Task Generalization With AutoRegressive Compositional Structure: Can Learning From $D$ Tasks Generalize to $D^{T}$ Tasks?
作者: Amirhesam Abedsoltan, Huaqing Zhang, Kaiyue Wen, Hongzhou Lin, Jingzhao Zhang, Mikhail Belkin
分类: cs.LG, stat.ML
发布日期: 2025-02-13 (更新: 2025-06-09)
💡 一句话要点
基于自回归组合结构的任务泛化:从D个任务学习能否泛化到D^T个任务?
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 任务泛化 自回归模型 组合结构 上下文学习 思维链 Transformers 深度学习
📋 核心要点
- 现有方法在任务泛化方面存在挑战,尤其是在任务数量呈指数级增长时,难以保证模型性能。
- 论文提出利用自回归组合结构,将复杂任务分解为子任务的组合,从而实现从少量任务到大量任务的泛化。
- 实验证明,Transformers模型通过上下文学习和思维链推理,在多种任务上实现了指数级的任务泛化能力。
📝 摘要(中文)
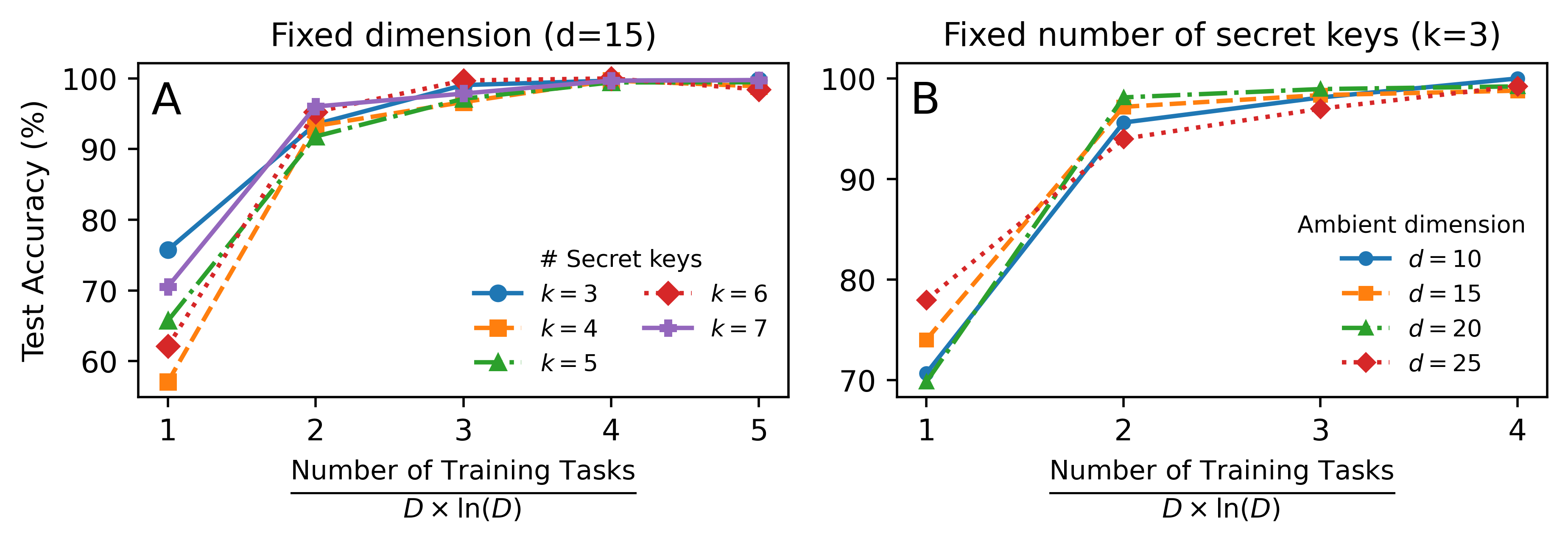
大型语言模型(LLMs)展现出卓越的任务泛化能力,仅通过少量演示就能解决从未明确训练过的任务。这引出了一个根本问题:从少量任务中学习何时能够泛化到大型任务族?本文通过自回归组合结构的视角研究任务泛化,其中每个任务都是T个操作的组合,每个操作来自D个子任务的有限族。这产生了一个大小为D^T的总类别。我们首先在理论上证明,通过仅在$\widetilde{O}(D)$个任务上训练,可以实现对所有D^T个任务的泛化。在实验上,我们证明了Transformers通过上下文学习(ICL)和思维链(CoT)推理在稀疏奇偶校验函数上实现了这种指数级的任务泛化。我们进一步展示了算术和翻译方面的泛化,超越了奇偶校验函数。
🔬 方法详解
问题定义:论文旨在解决任务泛化问题,即如何让模型在少量任务上训练后,能够泛化到大量未见过的任务上。现有方法在面对任务数量呈指数级增长时,往往难以有效泛化,需要大量的训练数据或复杂的模型设计。
核心思路:论文的核心思路是利用自回归组合结构来表示任务。具体来说,将每个复杂任务分解为一系列子任务的组合,每个子任务从一个有限的子任务集中选取。通过学习这些子任务之间的组合关系,模型可以泛化到未见过的任务组合。这种方法的核心在于将任务空间结构化,从而降低了泛化的难度。
技术框架:整体框架包括以下几个步骤:1)定义一个包含D个子任务的有限集合。2)将每个任务表示为T个子任务的组合,形成一个大小为D^T的任务族。3)使用Transformers模型进行训练,通过上下文学习(ICL)或思维链(CoT)推理来学习子任务之间的组合关系。4)在未见过的任务组合上进行测试,评估模型的泛化能力。
关键创新:论文最重要的创新点在于提出了自回归组合结构来建模任务,并证明了在这种结构下,可以通过少量任务的学习实现指数级的任务泛化。这种方法将任务泛化问题转化为学习子任务组合关系的问题,从而降低了学习的复杂度。
