Steering LLMs for Formal Theorem Proving
作者: Shashank Kirtania, Arun Iyer
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-02-21 (更新: 2025-10-13)
💡 一句话要点
提出激活引导方法,提升LLM在形式化定理证明中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 形式化定理证明 激活引导 推理干预 残差激活
📋 核心要点
- 现有方法难以精确解释非形式化数学提示,影响LLM生成形式化证明的准确性。
- 提出激活引导方法,通过调整LLM内部激活状态来优化证明构建过程,无需额外训练。
- 实验表明,该方法在采样和最佳优先搜索两种解码策略下均能提升形式化证明的生成性能。
📝 摘要(中文)
近年来,自动定理证明领域的研究利用大型语言模型(LLMs)将非形式化的数学陈述转化为形式化的证明。然而,非形式化的提示通常是模糊的,或者缺乏严格的逻辑结构,这使得模型难以精确地解释它们。虽然现有的方法取得了不错的性能,但我们对LLMs如何内部表示非形式化的提示,以及这些提示如何影响证明生成知之甚少。为了解决这个问题,我们探索了激活引导,这是一种推理时的干预方法,它识别与非形式化推理轨迹相关的残差激活中的线性方向,并调整它们以改进证明构建,而无需进行微调。这种机制还产生了关于推理如何在LLMs的激活空间中进行内部编码的可解释信息。我们测试了我们的方法,用于从已经形式化的定理生成形式化证明。我们的贡献是双重的:(1)一种新颖的基于激活的干预方法,用于指导LLMs中的证明合成;(2)证明了这种干预在两种解码策略(采样和最佳优先搜索)下都能提高性能,而无需任何进一步的训练。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在形式化定理证明中,由于非形式化提示的模糊性或缺乏严格逻辑结构,导致模型难以准确理解并生成正确证明的问题。现有方法虽然取得了一定的成果,但缺乏对LLM内部如何表示和处理这些非形式化提示的深入理解,从而限制了性能的进一步提升。
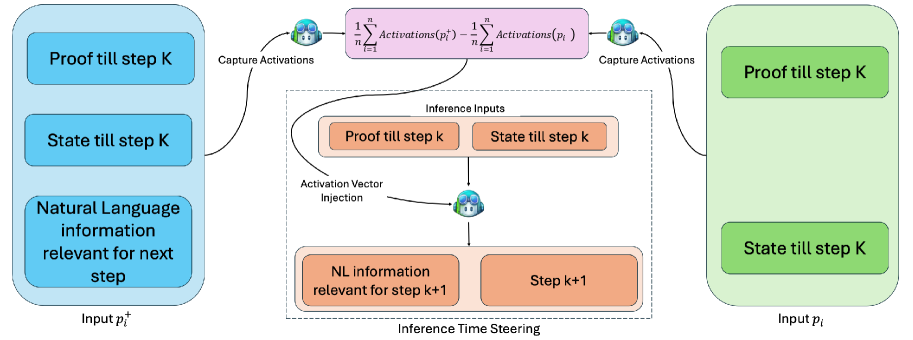
核心思路:论文的核心思路是通过激活引导(Activation Steering)来干预LLM的推理过程。具体来说,通过识别与非形式化推理相关的残差激活中的线性方向,并对其进行调整,从而引导LLM朝着更正确的证明方向前进。这种方法无需对LLM进行额外的训练,而是在推理阶段直接进行干预。
技术框架:该方法主要包含以下几个阶段:1) 收集非形式化推理轨迹的激活数据;2) 识别与这些轨迹相关的残差激活中的线性方向;3) 在推理过程中,根据识别出的线性方向调整LLM的激活状态,从而影响其输出;4) 使用采样或最佳优先搜索等解码策略生成形式化证明。
关键创新:该方法的关键创新在于提出了激活引导这一干预机制,它允许在不修改LLM参数的情况下,通过调整其内部激活状态来影响其推理过程。与传统的微调方法相比,激活引导更加灵活和高效,因为它不需要大量的训练数据和计算资源。此外,该方法还提供了一种理解LLM内部推理过程的途径,通过分析激活方向,可以了解LLM是如何表示和处理非形式化信息的。
关键设计:论文中关键的设计包括:如何有效地识别与非形式化推理相关的激活方向;如何确定调整激活状态的最佳策略;以及如何将激活引导与不同的解码策略相结合。具体的参数设置、损失函数和网络结构等技术细节在论文中可能没有详细描述,需要查阅原文以获取更具体的信息。
🖼️ 关键图片

📊 实验亮点
该研究提出了一种新颖的激活引导方法,无需额外训练即可提升LLM在形式化定理证明中的性能。实验结果表明,该方法在采样和最佳优先搜索两种解码策略下均能取得显著的性能提升。具体的性能数据和提升幅度需要在论文原文中查找。
🎯 应用场景
该研究成果可应用于自动定理证明、数学辅助教育、以及其他需要将非形式化知识转化为形式化表达的领域。通过提升LLM在形式化推理方面的能力,可以加速数学研究的进程,并为自动化知识发现提供新的工具。此外,该方法还可以推广到其他自然语言处理任务中,例如代码生成、文本摘要等。
📄 摘要(原文)
Recent advances in automated theorem proving use Large Language Models (LLMs) to translate informal mathematical statements into formal proofs. However, informal cues are often ambiguous or lack strict logical structure, making it hard for models to interpret them precisely. While existing methods achieve strong performance, little is known about how LLMs internally represent informal cues, or how these influence proof generation. To address this, we explore \textit{activation steering}, an inference-time intervention that identifies linear directions in residual activations associated with informal reasoning traces and adjusts them to improve proof construction without fine-tuning. This mechanism also yields interpretable information about how reasoning is internally encoded in the activation space of LLMs. We test our method for generating formal proofs from already-formalized theorems. Our contributions are twofold: (1) a novel activation-based intervention for guiding proof synthesis in LLMs; and (2) demonstration that this intervention improves performance under two decoding strategies (sampling and best-first search) without any further training.