MixMin: Finding Data Mixtures via Convex Minimization
作者: Anvith Thudi, Evianne Rovers, Yangjun Ruan, Tristan Thrush, Chris J. Maddison
分类: cs.LG, stat.ML
发布日期: 2025-02-14 (更新: 2026-01-15)
备注: Proceedings of the 42nd International Conference on Machine Learning
💡 一句话要点
MixMin:通过凸优化寻找最优数据混合比例,提升模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据混合 凸优化 双层优化 梯度下降 语言建模 化学信息学 模型训练 机器学习
📋 核心要点
- 现有数据混合方法难以找到最优比例,尤其是在模型规模增大时,优化目标变得复杂且难以处理。
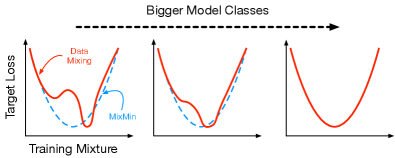
- MixMin的核心思想是利用模型类别增大时,数据混合的双层优化目标会变为凸函数的特性,从而可以使用梯度下降法进行优化。
- 实验表明,MixMin在语言建模和化学任务上均能有效提升模型性能,且找到的混合比例具有一定的尺度不变性。
📝 摘要(中文)
现代机器学习流程越来越多地结合来自不同来源的数据,例如预训练大型语言模型。然而,找到最佳的数据混合比例仍然是一个具有挑战性的开放问题。本文将数据混合问题形式化为一个双层优化目标:最佳混合比例是能够为下游任务带来最佳模型的比例。不幸的是,这个目标通常难以处理。本文观察到,随着模型类别的增大,双层数据混合目标会变为凸函数。我们开发并研究了一种基于梯度的凸优化方法,称之为MixMin,并在语言建模和化学任务上进行了测试。MixMin是唯一在所有实验中一致改进数据混合的方法。对于在82亿tokens上训练的pythia-410M模型,使用MixMin改进数据混合仅需不到0.2%的额外计算量,即可在PIQA、ARC Easy、SciQ和OpenWebMath上实现1-5%的负对数似然相对改进。关键的是,我们发现MixMin为较小模型找到的混合比例可以改善较大模型的训练,表明MixMin混合比例可能具有尺度不变性。在混合生物测定数据以训练XGBoost模型时,我们观察到平均精度得分提高了0.03-0.15。
🔬 方法详解
问题定义:论文旨在解决如何找到最优的数据混合比例的问题,尤其是在预训练大型模型时,不同来源的数据质量和数量差异很大,如何有效地利用这些数据是一个挑战。现有方法通常依赖于启发式规则或手动调整,缺乏理论指导,难以找到全局最优解。
核心思路:论文的核心思路是,当模型类别足够大时,数据混合的双层优化问题会变成凸优化问题。这意味着存在一个全局最优解,并且可以使用梯度下降等方法进行求解。通过优化数据混合比例,可以使得模型在下游任务上获得更好的性能。
技术框架:MixMin方法主要包含以下几个阶段:1) 定义双层优化目标,其中上层目标是下游任务的性能,下层目标是模型的训练损失。2) 利用模型类别增大时,双层优化目标变为凸函数的性质。3) 使用梯度下降法优化数据混合比例,使得下游任务的性能最大化。4) 在验证集上评估不同混合比例的模型性能,选择最优的混合比例。
关键创新:MixMin的关键创新在于发现了数据混合问题在特定条件下(模型类别足够大)具有凸性,从而可以将一个复杂的双层优化问题转化为一个相对简单的凸优化问题。这使得可以使用梯度下降等方法高效地求解最优的数据混合比例。
关键设计:MixMin的关键设计包括:1) 使用负对数似然作为语言建模任务的损失函数。2) 使用平均精度作为化学任务的评估指标。3) 使用梯度下降法优化数据混合比例,并设置合适的学习率和迭代次数。4) 在实验中,作者探索了不同的模型规模和数据集,验证了MixMin的有效性和泛化能力。
🖼️ 关键图片

📊 实验亮点
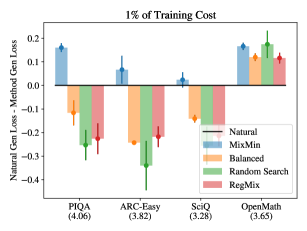
MixMin在语言建模任务中,使用不到0.2%的额外计算量,即可在PIQA、ARC Easy、SciQ和OpenWebMath等数据集上实现1-5%的负对数似然相对改进。此外,MixMin为较小模型找到的混合比例可以改善较大模型的训练,表明MixMin混合比例可能具有尺度不变性。在化学任务中,MixMin将XGBoost模型的平均精度得分提高了0.03-0.15。
🎯 应用场景
MixMin可应用于各种需要混合不同来源数据的机器学习任务,例如大型语言模型的预训练、多模态学习、联邦学习等。通过优化数据混合比例,可以提升模型的性能和泛化能力,降低训练成本,并更好地利用现有的数据资源。该方法具有广泛的应用前景,可以为机器学习模型的开发和部署提供有力的支持。
📄 摘要(原文)
Modern machine learning pipelines are increasingly combining and mixing data from diverse and disparate sources, e.g., pre-training large language models. Yet, finding the optimal data mixture is a challenging and open problem. We formalize this data mixing problem as a bi-level objective: the best mixture is the one that would lead to the best model for a downstream objective. Unfortunately, this objective is generally intractable. In this paper, we make the observation that the bi-level data mixing objective becomes convex as our model class becomes larger. We develop and study a gradient-based approach for optimizing this convex objective, which we call MixMin, and test it on language modeling and chemistry tasks. MixMin was the only method that uniformly improved the data mixture in all our experiments. With MixMin, we improved the data mixture using less than 0.2% additional compute for a pythia-410M model trained on 8.2B tokens, resulting between 1-5% relative improvement to negative log likelihood on PIQA, ARC Easy, SciQ, and OpenWebMath. Crucially, we found that MixMin mixtures for smaller models improved training of larger models, suggesting that MixMin mixtures may be scale-invariant. When mixing bioassay data to train an XGBoost model, we saw improvements to average precision scores of 0.03-0.15.