Identifiable Steering via Sparse Autoencoding of Multi-Concept Shifts
作者: Shruti Joshi, Andrea Dittadi, Sébastien Lachapelle, Dhanya Sridhar
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-02-14
备注: 27 pages, 9 figures
💡 一句话要点
提出稀疏移位自编码器,实现多概念变化下的可辨识语言模型操控
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型操控 稀疏自编码器 无监督学习 可辨识性 概念解耦
📋 核心要点
- 现有语言模型操控方法依赖于昂贵的监督数据,限制了研究速度和可扩展性。
- 提出稀疏移位自编码器(SSAE),通过学习嵌入差异的稀疏表示,实现无监督可辨识操控。
- 实验表明,SSAE在半合成和真实数据集上,能够准确操控Llama-3.1语言模型的特定概念。
📝 摘要(中文)
操控大型语言模型(LLM)的表示以诱导具有期望属性的响应(例如,真实性)是一种有前景的LLM对齐方法,无需微调。传统的操控依赖于监督,例如来自在单个目标概念上变化的对比提示对,这获取成本高昂并限制了操控研究的速度。一个有吸引力的替代方案是使用无监督方法,例如稀疏自编码器(SAE),将LLM嵌入映射到捕获人类可解释概念的稀疏表示。然而,如果没有进一步的假设,SAE可能无法被识别:它们可能学习到纠缠多个概念的潜在维度,导致对不相关属性的意外操控。我们引入了稀疏移位自编码器(SSAE),它将嵌入之间的差异映射到稀疏表示。至关重要的是,我们证明了SSAE可以从在多个未知概念上变化的配对观察中识别,从而实现对单个概念的准确操控,而无需监督。我们使用Llama-3.1嵌入,在半合成和真实世界的语言数据集上进行了准确操控的实证演示。
🔬 方法详解
问题定义:现有基于稀疏自编码器(SAE)的语言模型操控方法,在没有额外假设的情况下,可能无法学习到可解释的、解耦的概念表示。这导致潜在维度纠缠多个概念,使得操控单个目标概念时,可能会意外影响其他不相关的属性。因此,如何实现无监督且可辨识的语言模型操控,避免概念纠缠,是本文要解决的核心问题。
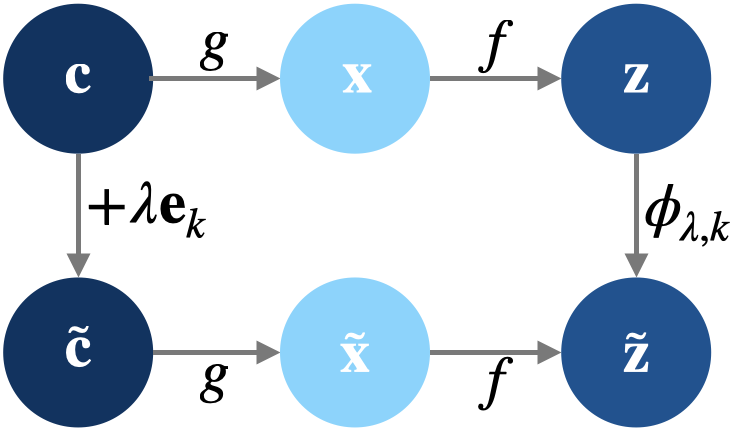
核心思路:本文的核心思路是利用嵌入之间的差异(即“移位”)来学习稀疏表示。作者认为,如果两个嵌入在多个未知概念上存在差异,那么学习这些差异的稀疏表示,可以更容易地解耦不同的概念。通过将SAE应用于嵌入差异,而非直接应用于嵌入本身,可以提高表示的可辨识性,从而实现更精确的操控。
技术框架:SSAE的技术框架主要包含以下几个步骤:1. 收集或生成在多个概念上存在差异的嵌入对。2. 计算每对嵌入之间的差异向量。3. 使用稀疏自编码器(SAE)学习这些差异向量的稀疏表示。4. 使用学习到的稀疏表示来操控语言模型的行为,例如,通过修改模型的中间层激活值。
关键创新:本文最重要的技术创新点在于提出了稀疏移位自编码器(SSAE),并证明了SSAE可以从在多个未知概念上变化的配对观察中识别。与传统的SAE相比,SSAE不是直接学习嵌入的稀疏表示,而是学习嵌入差异的稀疏表示。这种方法能够更好地解耦不同的概念,提高表示的可辨识性,从而实现更精确的操控。
关键设计:SSAE的关键设计包括:1. 使用L1正则化来鼓励稀疏性。2. 选择合适的自编码器结构,例如,使用线性解码器。3. 设计合适的损失函数,例如,重构损失加上稀疏性惩罚项。4. 实验中使用了Llama-3.1的嵌入,并针对不同的数据集和任务,调整了SAE的超参数。
