Rolling Ahead Diffusion for Traffic Scene Simulation
作者: Yunpeng Liu, Matthew Niedoba, William Harvey, Adam Scibior, Berend Zwartsenberg, Frank Wood
分类: cs.LG, cs.RO
发布日期: 2025-02-13
备注: Accepted to Workshop on Machine Learning for Autonomous Driving at AAAI 2025
💡 一句话要点
提出Rolling Ahead Diffusion模型,用于交通场景中兼顾反应性和效率的模拟。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 交通场景生成 扩散模型 自动驾驶 反应式模拟 模型预测控制
📋 核心要点
- 现有基于扩散模型的交通场景生成方法难以在智能体行为偏离预设轨迹时做出实时反应,限制了其在交互式驾驶模拟中的应用。
- 论文提出Rolling Ahead Diffusion模型,通过同时预测下一步和部分噪声的未来步骤,在反应速度和规划能力之间取得平衡。
- 实验结果表明,该模型在保证反应性的同时,比基于扩散模型的自回归方法更高效,实现了计算效率的提升。
📝 摘要(中文)
逼真的驾驶模拟不仅要求NPC模仿自然的驾驶行为,还要对其他模拟智能体的行为做出反应。最近基于扩散的场景生成方法侧重于通过联合建模场景中所有智能体的运动来创建多样化和真实的交通场景。然而,当智能体的运动偏离其建模轨迹时,这些交通场景不会做出反应。例如,自车可以由独立的运动规划器控制。为了生成具有联合场景模型的反应式场景,模型必须基于新的观察结果,以模型预测控制(MPC)的方式在每个时间步长重新生成场景。虽然具有反应性,但这种方法非常耗时,因为每个模拟步骤都会为所有NPC生成一个完整的可能未来。或者,可以使用自回归模型(AR)来预测所有NPC的下一个即时未来步骤。虽然速度更快,但这种方法缺乏高级规划能力。我们提出了一种基于滚动扩散的交通场景生成模型,该模型通过预测下一步的未来,并同时预测部分噪声的更远未来步骤,从而结合了这两种方法的优点。我们表明,与基于扩散模型的AR相比,这种模型是高效的,实现了反应性和计算效率之间的有益折衷。
🔬 方法详解
问题定义:论文旨在解决交通场景模拟中,现有基于扩散模型的方法在反应性和计算效率之间的trade-off问题。具体来说,当自车(ego-agent)的行为与预先生成的场景不一致时,需要快速重新生成场景以保证模拟的真实性。然而,完全基于扩散模型重新生成整个未来轨迹计算量巨大,而简单的自回归模型又缺乏长时规划能力。
