Model Selection for Off-policy Evaluation: New Algorithms and Experimental Protocol
作者: Pai Liu, Lingfeng Zhao, Shivangi Agarwal, Jinghan Liu, Audrey Huang, Philip Amortila, Nan Jiang
分类: cs.LG, cs.AI, stat.ML
发布日期: 2025-02-11 (更新: 2025-10-24)
💡 一句话要点
针对离线策略评估的模型选择,提出新算法与实验协议。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 策略评估 模型选择 超参数调优 重要性采样
📋 核心要点
- 离线强化学习中,如何有效选择合适的模型或超参数以进行策略评估,是一个长期存在的挑战。
- 论文提出新的无模型和基于模型的选择器,并设计新的实验协议,以更稳定和可控的方式评估候选值函数。
- 实验结果表明,提出的无模型选择器LSTD-Tournament在Gym-Hopper环境中表现出良好的性能。
📝 摘要(中文)
本文研究离线强化学习(RL)中,基于数据的留出验证和超参数调优问题。标准方法是使用离线策略评估(OPE)来评估和选择策略,但OPE要么产生指数级方差(例如,重要性采样),要么自身具有超参数(例如,FQE和基于模型的方法)。本文重点关注OPE本身的超参数调优,这是一个研究不足的领域。具体而言,本文旨在选择候选值函数(“无模型”)或动力学模型(“基于模型”),以最佳地评估目标策略的性能。为此,本文开发了:(1)具有理论保证的新的无模型和基于模型的选择器,以及(2)一个新的实验协议,用于经验性地评估它们。与先前工作中的无模型协议相比,本文的新协议允许更稳定的生成,更好地控制候选值函数(以一种无需优化的方式),并能够同时评估无模型和基于模型的方法。本文在Gym-Hopper上验证了该协议,并发现新的无模型选择器LSTD-Tournament表现出良好的经验性能。
🔬 方法详解
问题定义:离线策略评估(OPE)旨在利用历史数据评估新策略的性能,是离线强化学习中的关键环节。然而,现有的OPE方法,如重要性采样,可能面临高方差问题;而其他方法,如FQE和基于模型的方法,则依赖于超参数的选择。如何有效地选择合适的OPE模型或超参数,以准确评估目标策略的性能,是一个重要的挑战。现有方法在生成候选值函数时不够稳定,缺乏对无模型和基于模型方法的统一评估框架。
