S*: Test Time Scaling for Code Generation
作者: Dacheng Li, Shiyi Cao, Chengkun Cao, Xiuyu Li, Shangyin Tan, Kurt Keutzer, Jiarong Xing, Joseph E. Gonzalez, Ion Stoica
分类: cs.LG, cs.AI
发布日期: 2025-02-20
🔗 代码/项目: GITHUB
💡 一句话要点
提出S*框架,通过混合测试时扩展显著提升代码生成模型的覆盖率和选择准确率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 测试时扩展 大型语言模型 程序合成 自适应测试
📋 核心要点
- 现有代码生成模型在测试时计算扩展方面研究不足,限制了其性能上限,尤其是在复杂任务中。
- S*框架结合并行和顺序扩展,并利用自适应区分性输入和执行结果信息,提升代码选择的准确性。
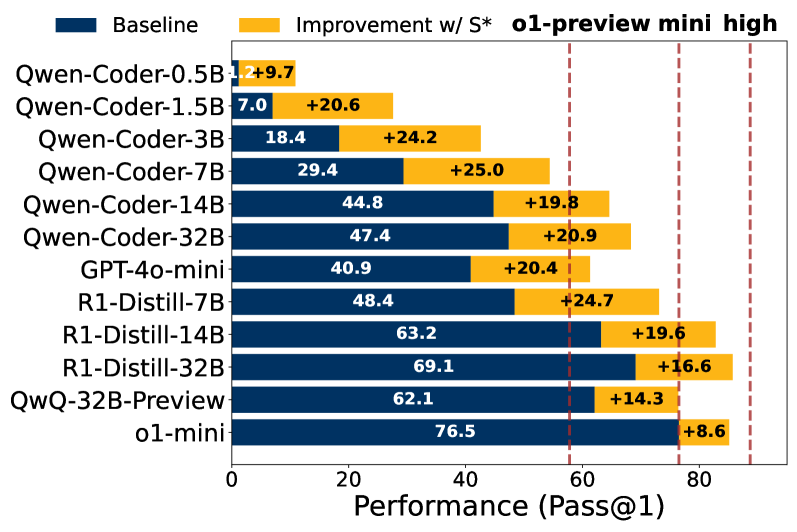
- 实验表明,S*能显著提升多种模型的代码生成性能,甚至使小模型超越大型推理模型。
📝 摘要(中文)
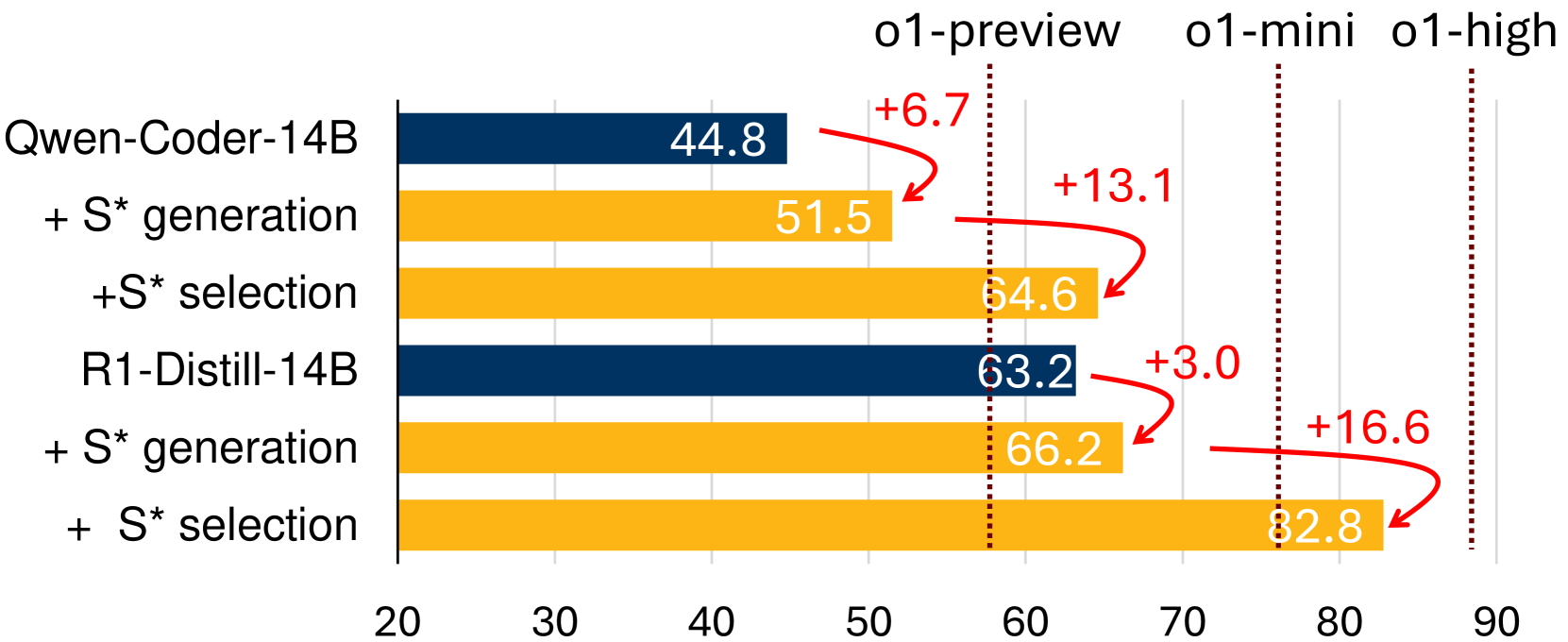
本文提出了一种名为S的混合测试时扩展框架,旨在显著提高生成代码的覆盖率和选择准确率。尽管在数学领域对测试时增加大型语言模型(LLM)的计算量进行了广泛研究,但在代码生成领域仍未得到充分探索。S通过结合并行扩展和顺序扩展来突破性能界限。此外,S还利用了一种新颖的选择机制,该机制自适应地生成区分性输入以进行成对比较,并结合执行结果信息来稳健地识别正确的解决方案。在12个大型语言模型和大型推理模型上的评估表明:(1)S始终如一地提高了各种模型系列和规模的性能,使一个3B模型能够胜过GPT-4o-mini;(2)S使非推理模型能够超越推理模型——在LiveCodeBench上,使用S的GPT-4o-mini比o1-preview高出3.7%;(3)S进一步提升了最先进的推理模型——使用S的DeepSeek-R1-Distill-Qwen-32B在LiveCodeBench上达到了85.7%,接近o1(high)的88.5%。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在代码生成任务中,测试时计算资源利用不足的问题。现有方法通常采用简单的并行扩展,无法充分挖掘模型的潜力,且代码选择机制不够鲁棒,容易受到噪声干扰。
