A Survey of Sim-to-Real Methods in RL: Progress, Prospects and Challenges with Foundation Models
作者: Longchao Da, Justin Turnau, Thirulogasankar Pranav Kutralingam, Alvaro Velasquez, Paulo Shakarian, Hua Wei
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-02-18 (更新: 2025-03-08)
备注: 19 pages, 6 figures, 5 tables
💡 一句话要点
综述:基于强化学习的Sim-to-Real方法,探讨了在基础模型下的进展、前景与挑战。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Sim-to-Real 强化学习 深度学习 机器人 模拟环境 基础模型 马尔可夫决策过程
📋 核心要点
- 现有强化学习方法在真实世界应用中面临数据稀缺和试错成本高的挑战,导致策略学习主要依赖模拟环境。
- 该综述从马尔可夫决策过程的关键要素出发,对Sim-to-Real技术进行分类,并涵盖了经典方法和基于基础模型的方法。
- 论文总结了Sim-to-Real性能的评估流程,并讨论了该领域面临的挑战和机遇,旨在促进未来的研究探索。
📝 摘要(中文)
深度强化学习(RL)已被探索并验证在解决机器人、交通、推荐系统等各个领域的决策任务中是有效的。它通过与环境的交互进行学习,并使用收集到的经验更新策略。然而,由于真实世界数据的有限性以及采取有害行动带来的难以承受的后果,RL策略的学习主要限制在模拟器中。这种做法保证了学习的安全性,但也引入了部署中不可避免的sim-to-real差距,从而导致性能下降和执行风险。已经有一些尝试使用各种技术解决来自不同领域的sim-to-real问题,尤其是在大型基础模型或语言模型等新兴技术为sim-to-real带来曙光的时代。据我们所知,这篇综述论文是第一个正式地从马尔可夫决策过程的关键要素(状态、动作、转移和奖励)构建sim-to-real技术分类法的论文。基于该框架,我们涵盖了从经典方法到最先进方法的全面文献,包括由基础模型支持的sim-to-real技术,并且我们还讨论了在不同sim-to-real问题领域中值得关注的特性。然后,我们总结了使用可访问的代码或基准对sim-to-real性能进行正式评估的过程。同时,我们也提出了挑战和机遇,以鼓励未来对该方向的探索。我们正在积极维护一个存储库,以包含最新的sim-to-real研究工作,以帮助领域研究人员。
🔬 方法详解
问题定义:论文旨在解决强化学习中模拟环境训练的策略难以直接应用于真实世界的问题,即Sim-to-Real的差距。现有方法往往由于模拟环境与真实环境的差异,导致策略在真实环境中性能显著下降,甚至失效。痛点在于如何弥合这种差异,提高策略的泛化能力和鲁棒性。
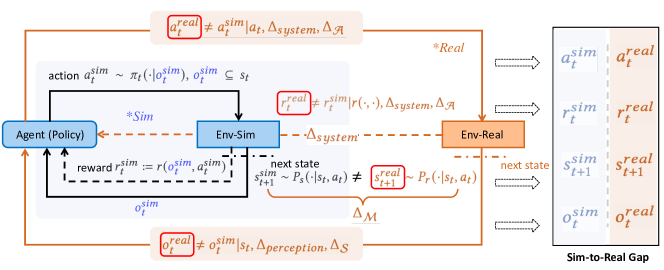
核心思路:论文的核心思路是从马尔可夫决策过程(MDP)的四个关键要素(状态、动作、转移、奖励)出发,对现有的Sim-to-Real技术进行分类和分析。通过这种分类,可以更清晰地理解不同方法在解决Sim-to-Real问题时的侧重点和优缺点。同时,关注新兴的基础模型在Sim-to-Real中的应用,探索其潜力。
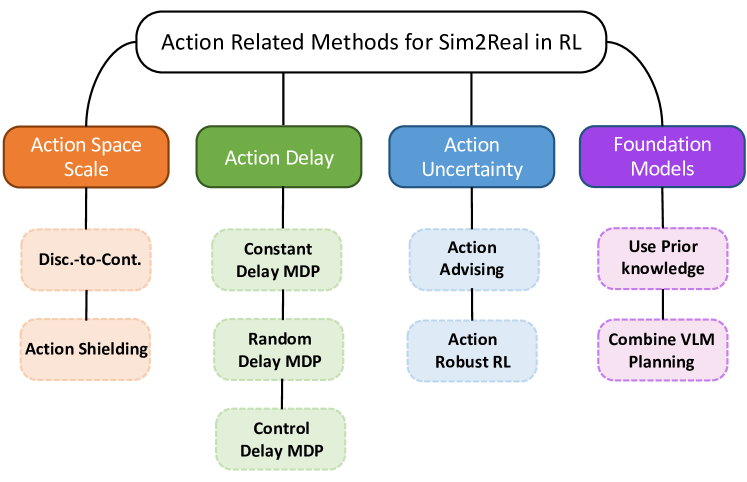
技术框架:该综述论文构建了一个Sim-to-Real技术的分类框架,该框架基于MDP的四个关键要素:状态(State)、动作(Action)、转移(Transition)和奖励(Reward)。论文对每个要素相关的Sim-to-Real技术进行了详细的梳理和分析,并讨论了不同领域Sim-to-Real问题的特殊性。此外,论文还总结了Sim-to-Real性能的评估流程,并维护一个包含最新研究工作的存储库。
关键创新:该综述的主要创新在于其分类框架,它将Sim-to-Real技术与MDP的关键要素联系起来,提供了一个系统化的视角来理解和比较不同的方法。此外,论文还关注了基础模型在Sim-to-Real中的应用,并探讨了其潜在的价值。这是首次正式地从马尔可夫决策过程的关键要素构建sim-to-real技术分类法的论文。
关键设计:论文的关键设计在于其分类框架,该框架能够帮助研究人员更好地理解Sim-to-Real问题的本质,并选择合适的方法来解决特定领域的问题。论文还对Sim-to-Real性能的评估流程进行了总结,为研究人员提供了一个参考标准。此外,论文维护的存储库能够帮助研究人员及时了解最新的研究进展。
