NestQuant: Nested Lattice Quantization for Matrix Products and LLMs
作者: Semyon Savkin, Eitan Porat, Or Ordentlich, Yury Polyanskiy
分类: cs.LG, cs.AI, cs.IT
发布日期: 2025-02-13 (更新: 2025-07-26)
备注: 23 pages; Accepted at the 42nd International Conference on Machine Learning (ICML 2025)
💡 一句话要点
NestQuant:基于嵌套格量化的矩阵乘法和LLM高效量化方案
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 后训练量化 大型语言模型 低比特量化 嵌套格量化 Gosset格
📋 核心要点
- 现有LLM量化方法在低比特量化时性能损失显著,难以在精度和效率间取得平衡。
- NestQuant基于嵌套格量化理论,设计了一种低复杂度的量化方案,适用于LLM中的矩阵乘法。
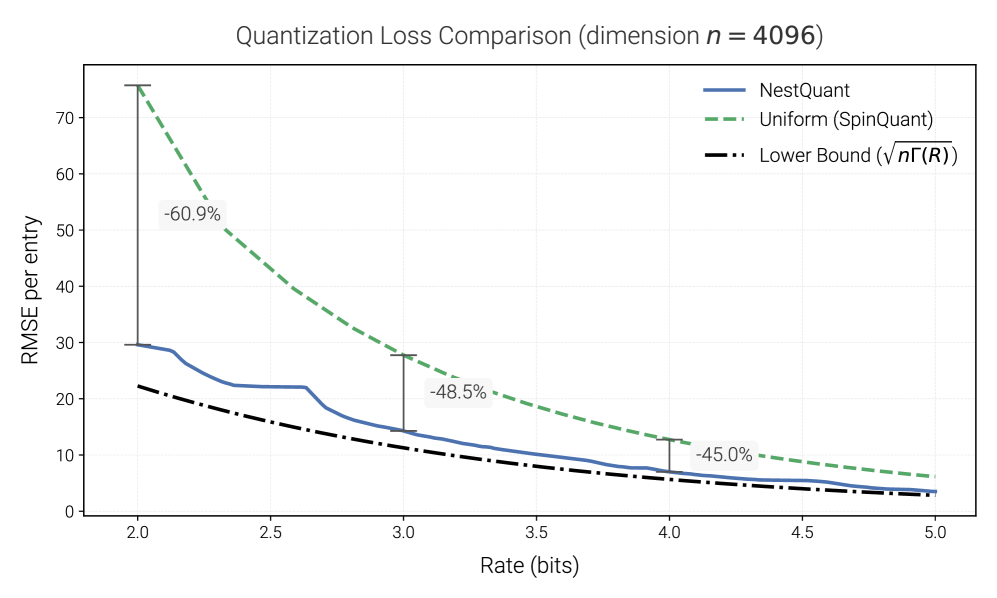
- 实验表明,NestQuant在多种LLM上实现了优于现有方法的量化性能,显著减小了精度损失。
📝 摘要(中文)
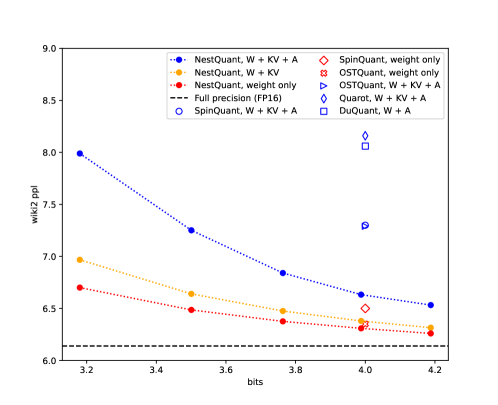
后训练量化(PTQ)已成为高效部署大型语言模型(LLM)的关键技术。本文提出NestQuant,一种新颖的权重和激活PTQ方案,它基于自相似的嵌套格。最近的研究在数学上表明,这种量化器在信息论上对于低精度矩阵乘法是最优的。我们实现了一个基于Gosset格的NestQuant的实用低复杂度版本,使其成为任何矩阵乘法步骤(例如,在自注意力、MLP等中)的即插即用量化器。例如,NestQuant将Llama-3-8B的权重、KV-cache和激活量化到4位,在wikitext2上实现了6.6的困惑度。与最先进的Metas SpinQuant(困惑度7.3)、OstQuant(7.3)和QuaRot(8.2)相比,这代表着与未量化模型(困惑度6.14)相比,困惑度差距减少了55%以上。在更大的模型(高达70B)和各种LLM评估基准上的比较证实了NestQuant的一致优越性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)部署中的低比特量化问题。现有的后训练量化(PTQ)方法在将LLM量化到极低的比特数(如4比特)时,通常会导致显著的性能下降,即困惑度(perplexity)显著增加。因此,如何在保持模型性能的同时,实现更高效的低比特量化是本研究要解决的核心问题。
核心思路:论文的核心思路是利用基于自相似嵌套格的量化器。这种量化器在理论上已被证明对于低精度矩阵乘法是信息论最优的。通过将权重和激活量化到嵌套格中的点,可以更有效地保留原始信息,从而减少量化误差。选择Gosset格是因为它具有良好的数学性质和较低的计算复杂度,适合实际应用。
技术框架:NestQuant的整体框架可以概括为:1)选择合适的嵌套格(本研究中使用Gosset格);2)将LLM的权重、激活和KV-cache映射到该格子上;3)执行量化操作,将浮点数近似为格点;4)使用量化后的权重和激活执行推理。该框架可以作为即插即用的模块集成到现有的LLM架构中,无需对模型结构进行重大修改。
关键创新:NestQuant的关键创新在于将理论上最优的嵌套格量化器应用于实际的LLM量化。与传统的均匀量化或线性量化方法相比,嵌套格量化能够更好地适应数据的分布,从而减少量化误差。此外,论文还提出了Gosset格的低复杂度实现,使其能够在实际应用中高效运行。
