Less is More: Improving LLM Alignment via Preference Data Selection
作者: Xun Deng, Han Zhong, Rui Ai, Fuli Feng, Zheng Wang, Xiangnan He
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-02-20 (更新: 2025-06-14)
💡 一句话要点
通过偏好数据选择提升LLM对齐效果,解决DPO训练中的噪声数据问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 偏好学习 数据选择 大型语言模型 直接偏好优化 模型对齐
📋 核心要点
- DPO训练易受噪声数据影响,导致模型参数收缩,影响对齐效果。
- 提出边际最大化原则进行数据选择,并使用贝叶斯聚合降低奖励模型噪声。
- 实验表明,仅用10%数据即可在AlpacaEval2上提升3%-8%,且能提升迭代DPO效果。
📝 摘要(中文)
直接偏好优化(DPO)已成为一种很有前景的将大型语言模型与人类偏好对齐的方法。以往的工作主要从目标函数的角度扩展DPO,而本文则从很大程度上被忽视但至关重要的数据选择方面改进DPO。具体来说,我们通过为DPO训练中的数据集管理提出一种新的边际最大化原则,来解决由噪声数据引起的参数收缩问题。为了进一步减轻不同奖励模型中的噪声,我们提出了一种贝叶斯聚合方法,该方法将多个边际来源(外部和隐式)统一为单个偏好概率。在不同设置下进行的大量实验证明了我们方法始终如一的高数据效率。值得注意的是,仅使用Ultrafeedback数据集的10%,我们的方法在AlpacaEval2基准测试中,在各种Llama、Mistral和Qwen模型上实现了3%到8%的改进。此外,我们的方法无缝扩展到迭代DPO,使用25%的在线数据产生了大约3%的改进,揭示了这种假定的高质量数据构建方式中的高度冗余。这些结果突出了数据选择策略在推进偏好优化方面的潜力。
🔬 方法详解
问题定义:DPO(Direct Preference Optimization)方法在对齐大型语言模型与人类偏好时,容易受到训练数据中噪声的影响。这些噪声数据会导致模型参数的收缩,从而降低模型的性能和对齐效果。现有方法主要集中在优化目标函数上,而忽略了数据选择的重要性。
核心思路:本文的核心思路是通过精心选择高质量的偏好数据来提升DPO的训练效果。具体来说,论文提出了一种基于边际最大化原则的数据选择方法,旨在选择那些能够最大程度区分胜者和败者的偏好数据。同时,为了减轻不同奖励模型带来的噪声,采用贝叶斯聚合方法,将多个奖励模型的输出进行整合,得到更可靠的偏好概率。
技术框架:整体框架包含以下几个主要步骤:1) 使用多个奖励模型对数据进行打分;2) 基于边际最大化原则,选择高质量的偏好数据;3) 使用贝叶斯聚合方法整合多个奖励模型的输出,得到最终的偏好概率;4) 使用DPO算法在选择后的数据上训练LLM。
关键创新:论文的关键创新在于提出了基于边际最大化原则的数据选择方法和贝叶斯聚合方法。边际最大化原则能够有效地选择出信息量更大的偏好数据,从而提高训练效率和模型性能。贝叶斯聚合方法则能够有效地降低奖励模型中的噪声,提高偏好概率的准确性。
关键设计:边际最大化原则通过计算胜者和败者之间的奖励差异(margin)来评估数据的质量,选择margin较大的数据。贝叶斯聚合方法使用贝叶斯公式将多个奖励模型的输出进行整合,并考虑了每个奖励模型的可靠性。DPO训练过程使用标准的DPO损失函数,并在选择后的数据上进行优化。
🖼️ 关键图片
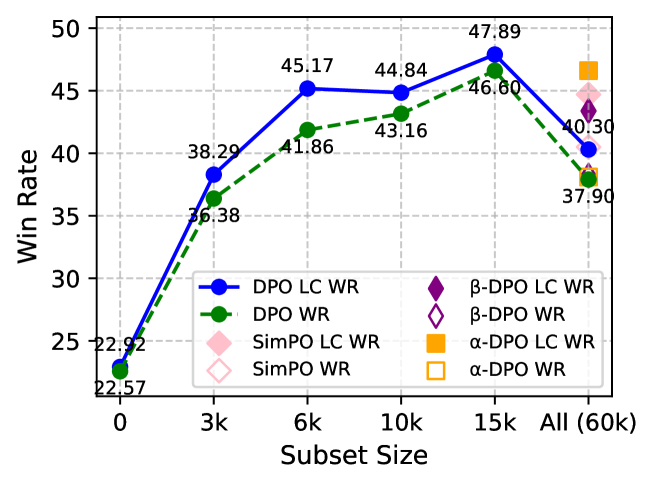
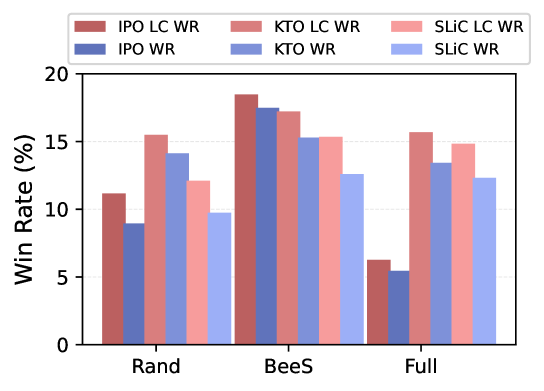

📊 实验亮点
实验结果表明,仅使用Ultrafeedback数据集的10%进行训练,该方法在AlpacaEval2基准测试中,在Llama、Mistral和Qwen等模型上实现了3%-8%的性能提升。此外,该方法还能有效提升迭代DPO的性能,使用25%的在线数据获得了约3%的改进,表明现有迭代DPO数据构建方式存在冗余。
🎯 应用场景
该研究成果可应用于各种需要将大型语言模型与人类偏好对齐的场景,例如对话系统、文本生成、代码生成等。通过选择高质量的偏好数据,可以提高模型的性能和对齐效果,从而提升用户体验。未来,该方法可以进一步扩展到其他偏好学习算法和数据类型。
📄 摘要(原文)
Direct Preference Optimization (DPO) has emerged as a promising approach for aligning large language models with human preferences. While prior work mainly extends DPO from the aspect of the objective function, we instead improve DPO from the largely overlooked but critical aspect of data selection. Specifically, we address the issue of parameter shrinkage caused by noisy data by proposing a novel margin-maximization principle for dataset curation in DPO training. To further mitigate the noise in different reward models, we propose a Bayesian Aggregation approach that unifies multiple margin sources (external and implicit) into a single preference probability. Extensive experiments in diverse settings demonstrate the consistently high data efficiency of our approach. Remarkably, by using just 10\% of the Ultrafeedback dataset, our approach achieves 3\% to 8\% improvements across various Llama, Mistral, and Qwen models on the AlpacaEval2 benchmark. Furthermore, our approach seamlessly extends to iterative DPO, yielding a roughly 3\% improvement with 25\% online data, revealing the high redundancy in this presumed high-quality data construction manner. These results highlight the potential of data selection strategies for advancing preference optimization.