Distillation Scaling Laws
作者: Dan Busbridge, Amitis Shidani, Floris Weers, Jason Ramapuram, Etai Littwin, Russ Webb
分类: cs.LG, cs.AI, cs.CL, stat.ML
发布日期: 2025-02-12 (更新: 2025-07-25)
备注: Version accepted to ICML 2025. 69 pages, 54 figures, 13 tables
💡 一句话要点
提出蒸馏缩放定律,优化师生模型计算资源分配以提升学生模型性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 模型压缩 缩放定律 计算资源分配 机器学习
📋 核心要点
- 现有蒸馏方法缺乏对计算资源分配的有效指导,导致大规模蒸馏的风险较高。
- 论文提出蒸馏缩放定律,通过优化师生模型计算资源分配,最大化学生模型的性能。
- 实验表明,在特定场景下,蒸馏优于监督学习,且计算水平随学生规模增长而可预测。
📝 摘要(中文)
本文提出了一种蒸馏缩放定律,该定律基于计算预算及其在学生和教师之间的分配来估计蒸馏模型的性能。我们的发现通过为教师和学生进行计算最优分配以最大化学生性能,从而降低了大规模蒸馏相关的风险。我们为两种关键场景提供了计算最优的蒸馏方案:当教师已经存在时,以及当教师需要训练时。在涉及多个学生或现有教师的场景中,蒸馏优于监督学习,其计算水平随学生规模的增长而可预测地扩展。相反,如果仅蒸馏一个学生并且教师也需要训练,则通常首选监督学习。此外,我们对蒸馏的大规模研究增加了我们对该过程的理解,并有助于指导实验设计。
🔬 方法详解
问题定义:论文旨在解决如何在知识蒸馏过程中,有效地分配计算资源给教师模型和学生模型,以最大化学生模型的性能。现有方法通常缺乏对计算资源分配的理论指导,导致在大规模蒸馏中,资源分配不合理,可能无法达到最佳性能,甚至不如直接的监督学习。
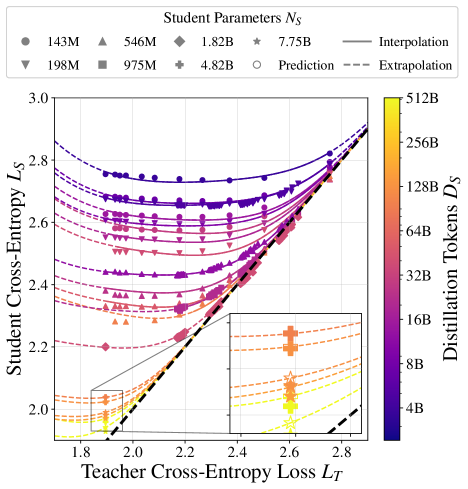
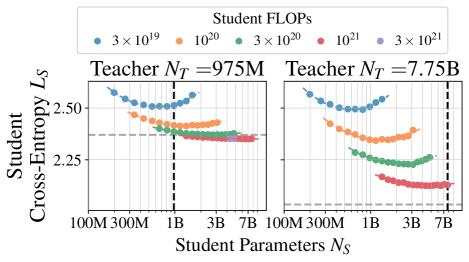
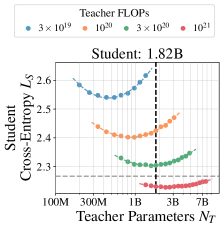
核心思路:论文的核心思路是建立一个蒸馏缩放定律,该定律能够根据给定的计算预算,以及教师和学生之间的计算资源分配比例,来预测学生模型的性能。通过这个定律,可以找到计算最优的分配方案,从而最大化学生模型的性能。
技术框架:论文的技术框架主要包括以下几个部分:1) 建立蒸馏性能与计算资源分配之间的数学模型,即蒸馏缩放定律。2) 基于该定律,推导出两种关键场景下的计算最优蒸馏方案:一是教师模型已经存在的情况;二是教师模型需要从头训练的情况。3) 通过大规模实验验证该定律的有效性,并分析蒸馏过程中的关键因素。
关键创新:论文最重要的技术创新点在于提出了蒸馏缩放定律,将蒸馏性能与计算资源分配联系起来,为大规模蒸馏提供了理论指导。与现有方法相比,该定律能够帮助研究人员和工程师更好地理解蒸馏过程,并做出更明智的资源分配决策。
关键设计:论文的关键设计包括:1) 蒸馏缩放定律的具体形式,可能涉及到对教师模型和学生模型规模、训练数据量、训练时间等因素的建模。2) 计算最优分配方案的推导过程,可能涉及到优化算法的应用。3) 大规模实验的设计,包括数据集的选择、模型架构的选择、以及评估指标的选择。
🖼️ 关键图片
📊 实验亮点
论文通过大规模实验验证了蒸馏缩放定律的有效性。实验结果表明,在特定场景下,通过优化计算资源分配,蒸馏可以显著优于监督学习,尤其是在存在多个学生模型或已有教师模型的情况下。此外,实验还揭示了蒸馏过程中的一些关键因素,例如教师模型的质量、学生模型的容量等。
🎯 应用场景
该研究成果可应用于各种需要模型压缩和加速的场景,例如移动设备上的图像识别、自动驾驶中的目标检测等。通过优化师生模型的计算资源分配,可以显著提升学生模型的性能,降低部署成本,加速模型落地。未来,该研究可以进一步扩展到更复杂的蒸馏场景,例如多教师蒸馏、跨模态蒸馏等。
📄 摘要(原文)
We propose a distillation scaling law that estimates distilled model performance based on a compute budget and its allocation between the student and teacher. Our findings mitigate the risks associated with large-scale distillation by enabling compute-optimal allocation for both the teacher and student to maximize student performance. We provide compute-optimal distillation recipes for two key scenarios: when a teacher already exists, and when a teacher needs training. In settings involving many students or an existing teacher, distillation outperforms supervised learning up to a compute level that scales predictably with student size. Conversely, if only one student is to be distilled and a teacher also requires training, supervised learning is generally preferable. Additionally, our large-scale study of distillation increases our understanding of the process and helps inform experimental design.