Accelerated Parallel Tempering via Neural Transports
作者: Leo Zhang, Peter Potaptchik, Jiajun He, Yuanqi Du, Arnaud Doucet, Francisco Vargas, Hai-Dang Dau, Saifuddin Syed
分类: stat.ML, cs.LG
发布日期: 2025-02-14 (更新: 2025-09-27)
💡 一句话要点
利用神经传输加速并行退火算法,提升复杂分布采样效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 并行退火 神经采样器 归一化流 扩散模型 蒙特卡洛方法 多模态分布 自由能估计
📋 核心要点
- 传统并行退火算法在处理复杂分布时,相邻分布重叠小,导致采样效率降低,计算成本高。
- 该论文提出利用神经采样器学习分布间的传输,减少相邻分布的重叠需求,从而加速并行退火算法。
- 实验证明,该方法在多模态采样问题上,提高了样本质量,降低了计算成本,并能有效估计自由能。
📝 摘要(中文)
马尔可夫链蒙特卡洛(MCMC)算法是计算统计中从非归一化概率分布中采样的重要工具,但当目标分布是高维、多模态或复杂时,MCMC算法可能变得脆弱。并行退火(PT)通过退火和并行计算来提高MCMC的采样效率,通过在插值分布之间交换状态,将样本从易处理的参考分布传播到难处理的目标分布。PT的有效性受到相邻分布之间重叠通常很小的限制,这需要增加计算资源来补偿。我们引入了一个框架,通过利用神经采样器(包括归一化流、扩散模型和受控扩散)来减少所需的重叠,从而加速PT。我们的方法并行使用神经采样器,规避了神经采样器的计算负担,同时保留了经典PT的渐近一致性。我们在各种多模态采样问题上进行了理论和实证证明,表明我们的方法提高了样本质量,降低了计算成本,并实现了高效的自由能/归一化常数估计。
🔬 方法详解
问题定义:论文旨在解决传统并行退火(PT)算法在处理高维、多模态等复杂目标分布时,由于相邻温度分布重叠度低,导致采样效率低下和计算成本高昂的问题。现有PT方法需要增加计算资源来弥补分布重叠不足,限制了其在实际问题中的应用。
核心思路:论文的核心思路是利用神经采样器(如归一化流、扩散模型)学习相邻温度分布之间的传输映射,从而人为地增大分布之间的重叠度。通过更有效的状态交换,加速样本从易处理的参考分布向复杂目标分布的迁移,最终提升PT算法的整体采样效率。
技术框架:该方法的核心是利用多个神经采样器并行地学习不同温度下的分布传输。整体流程如下:1) 初始化一系列温度,定义一系列插值分布;2) 并行训练多个神经采样器,每个采样器学习相邻温度分布之间的映射;3) 在PT算法的状态交换步骤中,利用训练好的神经采样器进行状态转移,提高交换效率;4) 最终从目标温度的分布中采样。
关键创新:该方法最重要的创新在于将神经采样器引入到并行退火算法中,并以并行的方式使用这些采样器,从而在不显著增加计算负担的前提下,有效地增大了相邻分布的重叠度。与直接使用神经采样器进行采样相比,该方法保留了经典PT算法的渐近一致性,保证了采样的可靠性。
关键设计:关键设计包括:1) 选择合适的神经采样器架构(如归一化流、扩散模型),并根据具体问题进行调整;2) 设计合适的损失函数,用于训练神经采样器,例如可以使用KL散度或Wasserstein距离来衡量生成分布与目标分布之间的差异;3) 合理设置温度序列,以保证相邻分布之间存在一定的重叠度,方便神经采样器学习分布间的映射。
🖼️ 关键图片
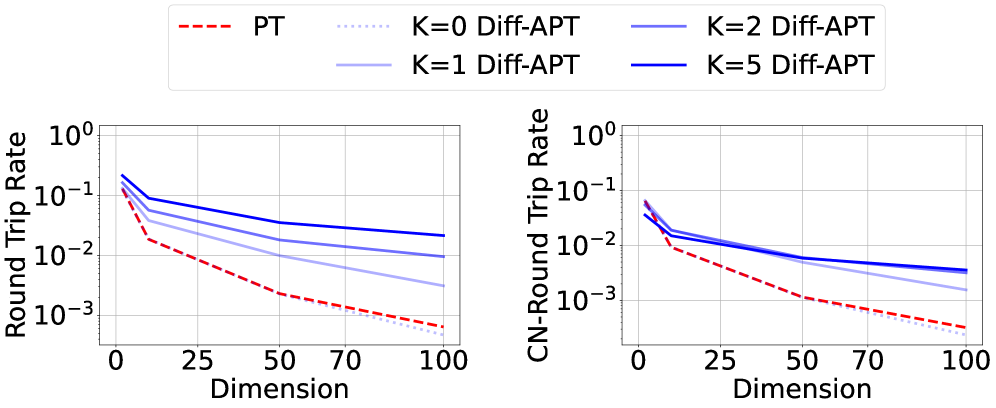
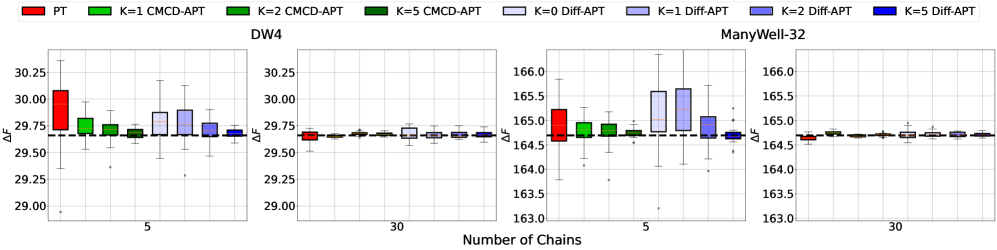
