Efficient Zero-Order Federated Finetuning of Language Models for Resource-Constrained Devices
作者: Mohamed Aboelenien Ahmed, Kilian Pfeiffer, Ramin Khalili, Heba Khdr, Jörg Henkel
分类: cs.LG, cs.AI
发布日期: 2025-02-14 (更新: 2025-12-17)
💡 一句话要点
提出高效零阶联邦微调方法,加速资源受限设备上LLM的微调收敛。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 零阶优化 语言模型微调 边缘计算 资源受限设备
📋 核心要点
- 现有联邦微调LLM方法在边缘设备上计算开销大,收敛速度慢,限制了其应用。
- 论文提出一种新的零阶联邦微调方法,通过差异化扰动策略加速收敛。
- 实验结果表明,该方法在计算开销上优于现有零阶方法,提升显著。
📝 摘要(中文)
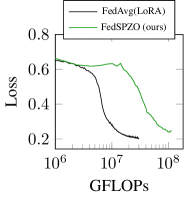
联邦微调为在边缘设备上调整大型语言模型(LLM)提供了一种有前景的方法,同时保护数据隐私。然而,由于高内存、通信和计算需求,在边缘设备上微调这些模型仍然具有挑战性。具有任务对齐的零阶优化提供了一种潜在的解决方案,它能够以推理级别的内存需求进行微调,但需要更长的收敛时间。在本文中,我们提出了一种方法,该方法将网络划分为两个块,对每个块应用不同数量的扰动,以一种计算有效的方式实现更快的收敛。我们的评估表明,与联邦学习中最先进的零阶技术相比,计算开销降低了1.6-3倍。
🔬 方法详解
问题定义:论文旨在解决在资源受限的边缘设备上,对大型语言模型进行联邦微调时,计算开销过大和收敛速度慢的问题。现有的零阶优化方法虽然降低了内存需求,但收敛速度较慢,导致整体效率不高。
核心思路:论文的核心思路是将模型参数划分为不同的块,并对不同的块应用不同数量的扰动。通过这种差异化的扰动策略,可以在保证模型性能的同时,有效地减少计算开销,并加速收敛。
技术框架:该方法将神经网络分为两个块。具体流程包括:1. 客户端本地数据训练;2. 对模型参数进行分块;3. 对不同块应用不同数量的扰动;4. 将更新后的模型参数上传到服务器;5. 服务器进行联邦平均;6. 将平均后的模型参数下发到客户端。
关键创新:该方法最重要的创新点在于提出了差异化扰动策略,即根据模型不同部分的特性,应用不同数量的扰动。这种策略能够更有效地利用计算资源,并加速模型的收敛。与现有方法相比,该方法在计算效率和收敛速度上都有显著提升。
关键设计:论文的关键设计包括如何选择划分模型的块,以及如何确定每个块的扰动数量。这些参数的选择需要根据具体的模型和任务进行调整,以达到最佳的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,与现有的零阶联邦学习技术相比,该方法在计算开销上降低了1.6-3倍。这意味着在相同的计算资源下,该方法能够更快地完成模型微调,或者在更少的计算资源下达到相同的模型性能。这一结果表明该方法在资源受限的边缘设备上具有显著的优势。
🎯 应用场景
该研究成果可应用于各种边缘计算场景,例如智能手机、物联网设备等,实现个性化的语言模型微调,提升用户体验。例如,可以用于在用户本地设备上微调语音助手模型,使其更好地理解用户的语音指令,或者用于在智能家居设备上微调文本生成模型,使其能够生成更符合用户需求的文本内容。该方法降低了计算开销,使得在资源受限设备上部署大型语言模型成为可能。
📄 摘要(原文)
Federated fine-tuning offers a promising approach for tuning Large Language Models (LLMs) on edge devices while preserving data privacy. However, fine-tuning these models on edge devices remains challenging due to high memory, communication, and computational demands. Zero-order optimization with task alignment provides a potential solution, enabling fine-tuning with inference-level memory requirements but requires a longer convergence time. In this paper, we propose \ac{METHOD} that divides the network into two blocks, applying a different number of perturbations per block in a computationally effective way, achieving faster convergence. Our evaluation shows a $1.6-3\times$ reduction in computation overhead compared to zero-order state of the art techniques in federated learning.