LowRA: Accurate and Efficient LoRA Fine-Tuning of LLMs under 2 Bits
作者: Zikai Zhou, Qizheng Zhang, Hermann Kumbong, Kunle Olukotun
分类: cs.LG, cs.AR, cs.CL, cs.PF
发布日期: 2025-02-12
💡 一句话要点
LowRA:在低于2比特下实现LLM的精确高效LoRA微调
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低比特量化 参数高效微调 LoRA 大型语言模型 资源受限环境
📋 核心要点
- 现有LLM微调成本高昂,即使是LoRA等参数高效方法也消耗大量资源,限制了其在资源受限环境中的应用。
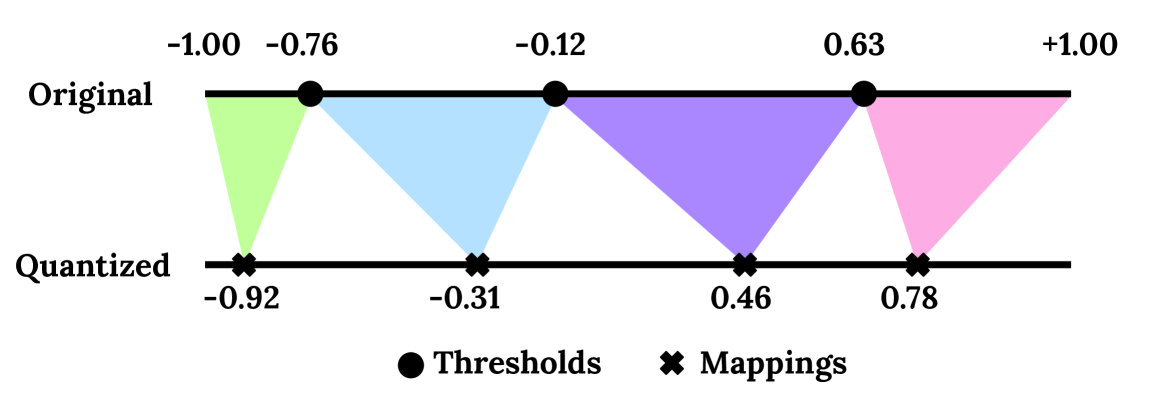
- LowRA通过优化细粒度量化策略,包括映射、阈值选择和精度分配,实现了低于2比特的LoRA微调。
- 实验表明,LowRA在多种LLM和数据集上,能够在极低比特下保持较高的精度,并显著降低内存占用。
📝 摘要(中文)
随着模型扩展到数千亿参数,微调大型语言模型(LLM)的成本越来越高,即使是像LoRA这样的参数高效微调(PEFT)方法仍然需要大量资源。我们推出了LowRA,这是第一个能够在低于每个参数2比特的情况下实现LoRA微调,同时性能损失最小的框架。LowRA优化了细粒度的量化——映射、阈值选择和精度分配——同时利用高效的CUDA内核进行可扩展的部署。在4个LLM和4个数据集上的广泛评估表明,LowRA在高于2比特时实现了卓越的性能-精度权衡,并且在低至1.15比特时仍然保持准确,从而减少了高达50%的内存使用量。我们的结果突出了超低比特LoRA微调在资源受限环境中的潜力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)微调过程中资源消耗过高的问题,尤其是在参数高效微调(PEFT)方法LoRA中,仍然存在显著的内存和计算开销。现有方法无法在极低比特(低于2比特)下进行有效的LoRA微调,导致性能显著下降,限制了LLM在资源受限设备上的部署和应用。
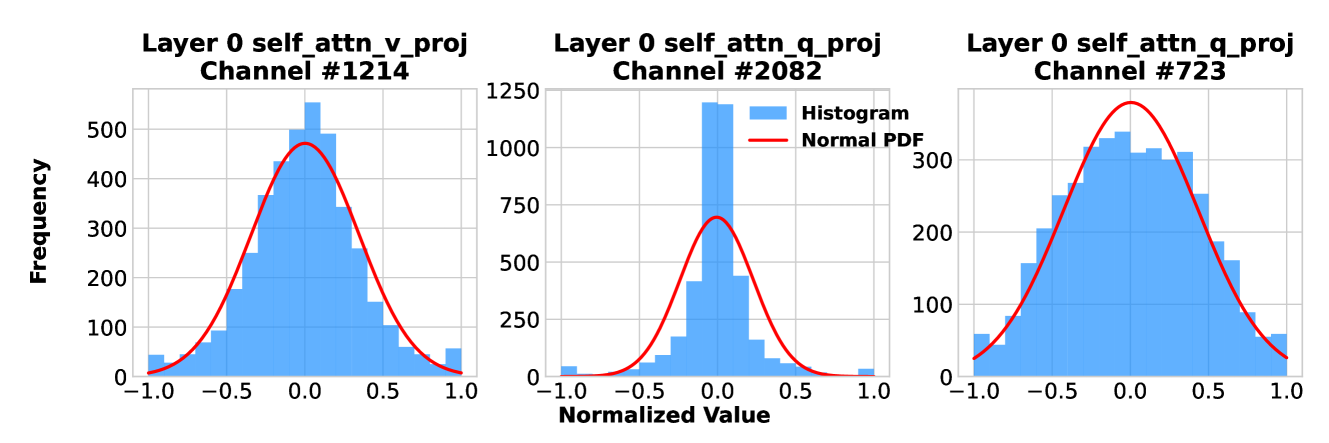
核心思路:LowRA的核心思路是通过细粒度的量化策略,在极低比特下尽可能保留LoRA微调的性能。具体来说,LowRA优化了量化映射、阈值选择和精度分配,使得模型能够在极低的比特精度下进行微调,同时保持较高的准确率。这种细粒度的优化能够更好地适应不同参数的重要性,从而在压缩模型的同时减少性能损失。
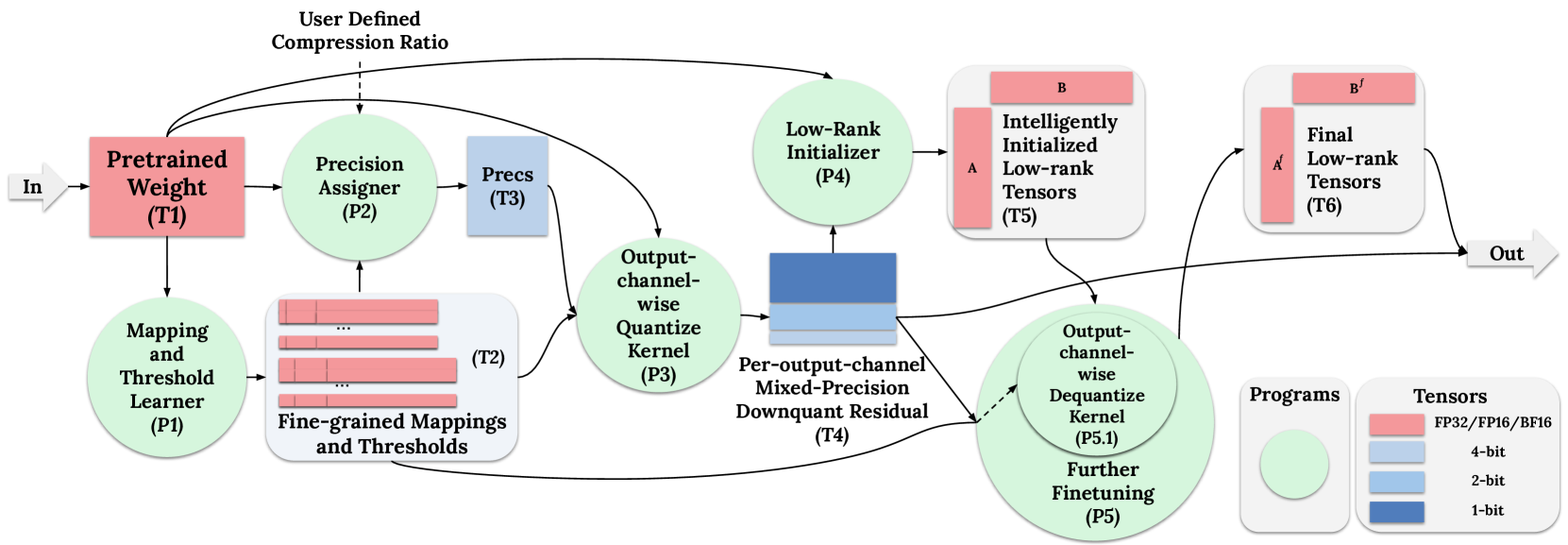
技术框架:LowRA的整体框架包括以下几个主要步骤:首先,对LoRA参数进行量化,使用优化的量化策略将参数映射到低比特表示。其次,通过阈值选择算法确定最佳的量化阈值,以最小化量化误差。然后,根据参数的重要性分配不同的精度,对重要参数使用更高的精度,对不重要参数使用更低的精度。最后,利用高效的CUDA内核实现低比特LoRA微调的加速,从而实现可扩展的部署。