关键设计:NestQuant的关键设计包括:1)选择合适的Gosset格参数,以平衡量化精度和计算复杂度;2)设计高效的格点搜索算法,以快速找到与原始值最接近的格点;3)针对不同的LLM层(如自注意力层和MLP层)进行参数调整,以获得最佳的量化性能。论文未明确提及损失函数,但推测其目标是最小化量化误差对模型性能的影响。
🖼️ 关键图片
📊 实验亮点
NestQuant在Llama-3-8B模型上进行了实验,将权重、KV-cache和激活量化到4比特,在wikitext2数据集上实现了6.6的困惑度。与最先进的SpinQuant(7.3)、OstQuant(7.3)和QuaRot(8.2)相比,困惑度差距减少了55%以上。在更大的模型(高达70B)和各种LLM评估基准上的比较也证实了NestQuant的优越性。
🎯 应用场景
NestQuant在LLM部署方面具有广泛的应用前景。它可以显著降低LLM的存储空间和计算需求,使其能够在资源受限的设备上运行,例如移动设备和边缘服务器。此外,NestQuant还可以加速LLM的推理速度,提高用户体验。未来,该技术有望推动LLM在更多领域的应用,例如智能助手、自然语言处理和计算机视觉。
📄 摘要(原文)
Post-training quantization (PTQ) has emerged as a critical technique for efficient deployment of large language models (LLMs). This work proposes NestQuant, a novel PTQ scheme for weights and activations that is based on self-similar nested lattices. Recent works have mathematically shown such quantizers to be information-theoretically optimal for low-precision matrix multiplication. We implement a practical low-complexity version of NestQuant based on Gosset lattice, making it a drop-in quantizer for any matrix multiplication step (e.g., in self-attention, MLP etc). For example, NestQuant quantizes weights, KV-cache, and activations of Llama-3-8B to 4 bits, achieving perplexity of 6.6 on wikitext2. This represents more than 55% reduction in perplexity gap with respect to unquantized model (perplexity of 6.14) compared to state-of-the-art Metas SpinQuant (perplexity 7.3), OstQuant (7.3) and QuaRot (8.2). Comparisons on bigger models (up to 70B) and on various LLM evaluation benchmarks confirm uniform superiority of NestQuant.