核心思路:论文的核心思路是结合模型预测控制(MPC)和自回归(AR)模型的优点,提出一种“滚动”的扩散模型。该模型不仅预测下一步的未来,还同时预测部分噪声的更远未来步骤。这样,模型既能快速响应当前环境的变化,又能保留一定的未来规划能力,从而在反应性和计算效率之间取得平衡。
技术框架:Rolling Ahead Diffusion模型的整体框架可以概括为以下几个步骤:1. 接收当前时刻的场景状态作为输入,包括所有智能体的位置、速度等信息。2. 使用扩散模型预测下一步的场景状态,以及部分噪声的未来多个时间步的场景状态。3. 根据自车的行为更新场景状态。4. 重复步骤1-3,实现滚动预测。该框架的关键在于扩散模型的训练和推理过程,以及如何有效地融合不同时间步的预测结果。
关键创新:论文最重要的技术创新点在于提出了“滚动扩散”的概念,即在每个时间步,模型不仅预测下一步的未来,还预测部分噪声的更远未来。这种方法允许模型在快速响应当前环境变化的同时,保留一定的未来规划能力,从而在反应性和计算效率之间取得平衡。与传统的基于扩散模型的MPC方法相比,该方法避免了在每个时间步重新生成整个未来轨迹的计算开销。与简单的自回归模型相比,该方法具有更强的长时规划能力。
关键设计:论文中关于扩散模型的具体结构和训练细节未知。但可以推测,模型可能采用了条件扩散模型,以自车的行为作为条件输入。损失函数可能包括两部分:一部分是预测下一步状态的损失,另一部分是预测部分噪声的未来状态的损失。具体参数设置和网络结构需要参考论文原文。
🖼️ 关键图片

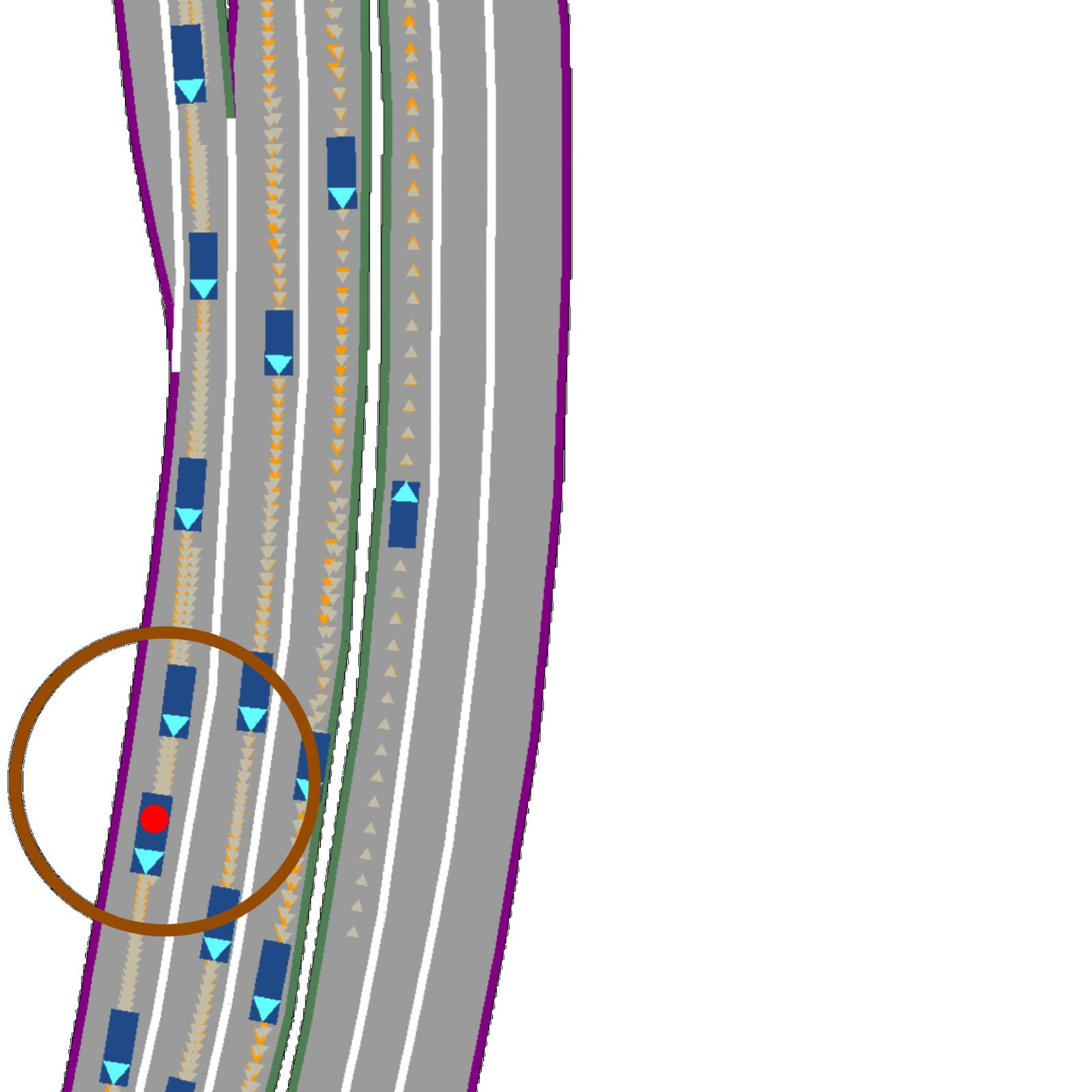
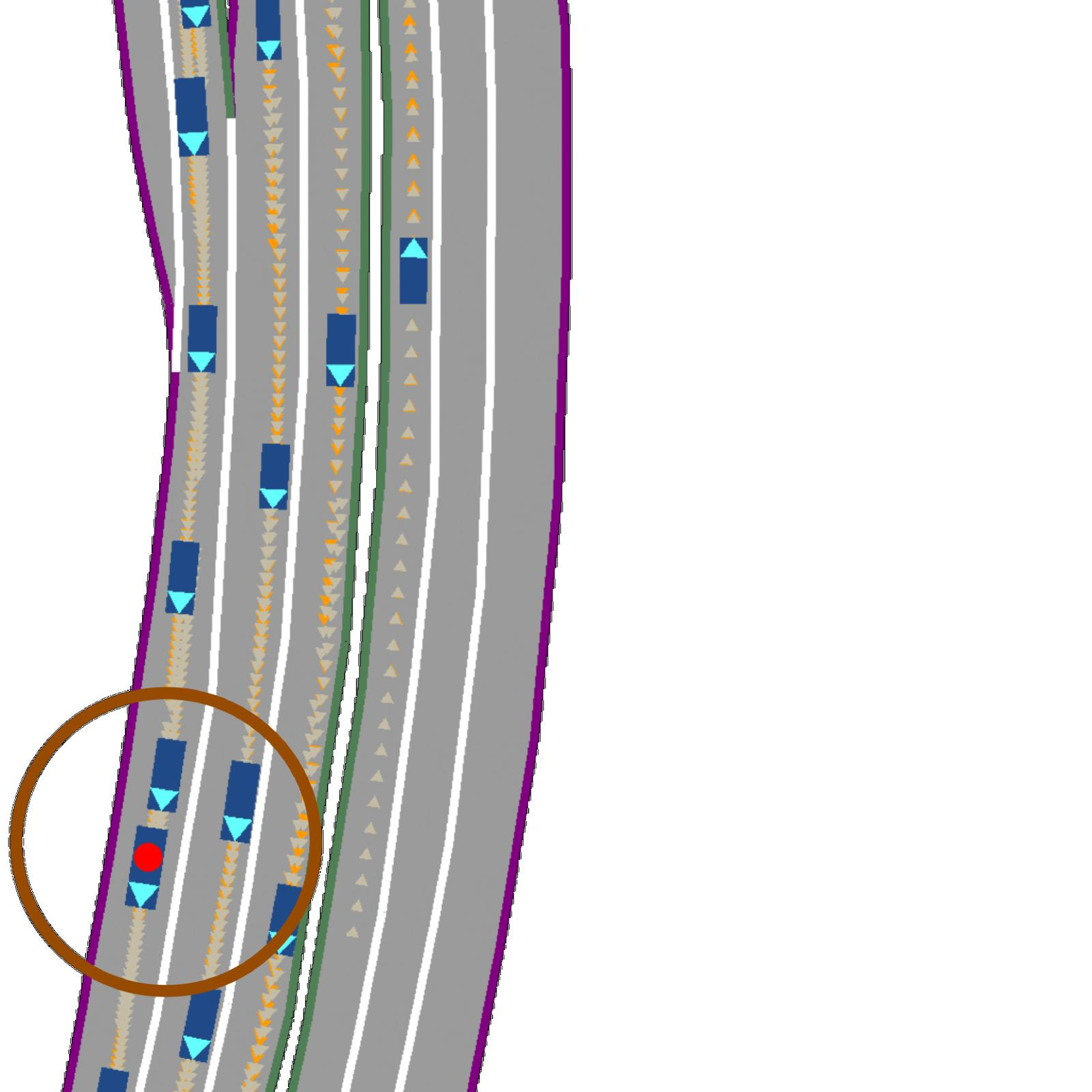
📊 实验亮点
论文提出了一种新的基于滚动扩散的交通场景生成模型,该模型在反应性和计算效率之间取得了良好的平衡。具体实验数据未知,但论文声称该模型比基于扩散模型的自回归方法更高效,实现了反应性和计算效率之间的有益折衷。具体的性能提升幅度需要参考论文原文。
🎯 应用场景
该研究成果可应用于自动驾驶车辆的测试和验证,以及驾驶员行为建模等领域。通过生成具有反应性和多样性的交通场景,可以更有效地评估自动驾驶系统的性能和安全性。此外,该模型还可以用于训练自动驾驶算法,提高其在复杂交通环境中的适应能力。未来,该技术有望推动自动驾驶技术的进一步发展和应用。
📄 摘要(原文)
Realistic driving simulation requires that NPCs not only mimic natural driving behaviors but also react to the behavior of other simulated agents. Recent developments in diffusion-based scenario generation focus on creating diverse and realistic traffic scenarios by jointly modelling the motion of all the agents in the scene. However, these traffic scenarios do not react when the motion of agents deviates from their modelled trajectories. For example, the ego-agent can be controlled by a stand along motion planner. To produce reactive scenarios with joint scenario models, the model must regenerate the scenario at each timestep based on new observations in a Model Predictive Control (MPC) fashion. Although reactive, this method is time-consuming, as one complete possible future for all NPCs is generated per simulation step. Alternatively, one can utilize an autoregressive model (AR) to predict only the immediate next-step future for all NPCs. Although faster, this method lacks the capability for advanced planning. We present a rolling diffusion based traffic scene generation model which mixes the benefits of both methods by predicting the next step future and simultaneously predicting partially noised further future steps at the same time. We show that such model is efficient compared to diffusion model based AR, achieving a beneficial compromise between reactivity and computational efficiency.