CIRCUIT: A Benchmark for Circuit Interpretation and Reasoning Capabilities of LLMs
作者: Lejla Skelic, Yan Xu, Matthew Cox, Wenjie Lu, Tao Yu, Ruonan Han
分类: cs.LG, cs.AI
发布日期: 2025-02-11
💡 一句话要点
提出CIRCUIT基准数据集,评估LLM在电路推理方面的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模拟电路设计 基准数据集 电路推理 单元测试
📋 核心要点
- 现有方法缺乏对LLM在模拟电路设计中推理能力的有效评估,阻碍了LLM在该领域的应用。
- 论文构建CIRCUIT数据集,包含多层次模拟电路问题,并设计单元测试评估LLM的鲁棒性。
- 实验表明,即使是GPT-4o在CIRCUIT数据集上的表现也远未达到理想水平,尤其是在电路拓扑理解方面。
📝 摘要(中文)
大型语言模型(LLM)在模拟电路设计中的作用尚未得到充分探索,而模拟电路设计可以受益于超越传统优化技术的基于推理的方法。特别地,尽管LLM越来越重要,但目前还没有基准来评估LLM关于电路的推理能力。因此,我们创建了CIRCUIT数据集,该数据集包含510个问题-答案对,涵盖了各种级别的模拟电路相关主题。在我们数据集上表现最佳的模型GPT-4o在评估最终数值答案时达到了48.04%的准确率。为了评估LLM在我们数据集上的鲁棒性,我们引入了一个独特的特性,通过将问题分组到单元测试中来实现类似单元测试的评估。在这种情况下,GPT-4o只能通过27.45%的单元测试,这突显了最先进的LLM仍然难以理解电路,这需要多层次的推理,尤其是在涉及电路拓扑时。这个特定于电路的基准突出了LLM的局限性,为推进其在模拟集成电路设计中的应用提供了宝贵的见解。
🔬 方法详解
问题定义:论文旨在解决缺乏有效基准来评估LLM在模拟电路设计中推理能力的问题。现有方法主要集中在优化技术,而忽略了LLM基于推理的潜力。因此,需要一个专门的基准来评估LLM对电路的理解和推理能力,尤其是在涉及电路拓扑等复杂概念时。
核心思路:论文的核心思路是构建一个包含各种模拟电路相关问题的基准数据集,并设计一种单元测试方法来评估LLM的鲁棒性。通过分析LLM在不同类型问题上的表现,可以深入了解其在电路理解和推理方面的优势和局限性。
