GoRA: Gradient-driven Adaptive Low Rank Adaptation
作者: Haonan He, Peng Ye, Yuchen Ren, Yuan Yuan, Luyang Zhou, Shucun Ju, Lei Chen
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-02-13 (更新: 2025-10-24)
备注: NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出GoRA以解决LoRA在适应性和初始化上的不足问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低秩适应 模型微调 梯度优化 自适应算法 大型语言模型 效率提升
📋 核心要点
- 现有的LoRA方法在秩选择和权重初始化上存在局限,影响了微调效果和计算效率。
- GoRA通过同时适应秩和初始化策略,利用梯度信息动态优化,提升了适应性和效率。
- 实验结果显示,GoRA在数学推理任务中较标准LoRA提升了5.13分,且在高秩设置下超越了完全微调的效果。
📝 摘要(中文)
低秩适应(LoRA)是高效微调大型语言模型(LLMs)的关键方法,其有效性受秩选择和权重初始化两个关键因素的影响。尽管已有多种LoRA变体被提出以改善性能,但通常会妥协可用性或计算效率。本文分析了现有方法的核心局限性,并提出了一种新颖的框架——GoRA(基于梯度的自适应低秩适应),该框架在统一的框架内同时适应秩和初始化策略。GoRA在训练过程中利用梯度信息动态分配最优秩,并以自适应方式初始化低秩适配器权重。GoRA是首个在单一框架内统一处理秩选择和初始化的算法,显著提高了适应效果和效率。大量实验表明,GoRA在多种架构和模态下均优于现有的基于LoRA的方法,同时保持了原始LoRA的效率。
🔬 方法详解
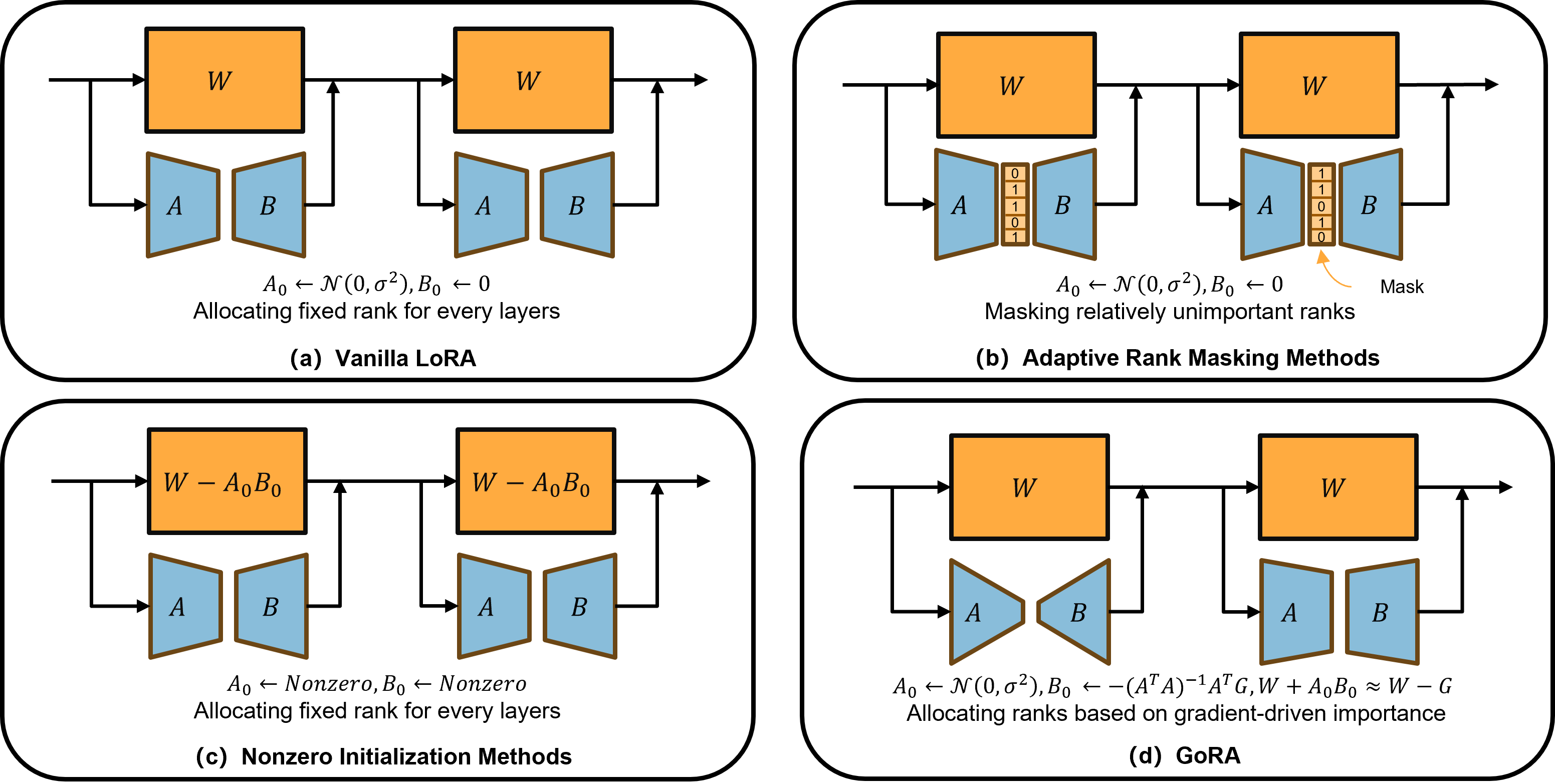
问题定义:本文旨在解决现有低秩适应方法在秩选择和权重初始化上的不足,导致微调效果不佳和计算效率低下的问题。
核心思路:GoRA的核心思路是通过利用训练过程中的梯度信息,动态调整适应的秩和初始化策略,从而实现更高效的模型微调。
