Towards Principled Unsupervised Multi-Agent Reinforcement Learning
作者: Riccardo Zamboni, Mirco Mutti, Marcello Restelli
分类: cs.LG, cs.AI
发布日期: 2025-02-12 (更新: 2025-10-19)
💡 一句话要点
提出一种基于混合熵最大化的可扩展非监督多智能体强化学习方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 非监督学习 任务无关探索 混合熵 信任域策略搜索
📋 核心要点
- 多智能体强化学习中,如何在无奖励信号下进行有效的任务无关探索是一个挑战。
- 论文提出一种基于混合熵最大化的方法,旨在引导智能体探索环境,学习有用的状态表示。
- 实验结果表明,该方法在多个复杂环境中表现良好,为非监督多智能体强化学习提供了有效途径。
📝 摘要(中文)
在强化学习中,非监督预训练指的是在没有先验任务规范(即奖励)的情况下预训练策略,以便后续有效地学习下游任务。单智能体环境下的该问题已被广泛研究和理解。一种流行的方法,称为任务无关探索,将非监督目标定义为最大化智能体策略所诱导的状态分布的熵,由此产生相应的原则和方法。相比之下,多智能体环境下的研究还很少,而多智能体环境在现实世界中无处不在。本文旨在解决多智能体环境下非监督预训练的问题,首先分析了不同问题公式的优缺点,并强调了即使在理论上可解的情况下,该问题在实践中也并非易事。然后,提出了一种可扩展的、去中心化的、信任域策略搜索算法来解决实际问题。最后,通过数值验证来证实理论发现,并为通过任务无关探索进行非监督多智能体强化学习铺平道路,表明优化特定目标(即混合熵)可以在可处理性和性能之间提供出色的折衷。
🔬 方法详解
问题定义:论文旨在解决多智能体强化学习中,如何在没有外部奖励信号的情况下,让智能体进行有效的探索和学习的问题。现有的单智能体非监督预训练方法难以直接应用于多智能体环境,因为多智能体环境的状态空间和动作空间都呈指数级增长,导致探索效率低下。此外,如何协调多个智能体的探索行为,避免重复探索和冲突,也是一个重要的挑战。
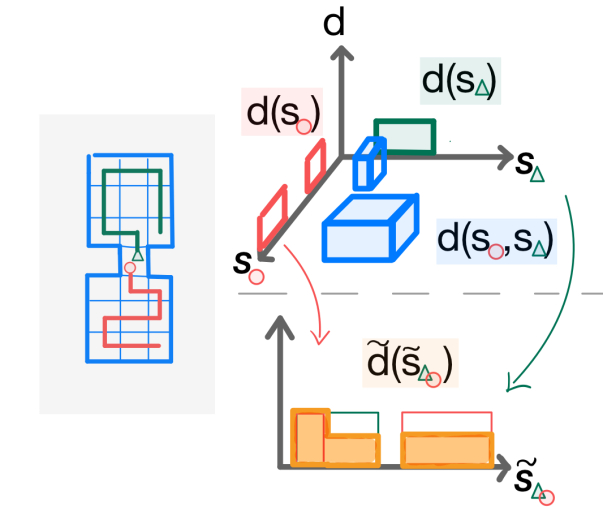
核心思路:论文的核心思路是最大化智能体策略所诱导的状态分布的混合熵。混合熵能够衡量多个智能体状态分布的多样性,鼓励智能体探索不同的状态空间区域。通过最大化混合熵,可以引导智能体进行更有效的探索,学习到更丰富的状态表示,从而为后续的下游任务提供更好的初始化。
技术框架:论文提出的算法采用去中心化的架构,每个智能体独立地学习自己的策略。算法主要包含以下几个步骤:1) 智能体与环境交互,收集经验数据;2) 使用收集到的数据估计状态分布的混合熵;3) 使用信任域策略搜索算法更新智能体的策略,目标是最大化混合熵。算法采用迭代的方式进行,直到达到预定的训练轮数或收敛条件。
关键创新:论文的关键创新在于将混合熵最大化作为多智能体非监督探索的目标函数。与传统的单智能体熵最大化方法相比,混合熵能够更好地衡量多智能体系统的探索程度,避免智能体陷入局部最优。此外,论文还提出了一种可扩展的去中心化算法,能够有效地解决大规模多智能体环境下的探索问题。
关键设计:论文采用信任域策略搜索(TRPO)算法来更新智能体的策略。TRPO算法能够保证策略更新的稳定性,避免策略崩溃。论文还设计了一种基于神经网络的函数逼近器来估计状态分布的混合熵。网络的输入是智能体的状态,输出是状态的概率密度。损失函数采用KL散度来衡量估计的状态分布与真实状态分布之间的差异。
🖼️ 关键图片
📊 实验亮点
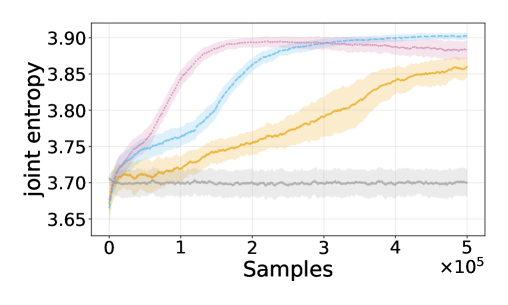
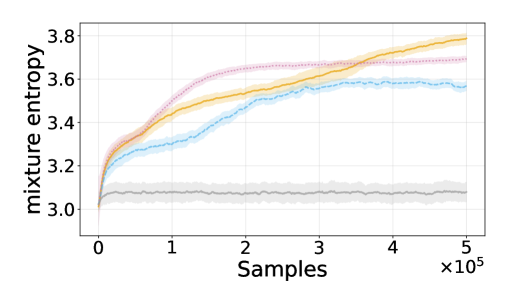
论文在多个具有挑战性的多智能体环境中进行了实验验证,包括合作导航、资源收集等。实验结果表明,该方法能够显著提高智能体的探索效率和学习性能。例如,在合作导航任务中,该方法能够使智能体更快地找到目标位置,并减少碰撞次数。与基线方法相比,该方法在多个指标上都取得了显著的提升。
🎯 应用场景
该研究成果可应用于机器人协同、自动驾驶、交通调度、资源分配等多个领域。通过非监督预训练,智能体可以在没有人工干预的情况下学习到通用的行为模式和环境知识,从而提高在复杂环境中的适应性和鲁棒性。未来,该方法有望推动多智能体系统在现实世界中的广泛应用。
📄 摘要(原文)
In reinforcement learning, we typically refer to unsupervised pre-training when we aim to pre-train a policy without a priori access to the task specification, i.e. rewards, to be later employed for efficient learning of downstream tasks. In single-agent settings, the problem has been extensively studied and mostly understood. A popular approach, called task-agnostic exploration, casts the unsupervised objective as maximizing the entropy of the state distribution induced by the agent's policy, from which principles and methods follow. In contrast, little is known about it in multi-agent settings, which are ubiquitous in the real world. What are the pros and cons of alternative problem formulations in this setting? How hard is the problem in theory, how can we solve it in practice? In this paper, we address these questions by first characterizing those alternative formulations and highlighting how the problem, even when tractable in theory, is non-trivial in practice. Then, we present a scalable, decentralized, trust-region policy search algorithm to address the problem in practical settings. Finally, we provide numerical validations to both corroborate the theoretical findings and pave the way for unsupervised multi-agent reinforcement learning via task-agnostic exploration in challenging domains, showing that optimizing for a specific objective, namely mixture entropy, provides an excellent trade-off between tractability and performances.