Beyond Shallow Behavior: Task-Efficient Value-Based Multi-Task Offline MARL via Skill Discovery
作者: Xun Wang, Zhuoran Li, Hai Zhong, Longbo Huang
分类: cs.LG, cs.AI, cs.MA
发布日期: 2025-02-13 (更新: 2025-09-26)
💡 一句话要点
提出SD-CQL算法,解决离线多智能体强化学习中的任务泛化与效率问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 多智能体系统 技能发现 任务泛化 保守Q学习
📋 核心要点
- 现有离线MARL方法通常是任务特定的,需要为新任务重新训练,导致冗余和效率低下。
- SD-CQL通过在潜在空间中发现技能,并结合保守Q学习,实现了任务间的知识迁移和泛化。
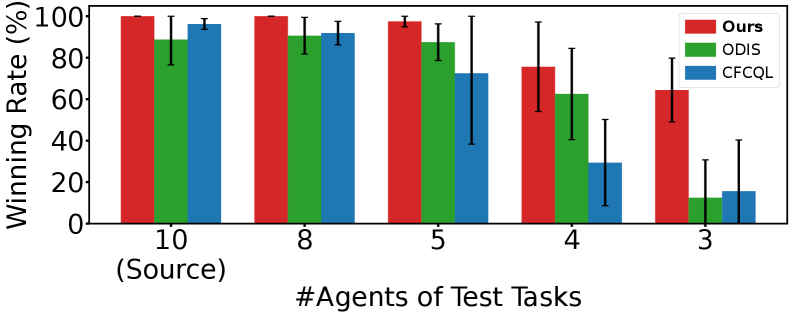
- 在星际争霸II实验中,SD-CQL在多个任务上显著优于现有方法,展现了其优越的泛化性能。
📝 摘要(中文)
本文提出了一种任务高效的、基于价值的多任务离线MARL算法,即技能发现保守Q学习(SD-CQL)。与现有方法通过行为克隆从技能中解码动作不同,SD-CQL通过重构下一个观测在潜在空间中发现技能,分别评估固定和可变动作,并使用带有局部价值校准的保守Q学习来为每个技能选择最优动作。它消除了局部-全局对齐的需要,并能够从有限的小规模源任务中实现强大的多任务泛化。在星际争霸II上的大量实验表明了SD-CQL的优越泛化性能和任务效率。在14个任务集中,SD-CQL在13个任务集上取得了最佳性能,在单个任务集上提升高达68.9%。
🔬 方法详解
问题定义:现有的离线多智能体强化学习(MARL)方法通常是针对特定任务设计的,当面对新的任务时,需要从头开始重新训练模型。这种方式效率低下,并且无法有效利用不同任务之间的共性知识。尤其是在数据驱动的离线MARL场景下,如果历史数据量有限,任务之间的泛化能力就显得尤为重要。因此,如何设计一种能够高效地进行多任务学习,并能够从少量数据中泛化到新任务的离线MARL算法是一个关键问题。
核心思路:SD-CQL的核心思路是通过技能发现来解耦策略学习和任务特定信息。具体来说,算法首先在潜在空间中学习一组技能,每个技能代表一种行为模式。然后,算法学习如何根据当前状态和任务选择合适的技能,并执行该技能对应的动作。通过这种方式,算法可以将任务特定的信息编码在技能选择过程中,而策略学习则可以专注于学习通用的行为模式。此外,SD-CQL还采用了保守Q学习(CQL)来解决离线学习中的外推误差问题,从而提高算法的稳定性和泛化能力。
技术框架:SD-CQL的整体框架包括以下几个主要模块:1) 技能发现模块:该模块通过重构下一个观测来学习潜在空间中的技能。2) 技能选择模块:该模块根据当前状态和任务选择合适的技能。3) 动作执行模块:该模块执行所选技能对应的动作。4) 价值评估模块:该模块评估当前状态-动作对的价值,并使用保守Q学习来更新Q函数。整个流程是,智能体首先根据当前状态和任务选择一个技能,然后执行该技能对应的动作,并观察环境的反馈。接着,智能体使用观察到的数据来更新技能发现模块、技能选择模块和价值评估模块。
关键创新:SD-CQL的关键创新在于其技能发现机制和局部价值校准。传统的基于技能的方法通常使用行为克隆来从技能中解码动作,这需要对局部和全局信息进行对齐,增加了学习的难度。而SD-CQL通过重构下一个观测来学习技能,避免了局部-全局对齐的问题。此外,SD-CQL还引入了局部价值校准,通过对Q函数进行局部调整,进一步提高了算法的稳定性和泛化能力。
关键设计:SD-CQL的关键设计包括:1) 技能发现损失函数:使用重构误差作为技能发现的损失函数,鼓励算法学习能够有效表示环境状态变化的技能。2) 保守Q学习损失函数:使用CQL损失函数来约束Q函数的取值,避免外推误差。3) 局部价值校准:通过对Q函数进行局部调整,使其更加符合真实价值分布。具体的网络结构和参数设置需要根据具体的任务进行调整,论文中可能提供了针对星际争霸II的实验设置。
🖼️ 关键图片


📊 实验亮点
SD-CQL在星际争霸II的14个任务集上进行了广泛的实验,结果表明SD-CQL在13个任务集上取得了最佳性能,相比现有方法,在单个任务集上提升高达68.9%。这充分证明了SD-CQL在多任务离线MARL中的优越泛化性能和任务效率。实验结果表明,SD-CQL能够有效地从少量数据中学习到通用的技能,并将其泛化到新的任务中。
🎯 应用场景
SD-CQL算法具有广泛的应用前景,尤其适用于那些拥有大量历史数据但交互成本高昂的多智能体系统。例如,在交通控制领域,可以利用历史交通数据学习不同交通状况下的控制策略;在机器人协作领域,可以利用历史协作数据学习不同任务下的协作技能。此外,该算法还可以应用于游戏AI、金融交易等领域,具有重要的实际价值和未来影响。
📄 摘要(原文)
As a data-driven approach, offline MARL learns superior policies solely from offline datasets, ideal for domains rich in historical data but with high interaction costs and risks. However, most existing methods are task-specific, requiring retraining for new tasks, leading to redundancy and inefficiency. To address this issue, we propose a task-efficient value-based multi-task offline MARL algorithm, Skill-Discovery Conservative Q-Learning (SD-CQL). Unlike existing methods decoding actions from skills via behavior cloning, SD-CQL discovers skills in a latent space by reconstructing the next observation, evaluates fixed and variable actions separately, and uses conservative Q-learning with local value calibration to select the optimal action for each skill. It eliminates the need for local-global alignment and enables strong multi-task generalization from limited, small-scale source tasks. Substantial experiments on StarCraft II demonstrate the superior generalization performance and task-efficiency of SD-CQL. It achieves the best performance on $\textbf{13}$ out of $14$ task sets, with up to $\textbf{68.9%}$ improvement on individual task sets.