技术框架:GoRA的整体架构包括两个主要模块:一是基于梯度信息的动态秩分配模块,二是自适应权重初始化模块。这两个模块协同工作,确保在训练过程中实时优化模型参数。
关键创新:GoRA的最大创新在于首次将秩选择和初始化策略统一在一个框架内,解决了以往方法各自为政的问题,从而提高了适应效果和效率。
关键设计:在参数设置上,GoRA根据梯度信息动态调整秩的大小,并使用特定的损失函数来优化权重初始化,确保模型在不同任务中的适应性和性能。具体的网络结构和训练流程也经过精心设计,以支持这一动态调整机制。
🖼️ 关键图片
📊 实验亮点
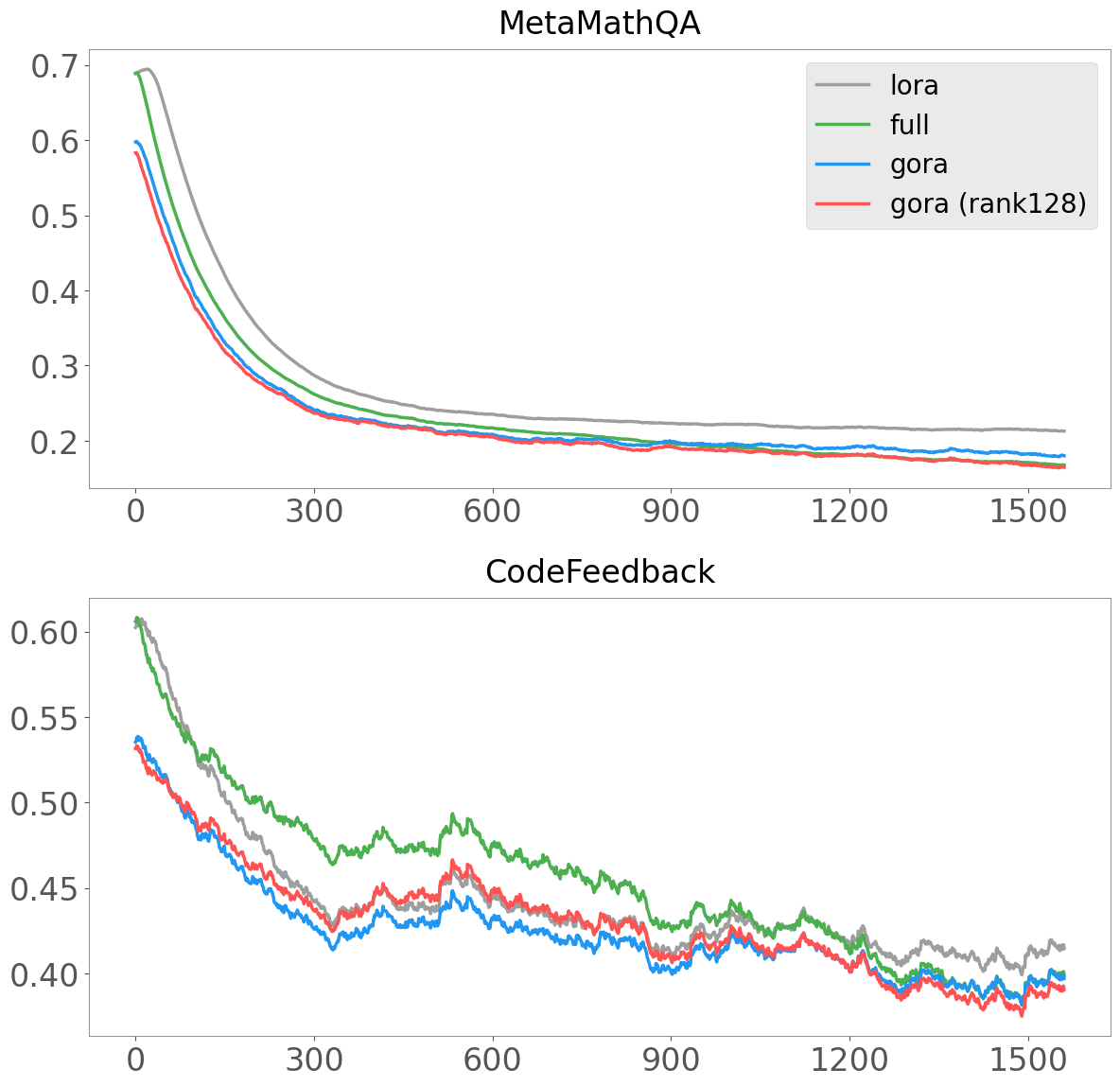
在实验中,GoRA在微调Llama3.1-8B-Base模型进行数学推理时,相较于标准LoRA提升了5.13分,并在高秩设置下超越了完全微调的效果,提升幅度达到2.05分,显示出其卓越的性能。
🎯 应用场景
GoRA的研究成果在大型语言模型的微调中具有广泛的应用潜力,尤其是在需要高效适应不同任务的场景中,如自然语言处理、机器翻译和对话系统等。其自适应的特性将为未来的模型训练提供更灵活的解决方案,推动智能系统的进一步发展。
📄 摘要(原文)
Low-Rank Adaptation (LoRA) is a crucial method for efficiently fine-tuning large language models (LLMs), with its effectiveness influenced by two key factors: rank selection and weight initialization. While numerous LoRA variants have been proposed to improve performance by addressing one of these aspects, they often compromise usability or computational efficiency. In this paper, we analyze and identify the core limitations of existing approaches and propose a novel framework--GoRA (Gradient-driven Adaptive Low Rank Adaptation)--that simultaneously adapts both the rank and initialization strategy within a unified framework. GoRA leverages gradient information during training to dynamically assign optimal ranks and initialize low-rank adapter weights in an adaptive manner. To our knowledge, GoRA is the first method that not only addresses the limitations of prior approaches--which often focus on either rank selection or initialization in isolation--but also unifies both aspects within a single framework, enabling more effective and efficient adaptation. Extensive experiments across various architectures and modalities show that GoRA consistently outperforms existing LoRA-based methods while preserving the efficiency of vanilla LoRA. For example, when fine-tuning Llama3.1-8B-Base for mathematical reasoning, GoRA achieves a 5.13-point improvement over standard LoRA and even outperforms full fine-tuning by 2.05 points under high-rank settings. Code is available at: https://github.com/hhnqqq/MyTransformers.