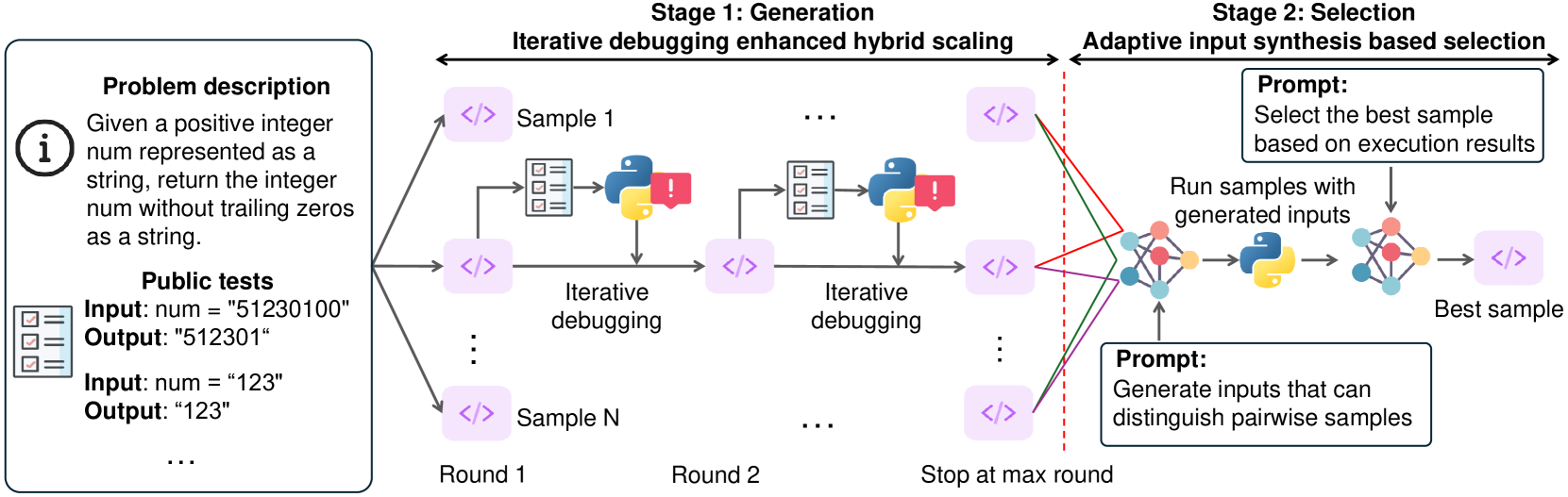
核心思路:S*的核心思路是结合并行扩展和顺序扩展,形成混合测试时扩展框架。并行扩展增加候选代码的多样性,顺序扩展则通过迭代优化,逐步逼近最优解。同时,设计自适应区分性输入,并结合执行结果信息,提高代码选择的准确性。
技术框架:S框架包含三个主要阶段:1) 并行生成:利用LLM并行生成多个候选代码片段。2) 顺序优化:对每个候选代码片段,通过生成区分性输入并执行,收集执行结果信息,进行迭代优化。3) 代码选择*:基于执行结果信息,选择最优的代码片段。
关键创新:S*的关键创新在于混合测试时扩展框架和自适应区分性输入生成机制。混合扩展充分利用计算资源,提高代码生成的多样性和质量。自适应区分性输入能够针对性地测试候选代码,提高代码选择的准确性。
关键设计:自适应区分性输入生成模块,通过分析候选代码的差异,生成能够区分这些代码的输入。代码选择模块,则基于执行结果的覆盖率、正确率等指标,选择最优的代码片段。具体的损失函数和网络结构等细节,论文中可能未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
S在多个代码生成基准测试中取得了显著的性能提升。例如,S使一个3B模型能够超越GPT-4o-mini,并且使用S的GPT-4o-mini在LiveCodeBench上比o1-preview高出3.7%。此外,使用S的DeepSeek-R1-Distill-Qwen-32B在LiveCodeBench上达到了85.7%,接近o1(high)的88.5%。
🎯 应用场景
S框架可应用于各种需要代码生成的场景,例如软件开发、自动化测试、AI编程助手等。通过提升代码生成的质量和效率,S能够降低开发成本,提高软件质量,并促进AI技术在软件工程领域的应用。未来,S*有望成为代码生成领域的重要技术手段。
📄 摘要(原文)
Increasing test-time compute for LLMs shows promise across domains but remains underexplored in code generation, despite extensive study in math. In this paper, we propose S, the first hybrid test-time scaling framework that substantially improves the coverage and selection accuracy of generated code. S extends the existing parallel scaling paradigm with sequential scaling to push performance boundaries. It further leverages a novel selection mechanism that adaptively generates distinguishing inputs for pairwise comparison, combined with execution-grounded information to robustly identify correct solutions. We evaluate across 12 Large Language Models and Large Reasoning Model and show: (1) S consistently improves performance across model families and sizes, enabling a 3B model to outperform GPT-4o-mini; (2) S enables non-reasoning models to surpass reasoning models - GPT-4o-mini with S outperforms o1-preview by 3.7% on LiveCodeBench; (3) S further boosts state-of-the-art reasoning models - DeepSeek-R1-Distill-Qwen-32B with S* achieves 85.7% on LiveCodeBench, approaching o1 (high) at 88.5%. Code will be available under https://github.com/NovaSky-AI/SkyThought.