技术框架:CIRCUIT数据集包含510个问题-答案对,涵盖不同级别的模拟电路主题。数据集中的问题被分组到单元测试中,每个单元测试包含一组相关的问题,用于评估LLM在特定电路概念上的理解一致性。评估过程包括将问题输入LLM,并比较LLM的输出与ground truth。
关键创新:论文的关键创新在于构建了专门用于评估LLM电路推理能力的CIRCUIT数据集,并引入了单元测试方法来评估LLM的鲁棒性。这种单元测试方法能够更细粒度地评估LLM在特定电路概念上的理解一致性,从而更好地揭示LLM的局限性。
关键设计:数据集中的问题涵盖了各种模拟电路主题,包括基本电路元件、电路定律、电路拓扑、电路分析和电路设计。单元测试的设计旨在评估LLM在特定电路概念上的理解一致性,例如,一个单元测试可能包含一组关于特定电路拓扑的电压和电流计算问题。评估指标包括最终数值答案的准确率和单元测试的通过率。
🖼️ 关键图片
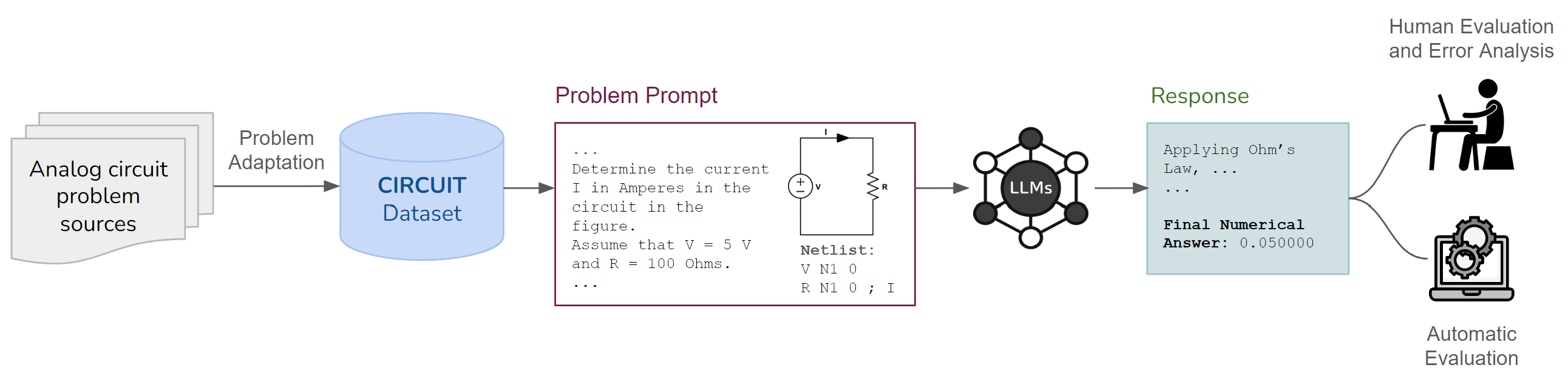
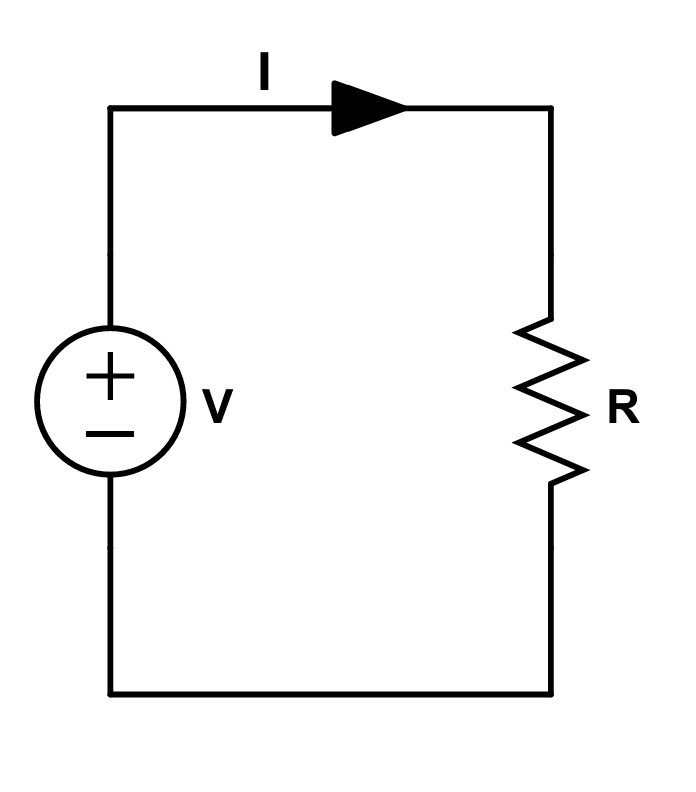
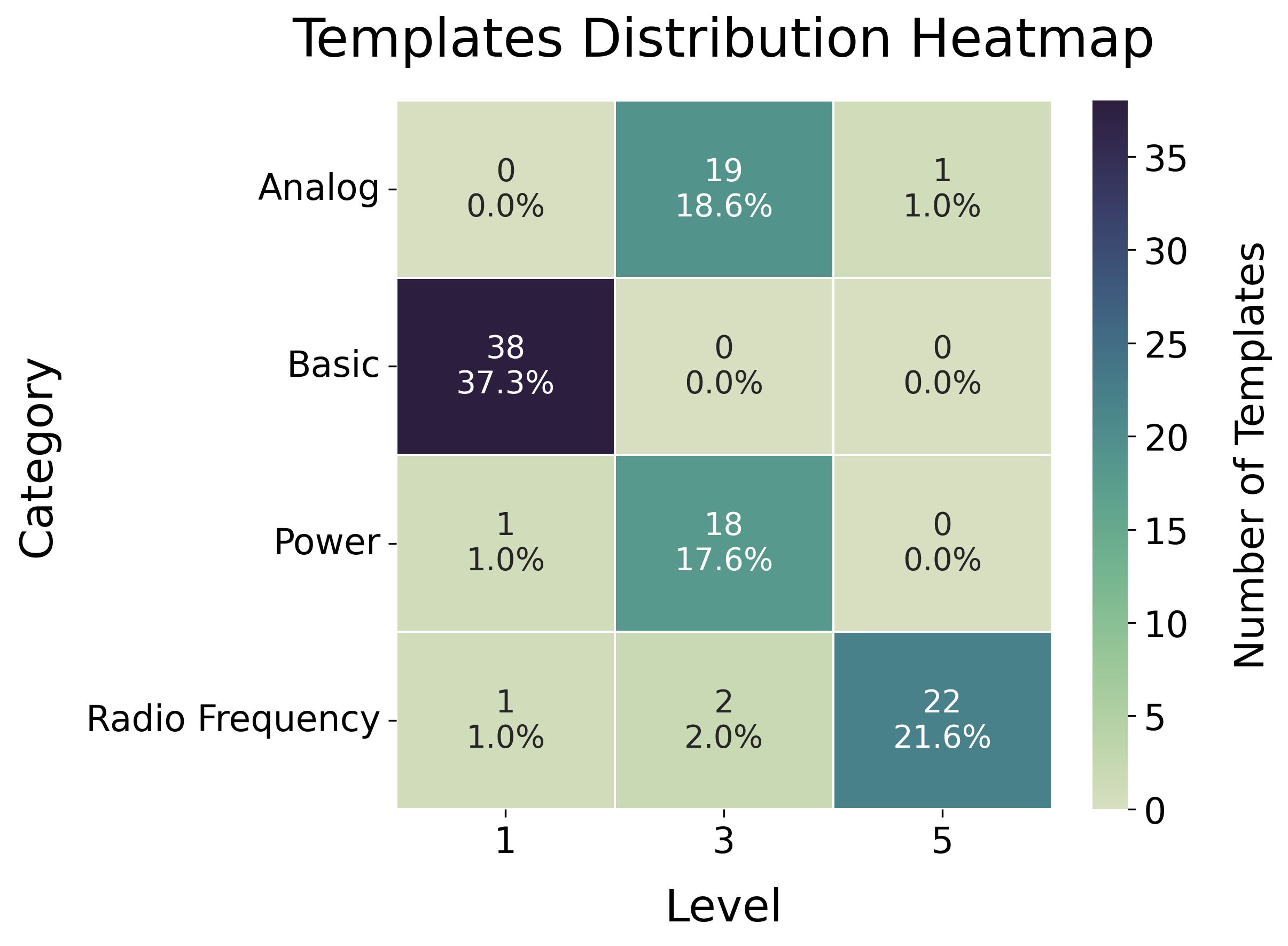
📊 实验亮点
实验结果表明,即使是GPT-4o在CIRCUIT数据集上的最终数值答案准确率也仅为48.04%。更重要的是,在单元测试评估中,GPT-4o的通过率仅为27.45%,这表明LLM在理解电路,特别是涉及电路拓扑时,仍然面临很大的挑战。这些结果突出了LLM在电路推理方面的局限性,并为未来的研究方向提供了有价值的参考。
🎯 应用场景
该研究成果可应用于评估和改进LLM在模拟集成电路设计领域的应用。通过CIRCUIT基准数据集,研究人员可以更好地了解LLM在电路理解和推理方面的能力,并开发更有效的LLM应用方案,例如辅助电路设计、故障诊断和性能优化等。该基准也有助于推动LLM在其他工程领域的应用。
📄 摘要(原文)
The role of Large Language Models (LLMs) has not been extensively explored in analog circuit design, which could benefit from a reasoning-based approach that transcends traditional optimization techniques. In particular, despite their growing relevance, there are no benchmarks to assess LLMs' reasoning capability about circuits. Therefore, we created the CIRCUIT dataset consisting of 510 question-answer pairs spanning various levels of analog-circuit-related subjects. The best-performing model on our dataset, GPT-4o, achieves 48.04% accuracy when evaluated on the final numerical answer. To evaluate the robustness of LLMs on our dataset, we introduced a unique feature that enables unit-test-like evaluation by grouping questions into unit tests. In this case, GPT-4o can only pass 27.45% of the unit tests, highlighting that the most advanced LLMs still struggle with understanding circuits, which requires multi-level reasoning, particularly when involving circuit topologies. This circuit-specific benchmark highlights LLMs' limitations, offering valuable insights for advancing their application in analog integrated circuit design.