🖼️ 关键图片

📊 实验亮点
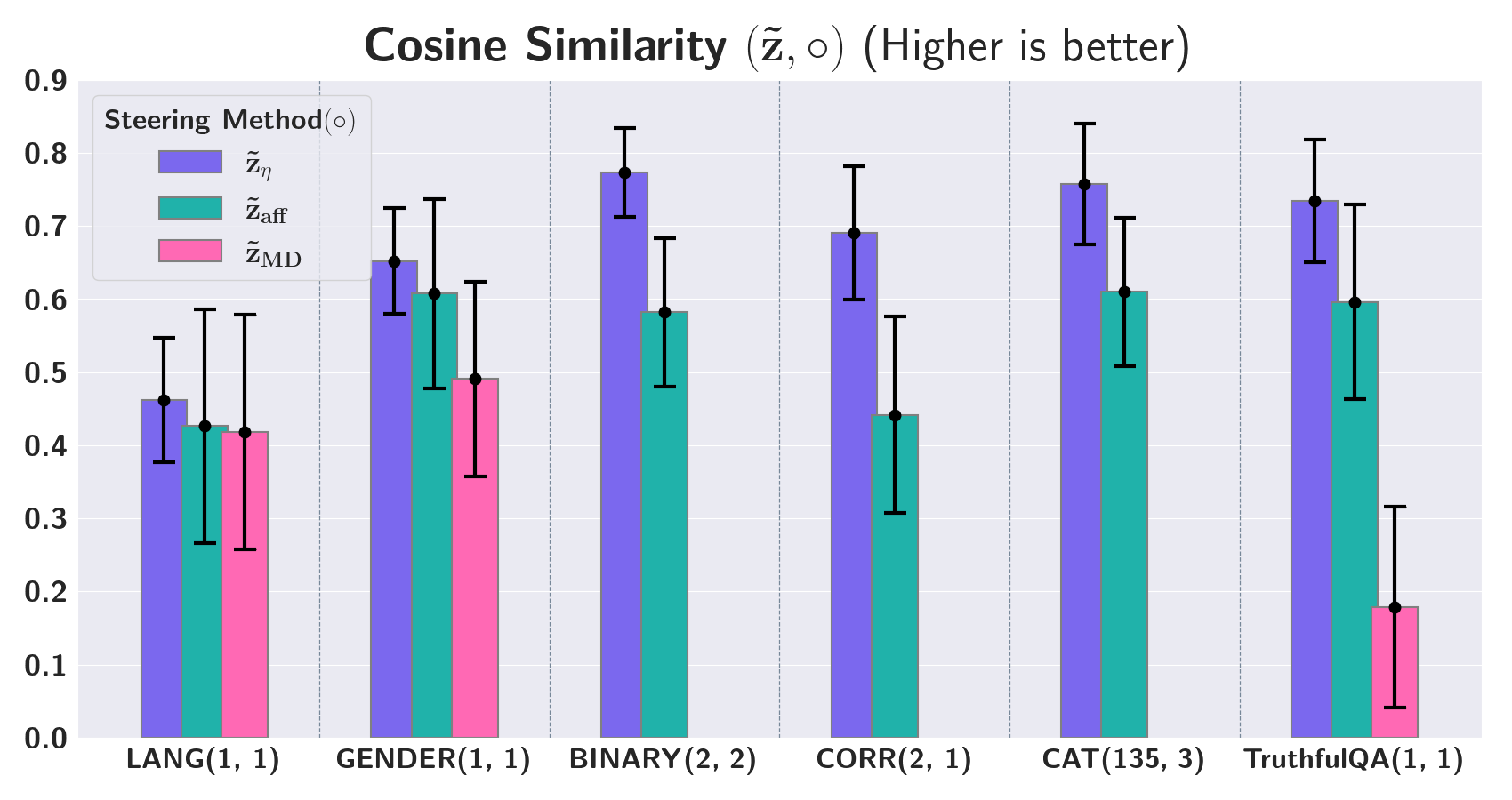
实验结果表明,SSAE能够在半合成和真实世界的语言数据集上实现准确的操控。例如,在truthfulQA数据集上,SSAE能够有效地提高Llama-3.1的真实性,同时避免对其他属性产生负面影响。与传统的SAE相比,SSAE在操控精度和可辨识性方面均有显著提升。
🎯 应用场景
该研究成果可应用于语言模型对齐、内容生成控制、模型可解释性分析等领域。例如,可以利用SSAE操控语言模型生成更真实、更符合道德规范的文本,或者控制生成文本的情感倾向。此外,SSAE学习到的稀疏表示可以帮助我们理解语言模型内部的知识表示方式,提高模型的可解释性。
📄 摘要(原文)
Steering methods manipulate the representations of large language models (LLMs) to induce responses that have desired properties, e.g., truthfulness, offering a promising approach for LLM alignment without the need for fine-tuning. Traditionally, steering has relied on supervision, such as from contrastive pairs of prompts that vary in a single target concept, which is costly to obtain and limits the speed of steering research. An appealing alternative is to use unsupervised approaches such as sparse autoencoders (SAEs) to map LLM embeddings to sparse representations that capture human-interpretable concepts. However, without further assumptions, SAEs may not be identifiable: they could learn latent dimensions that entangle multiple concepts, leading to unintentional steering of unrelated properties. We introduce Sparse Shift Autoencoders (SSAEs) that instead map the differences between embeddings to sparse representations. Crucially, we show that SSAEs are identifiable from paired observations that vary in \textit{multiple unknown concepts}, leading to accurate steering of single concepts without the need for supervision. We empirically demonstrate accurate steering across semi-synthetic and real-world language datasets using Llama-3.1 embeddings.