Towards a Reward-Free Reinforcement Learning Framework for Vehicle Control
作者: Jielong Yang, Daoyuan Huang
分类: cs.LG
发布日期: 2025-02-21 (更新: 2025-04-18)
💡 一句话要点
提出一种免奖励强化学习框架,用于解决车辆控制中人工奖励设计偏差问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 免奖励强化学习 车辆控制 目标状态预测 策略网络 自动驾驶
📋 核心要点
- 车辆控制中的强化学习依赖人工设计的奖励函数,易引入人为偏差,且难以考虑所有因素。
- 提出免奖励强化学习框架,通过预测目标状态并引导策略学习,避免了对奖励函数的依赖。
- 实验表明,该框架在车辆控制中有效,提高了学习效率,并能适应免奖励环境。
📝 摘要(中文)
强化学习在车辆控制中发挥着关键作用,它通过设计或学习合适的奖励信号来引导智能体学习最优控制策略。然而,在车辆控制应用中,奖励通常需要手动设计,同时考虑多个隐性因素,这容易引入人为偏差。虽然模仿学习方法不依赖于显式奖励信号,但它们需要高质量的专家动作,而这通常难以获得。为了解决这些问题,我们提出了一种免奖励强化学习框架(RFRLF)。该框架通过目标状态预测网络(TSPN)和免奖励状态引导策略网络(RFSGPN)直接学习目标状态以优化智能体行为,避免了对人工设计的奖励信号的依赖。实验结果表明,所提出的RFRLF在控制车辆驾驶方面是有效的,显示了其在提高学习效率和适应免奖励环境方面的优势。
🔬 方法详解
问题定义:车辆控制中的强化学习通常依赖于精心设计的奖励函数,以引导智能体学习最优策略。然而,手动设计奖励函数是一个复杂的过程,需要考虑多个隐性因素,容易引入人为偏差,导致学习到的策略并非最优。此外,模仿学习虽然不需要奖励函数,但依赖于高质量的专家数据,而这些数据在实际场景中往往难以获取。
核心思路:该论文的核心思路是避免直接设计奖励函数,而是通过学习预测目标状态来引导策略学习。智能体不再根据奖励信号进行学习,而是通过最小化预测状态与专家状态之间的差异来优化策略。这种方法将学习目标从奖励最大化转变为状态匹配,从而避免了人为偏差。
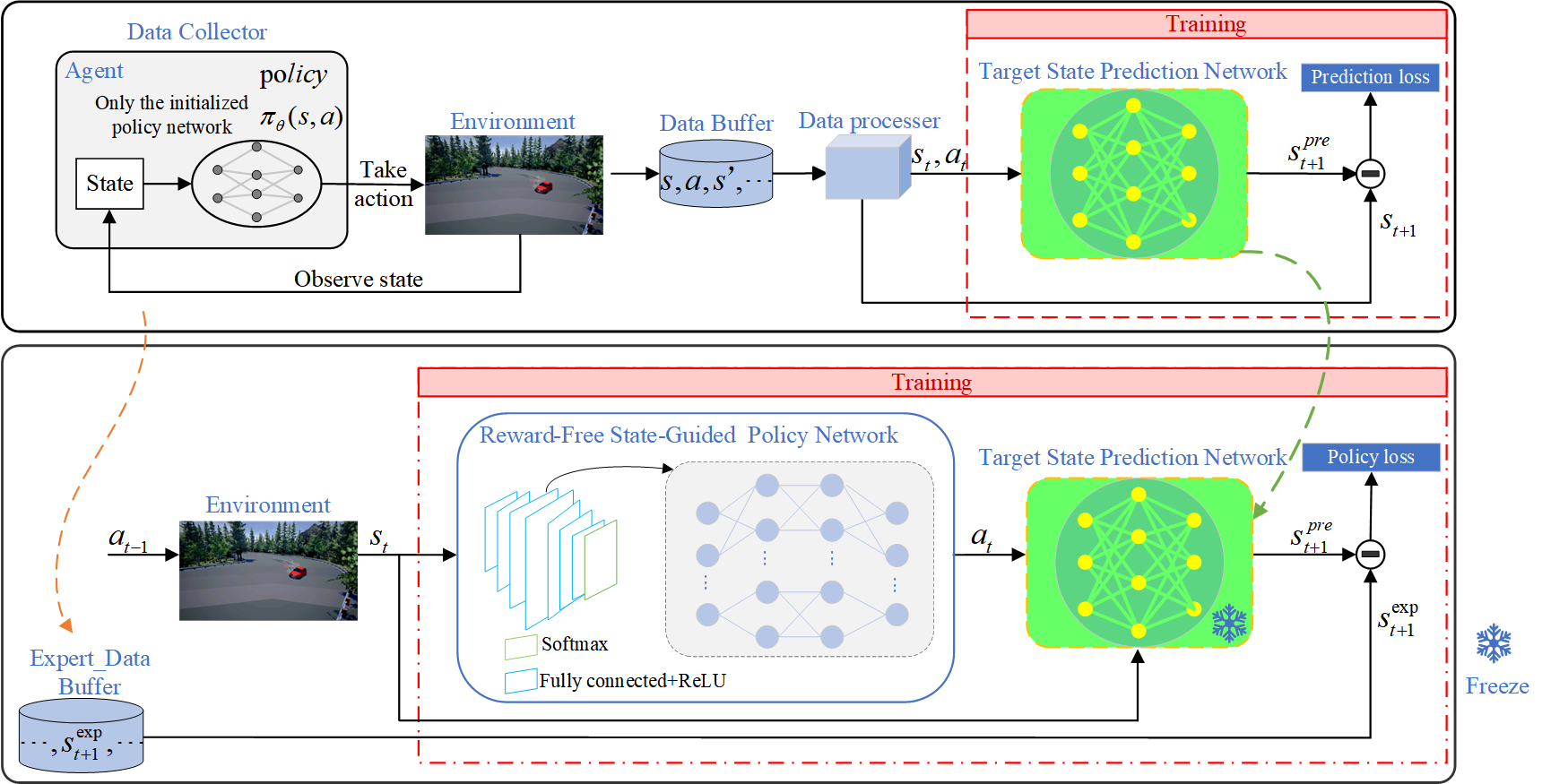
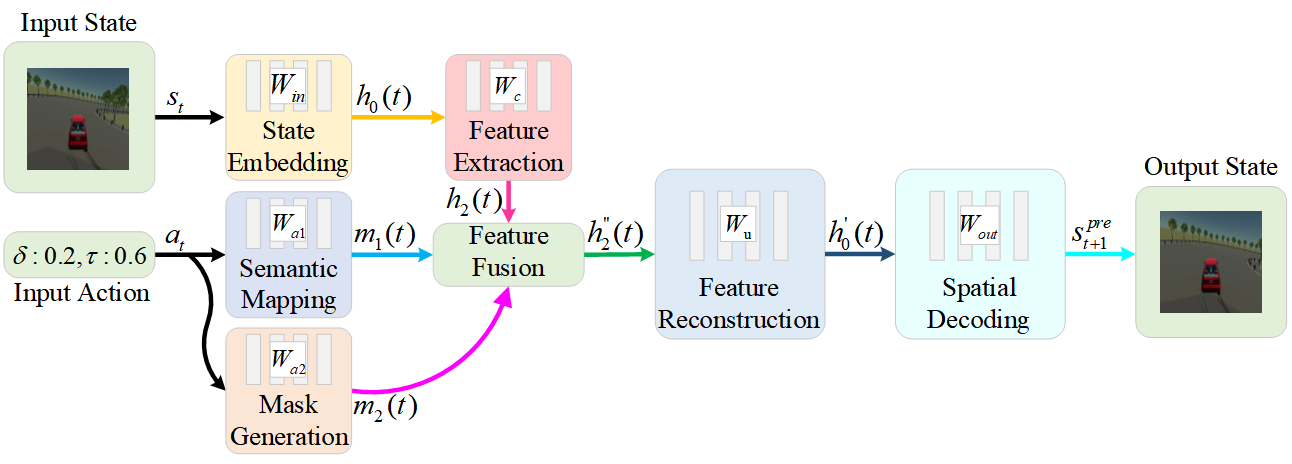
技术框架:该框架包含两个主要模块:目标状态预测网络(TSPN)和免奖励状态引导策略网络(RFSGPN)。TSPN负责预测给定状态下的目标状态,RFSGPN则根据当前状态和TSPN预测的目标状态,生成控制策略。整个学习过程通过最小化RFSGPN输出的状态与专家状态之间的差异来进行。
关键创新:该论文的关键创新在于提出了一个完全免奖励的强化学习框架,该框架不需要任何人工设计的奖励函数,而是通过学习预测目标状态来引导策略学习。这与传统的强化学习方法形成了鲜明对比,传统方法通常需要精心设计奖励函数才能获得良好的性能。