🖼️ 关键图片
📊 实验亮点
该综述总结了Sim-to-Real性能的评估流程,并维护了一个包含最新研究工作的存储库,为领域研究人员提供了便利。同时,论文还关注了基础模型在Sim-to-Real中的应用,并探讨了其潜在的价值,为未来的研究方向提供了启示。
🎯 应用场景
该研究对机器人、自动驾驶、游戏AI等领域具有广泛的应用前景。通过弥合模拟环境与真实环境的差距,可以降低强化学习算法的开发成本和风险,加速其在实际场景中的部署。未来的影响包括更智能的机器人、更安全的自动驾驶系统和更逼真的游戏体验。
📄 摘要(原文)
Deep Reinforcement Learning (RL) has been explored and verified to be effective in solving decision-making tasks in various domains, such as robotics, transportation, recommender systems, etc. It learns from the interaction with environments and updates the policy using the collected experience. However, due to the limited real-world data and unbearable consequences of taking detrimental actions, the learning of RL policy is mainly restricted within the simulators. This practice guarantees safety in learning but introduces an inevitable sim-to-real gap in terms of deployment, thus causing degraded performance and risks in execution. There are attempts to solve the sim-to-real problems from different domains with various techniques, especially in the era with emerging techniques such as large foundations or language models that have cast light on the sim-to-real. This survey paper, to the best of our knowledge, is the first taxonomy that formally frames the sim-to-real techniques from key elements of the Markov Decision Process (State, Action, Transition, and Reward). Based on the framework, we cover comprehensive literature from the classic to the most advanced methods including the sim-to-real techniques empowered by foundation models, and we also discuss the specialties that are worth attention in different domains of sim-to-real problems. Then we summarize the formal evaluation process of sim-to-real performance with accessible code or benchmarks. The challenges and opportunities are also presented to encourage future exploration of this direction. We are actively maintaining a repository to include the most up-to-date sim-to-real research work to help domain researchers.