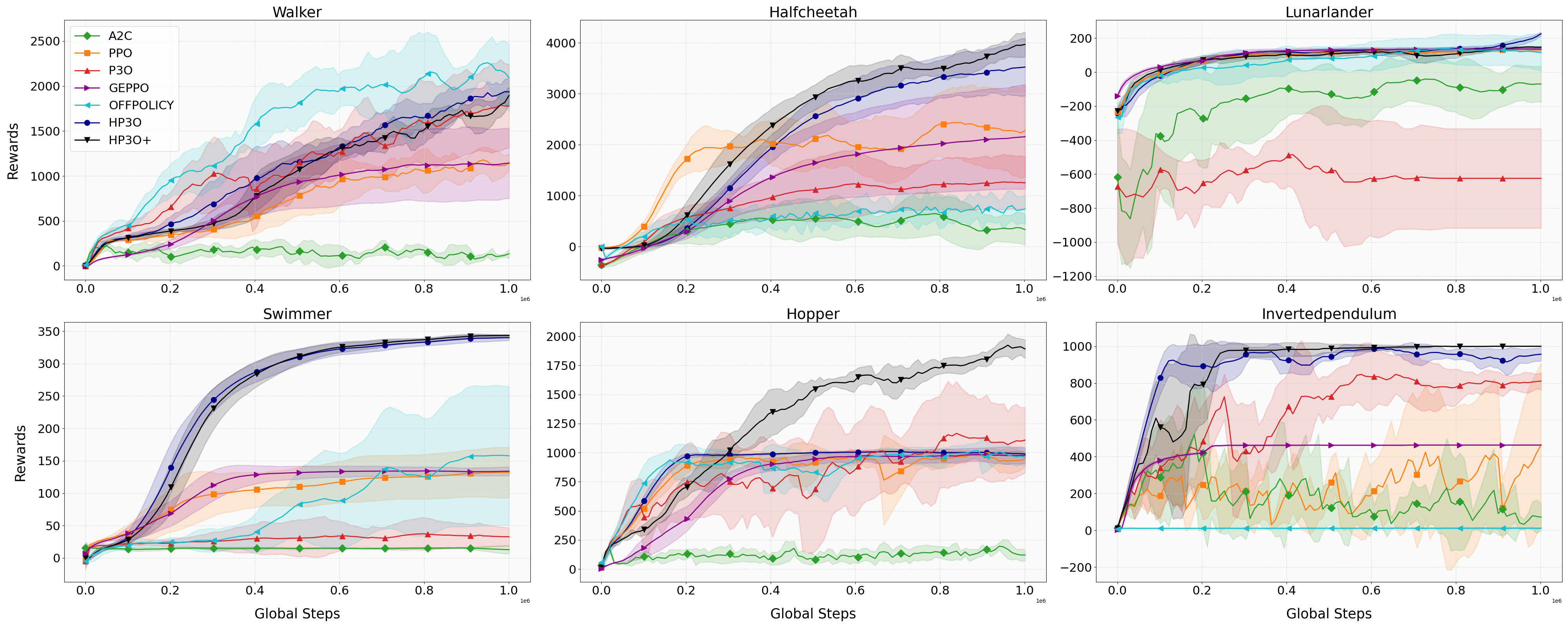
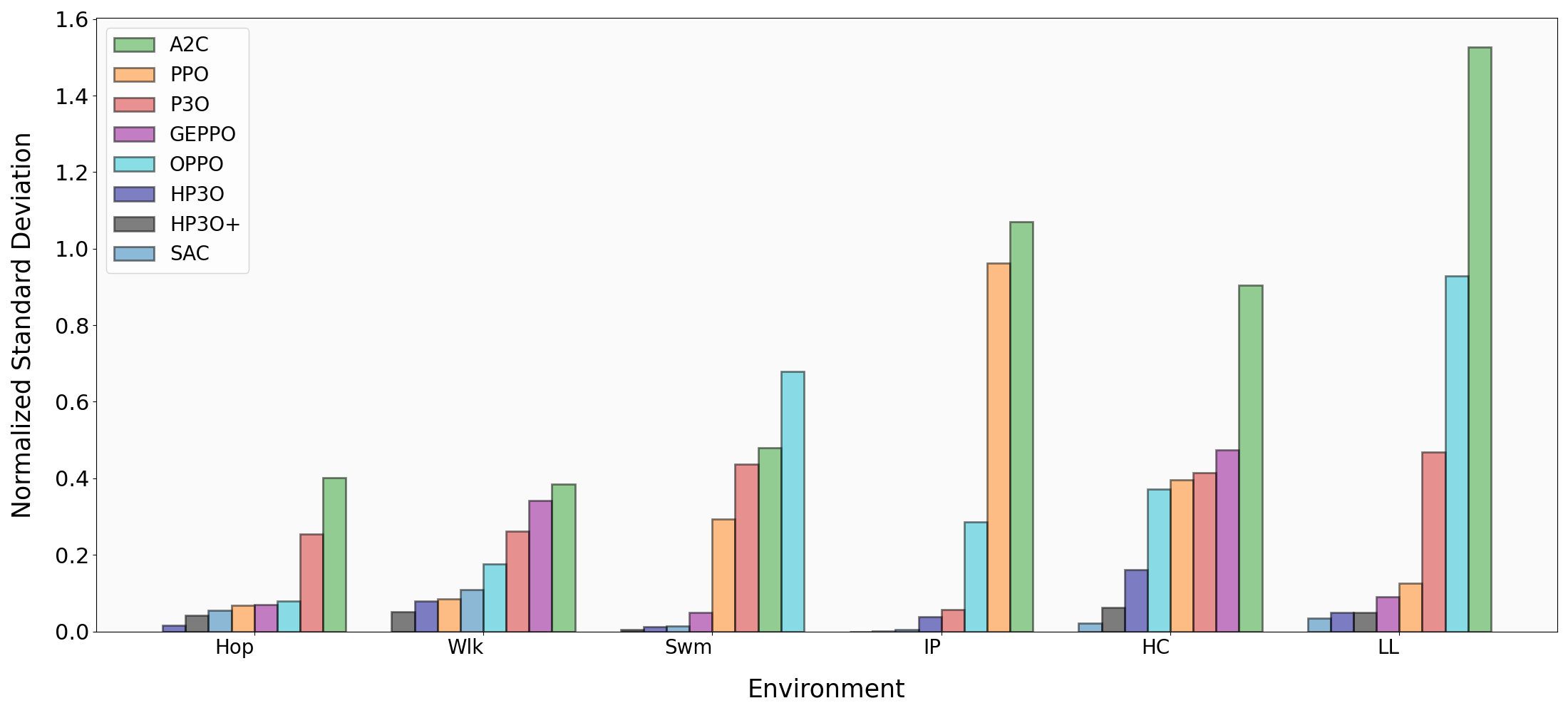
实验结果表明,HP3O在多个连续控制环境中显著优于PPO等基线算法。例如,在某些任务中,HP3O的性能提升超过20%。此外,HP3O的方差更小,训练过程更稳定,表明其具有更好的鲁棒性。
🎯 应用场景
HP3O算法可应用于各种连续控制任务,例如机器人控制、自动驾驶、游戏AI等。通过提高样本效率和稳定性,HP3O可以加速强化学习算法在实际场景中的部署和应用,降低训练成本,并提升智能体的性能。
📄 摘要(原文)
Proximal policy optimization (PPO) is one of the most popular state-of-the-art on-policy algorithms that has become a standard baseline in modern reinforcement learning with applications in numerous fields. Though it delivers stable performance with theoretical policy improvement guarantees, high variance, and high sample complexity still remain critical challenges in on-policy algorithms. To alleviate these issues, we propose Hybrid-Policy Proximal Policy Optimization (HP3O), which utilizes a trajectory replay buffer to make efficient use of trajectories generated by recent policies. Particularly, the buffer applies the "first in, first out" (FIFO) strategy so as to keep only the recent trajectories to attenuate the data distribution drift. A batch consisting of the trajectory with the best return and other randomly sampled ones from the buffer is used for updating the policy networks. The strategy helps the agent to improve its capability on top of the most recent best performance and in turn reduce variance empirically. We theoretically construct the policy improvement guarantees for the proposed algorithm. HP3O is validated and compared against several baseline algorithms using multiple continuous control environments. Our code is available here.