核心思路:本文的核心思路是设计新的模型选择器,并构建一个更稳定、可控的实验协议,用于评估不同的OPE方法。通过改进候选值函数的生成方式,并提供统一的评估框架,可以更准确地选择最佳的OPE模型或超参数,从而提高离线策略评估的可靠性。
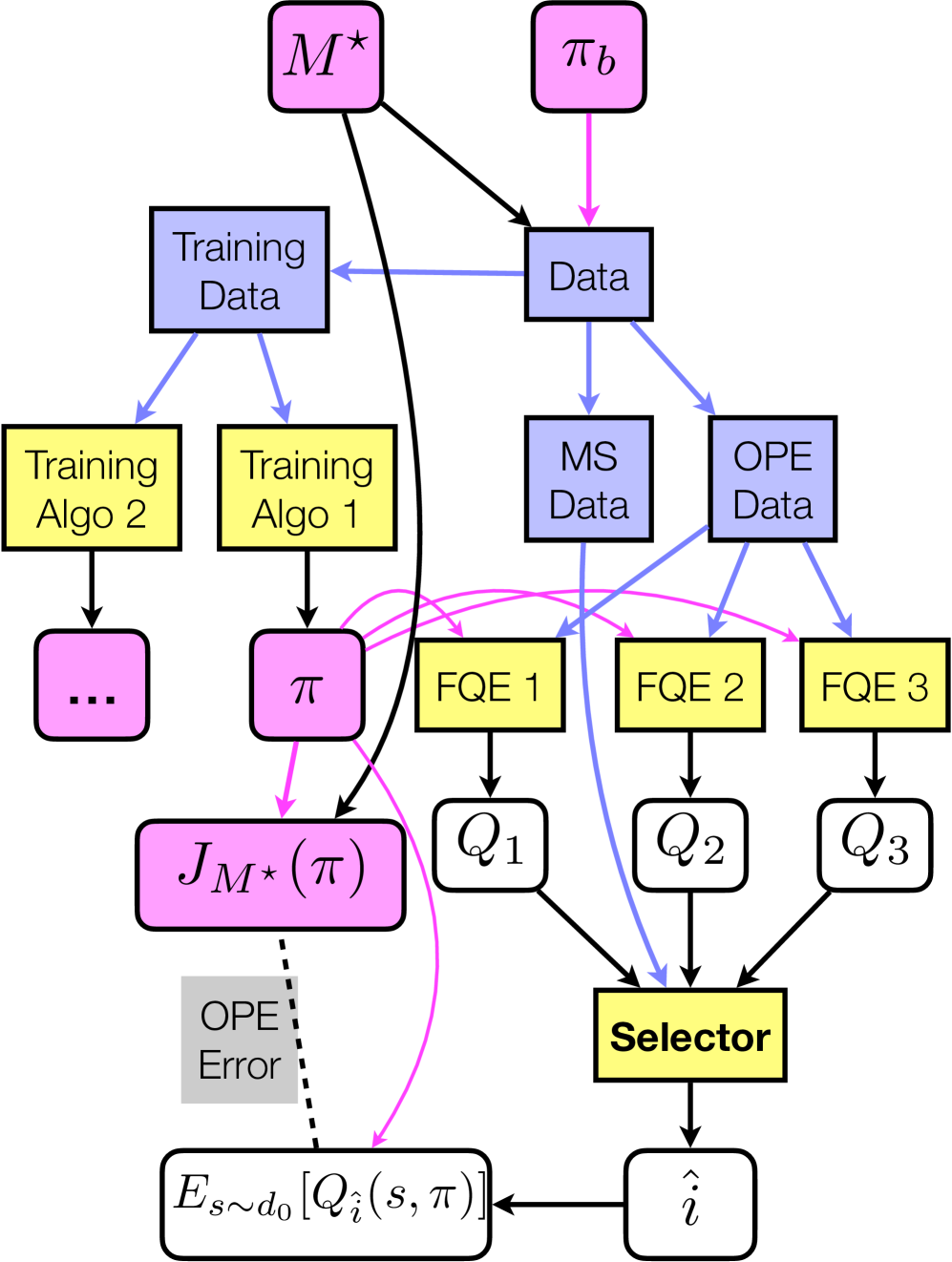
技术框架:本文的技术框架主要包括两个部分:新的模型选择器和新的实验协议。模型选择器包括无模型和基于模型两种类型,用于从候选值函数或动力学模型中选择最佳的评估器。实验协议则提供了一个更稳定、可控的评估环境,用于比较不同的OPE方法。具体流程包括:生成候选值函数/动力学模型,使用模型选择器选择最佳评估器,然后评估目标策略的性能。
关键创新:本文的关键创新在于提出了新的模型选择器和实验协议,解决了现有方法在模型选择和评估方面的不足。新的实验协议允许更稳定地生成候选值函数,并提供了一个统一的框架,用于评估无模型和基于模型的方法。此外,提出的LSTD-Tournament选择器在实验中表现出良好的性能。
关键设计:关于模型选择器,论文可能涉及LSTD-Tournament的具体实现细节,例如如何利用最小二乘时序差分(LSTD)算法来估计值函数,以及如何设计Tournament选择机制来选择最佳的评估器。关于实验协议,关键设计可能包括如何生成候选值函数,如何控制候选值函数的质量,以及如何设计评估指标来衡量OPE方法的性能。这些细节在论文中应该有更详细的描述,但具体参数设置和网络结构等信息未知。
🖼️ 关键图片
📊 实验亮点
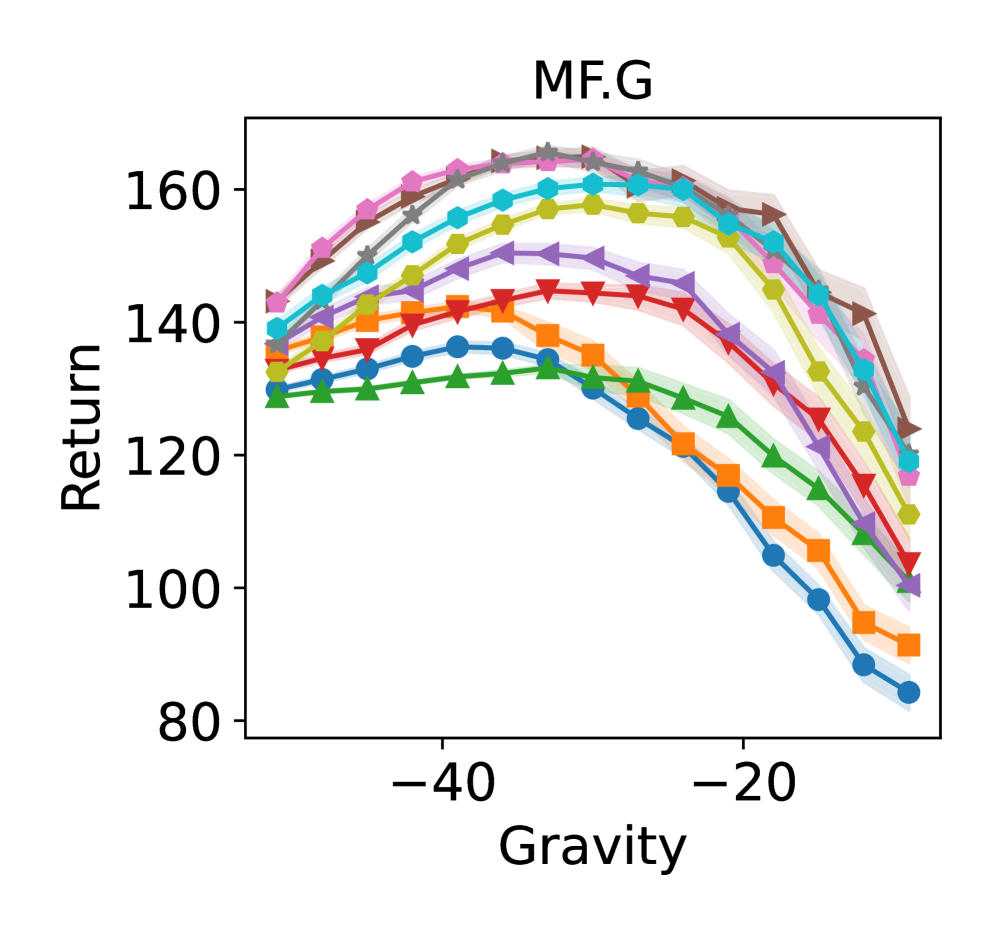
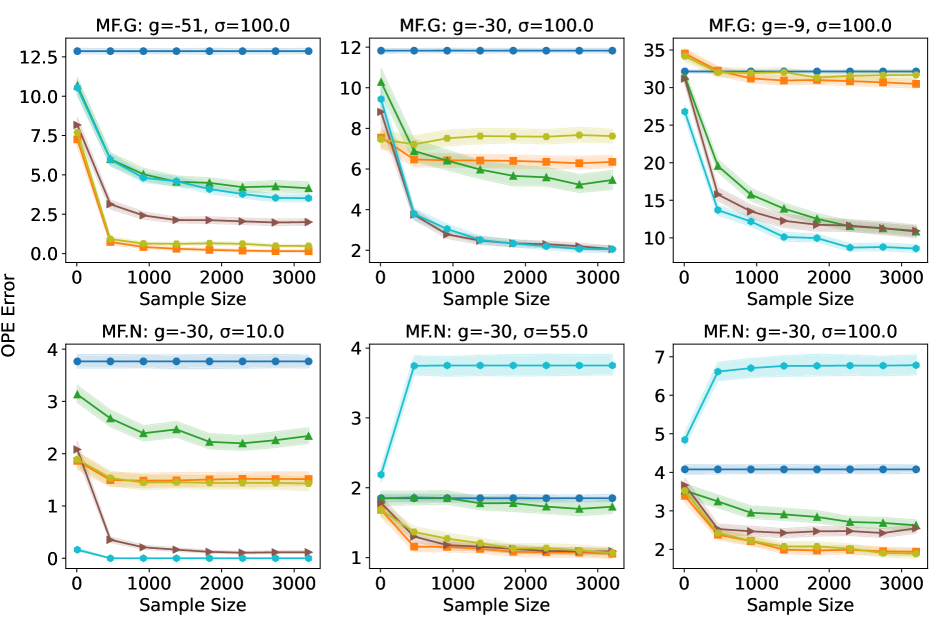
实验结果表明,提出的无模型选择器LSTD-Tournament在Gym-Hopper环境中表现出良好的性能。具体性能数据和对比基线未知,但论文强调了LSTD-Tournament在实验中的优势,表明其在离线策略评估方面具有潜力。
🎯 应用场景
该研究成果可应用于各种需要离线策略评估的场景,例如推荐系统、医疗决策、自动驾驶等。通过更准确地评估策略性能,可以降低试错成本,加速策略迭代,并最终提升系统的整体性能。该研究对于推动离线强化学习的实际应用具有重要意义。
📄 摘要(原文)
Holdout validation and hyperparameter tuning from data is a long-standing problem in offline reinforcement learning (RL). A standard framework is to use off-policy evaluation (OPE) methods to evaluate and select the policies, but OPE either incurs exponential variance (e.g., importance sampling) or has hyperparameters on their own (e.g., FQE and model-based). We focus on hyperparameter tuning for OPE itself, which is even more under-investigated. Concretely, we select among candidate value functions ("model-free") or dynamics ("model-based") to best assess the performance of a target policy. Concretely, we select among candidate value functions (
model-free'') or dynamics models (model-based'') to best assess the performance of a target policy. We develop: (1) new model-free and model-based selectors with theoretical guarantees, and (2) a new experimental protocol for empirically evaluating them. Compared to the model-free protocol in prior works, our new protocol allows for more stable generation and better control of candidate value functions in an optimization-free manner, and evaluation of model-free and model-based methods alike. We exemplify the protocol on Gym-Hopper, and find that our new model-free selector, LSTD-Tournament, demonstrates promising empirical performance.