关键设计:论文的关键设计包括:1)使用Transformers模型作为基础架构,利用其强大的上下文学习能力。2)采用上下文学习(ICL)或思维链(CoT)推理来引导模型学习子任务之间的组合关系。3)在稀疏奇偶校验函数、算术和翻译等任务上进行实验,验证了方法的有效性。具体的参数设置和网络结构根据不同的任务进行调整,但整体上都遵循Transformers的标准设计。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Transformers模型在稀疏奇偶校验函数上实现了指数级的任务泛化。通过在$\widetilde{O}(D)$个任务上训练,模型可以泛化到D^T个任务。此外,该方法在算术和翻译任务上也取得了良好的泛化效果,证明了其在不同任务上的适用性。
🎯 应用场景
该研究成果可应用于各种需要任务泛化的场景,例如机器人控制、自然语言处理和计算机视觉。通过学习少量任务,模型可以快速适应新的任务需求,降低了开发成本和时间。未来,该方法有望应用于更复杂的任务,例如自动驾驶和智能助手。
📄 摘要(原文)
Large language models (LLMs) exhibit remarkable task generalization, solving tasks they were never explicitly trained on with only a few demonstrations. This raises a fundamental question: When can learning from a small set of tasks generalize to a large task family? In this paper, we investigate task generalization through the lens of autoregressive compositional structure, where each task is a composition of $T$ operations, and each operation is among a finite family of $D$ subtasks. This yields a total class of size $D^T$. We first show that generalization to all $D^T$ tasks is theoretically achievable by training on only $\widetilde{O}(D)$ tasks. Empirically, we demonstrate that Transformers achieve such exponential task generalization on sparse parity functions via In-context Learning (ICL) and chain-of-thought (CoT) reasoning. We further show generalization in arithmetic and translation, beyond parity functions.