关键创新:LowRA最关键的创新点在于其细粒度的量化策略,能够根据参数的重要性自适应地分配精度。与传统的均匀量化方法不同,LowRA能够更好地保留重要参数的信息,从而在极低比特下保持较高的性能。此外,LowRA还优化了量化映射和阈值选择算法,进一步提高了量化的效率和准确性。
关键设计:LowRA的关键设计包括:1) 使用非均匀量化映射,更好地适应参数的分布;2) 设计了一种基于梯度的阈值选择算法,能够自动确定最佳的量化阈值;3) 采用了一种基于重要性的精度分配策略,对重要参数使用更高的精度;4) 开发了高效的CUDA内核,加速低比特LoRA微调的计算。
🖼️ 关键图片
📊 实验亮点
LowRA在4个LLM和4个数据集上的实验结果表明,其在高于2比特时实现了卓越的性能-精度权衡,并且在低至1.15比特时仍然保持准确,从而减少了高达50%的内存使用量。例如,在某个数据集上,LowRA在1.5比特下的性能仅比全精度LoRA下降了不到1%,但内存占用却减少了近一半。
🎯 应用场景
LowRA技术可应用于资源受限的边缘设备,例如移动设备、嵌入式系统和物联网设备,使得这些设备能够进行LLM的个性化微调,从而提升用户体验。此外,该技术还可以降低LLM微调的成本,使得更多的研究人员和开发者能够参与到LLM的开发和应用中来。未来,LowRA有望推动LLM在更多领域的应用,例如智能助手、自然语言处理和计算机视觉等。
📄 摘要(原文)
Fine-tuning large language models (LLMs) is increasingly costly as models scale to hundreds of billions of parameters, and even parameter-efficient fine-tuning (PEFT) methods like LoRA remain resource-intensive. We introduce LowRA, the first framework to enable LoRA fine-tuning below 2 bits per parameter with minimal performance loss. LowRA optimizes fine-grained quantization - mapping, threshold selection, and precision assignment - while leveraging efficient CUDA kernels for scalable deployment. Extensive evaluations across 4 LLMs and 4 datasets show that LowRA achieves a superior performance-precision trade-off above 2 bits and remains accurate down to 1.15 bits, reducing memory usage by up to 50%. Our results highlight the potential of ultra-low-bit LoRA fine-tuning for resource-constrained environments.