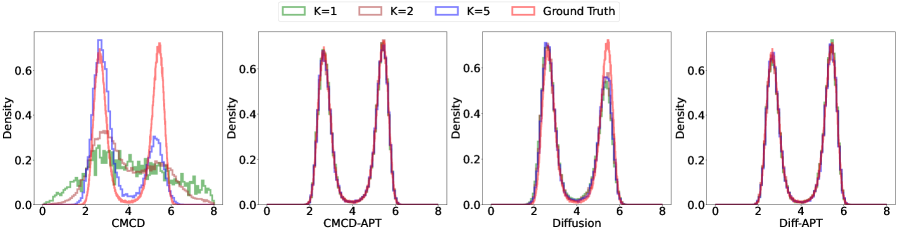
📊 实验亮点
实验结果表明,该方法在多种多模态采样问题上,相比传统并行退火算法,能够显著提高采样效率和样本质量。具体而言,该方法能够以更低的计算成本获得更好的样本分布,并能更准确地估计自由能和归一化常数。性能提升幅度取决于具体问题和神经采样器的选择。
🎯 应用场景
该研究成果可广泛应用于计算统计、机器学习、物理模拟等领域,尤其是在需要从复杂概率分布中采样的场景,例如贝叶斯推断、分子动力学模拟、生成对抗网络训练等。通过提高采样效率,该方法能够加速模型训练和参数估计,从而推动相关领域的发展。
📄 摘要(原文)
Markov Chain Monte Carlo (MCMC) algorithms are essential tools in computational statistics for sampling from unnormalised probability distributions, but can be fragile when targeting high-dimensional, multimodal, or complex target distributions. Parallel Tempering (PT) enhances MCMC's sample efficiency through annealing and parallel computation, propagating samples from tractable reference distributions to intractable targets via state swapping across interpolating distributions. The effectiveness of PT is limited by the often minimal overlap between adjacent distributions in challenging problems, which requires increasing the computational resources to compensate. We introduce a framework that accelerates PT by leveraging neural samplers -- including normalising flows, diffusion models, and controlled diffusions -- to reduce the required overlap. Our approach utilises neural samplers in parallel, circumventing the computational burden of neural samplers while preserving the asymptotic consistency of classical PT. We demonstrate theoretically and empirically on a variety of multimodal sampling problems that our method improves sample quality, reduces the computational cost compared to classical PT, and enables efficient free energy/normalising constant estimation.