关键设计:TSPN可以使用各种回归模型,例如多层感知机或循环神经网络。RFSGPN可以使用Actor-Critic架构,其中Actor网络负责生成控制策略,Critic网络负责评估当前状态的价值。损失函数通常采用均方误差(MSE)来衡量预测状态与专家状态之间的差异。具体的网络结构和参数设置需要根据具体的车辆控制任务进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所提出的RFRLF在车辆控制任务中表现出色,无需人工设计的奖励函数即可学习到有效的控制策略。与传统的强化学习方法相比,RFRLF能够更快地收敛,并获得更高的性能。具体的数据指标(例如,平均速度、轨迹跟踪误差等)需要在论文中查找。
🎯 应用场景
该研究成果可应用于自动驾驶、无人车、智能交通等领域。通过免奖励学习,可以降低对人工经验的依赖,提高车辆控制系统的智能化水平和适应性。未来,该方法有望推广到更复杂的机器人控制任务中,实现更高效、更鲁棒的智能控制系统。
📄 摘要(原文)
Reinforcement learning plays a crucial role in vehicle control by guiding agents to learn optimal control strategies through designing or learning appropriate reward signals. However, in vehicle control applications, rewards typically need to be manually designed while considering multiple implicit factors, which easily introduces human biases. Although imitation learning methods does not rely on explicit reward signals, they necessitate high-quality expert actions, which are often challenging to acquire. To address these issues, we propose a reward-free reinforcement learning framework (RFRLF). This framework directly learns the target states to optimize agent behavior through a target state prediction network (TSPN) and a reward-free state-guided policy network (RFSGPN), avoiding the dependence on manually designed reward signals. Specifically, the policy network is learned via minimizing the differences between the predicted state and the expert state. Experimental results demonstrate the effectiveness of the proposed RFRLF in controlling vehicle driving, showing its advantages in improving learning efficiency and adapting to reward-free environments.