Advancing Autonomous VLM Agents via Variational Subgoal-Conditioned Reinforcement Learning
作者: Qingyuan Wu, Jianheng Liu, Jianye Hao, Jun Wang, Kun Shao
分类: cs.LG, cs.AI
发布日期: 2025-02-11 (更新: 2025-05-20)
💡 一句话要点
提出VSC-RL,通过变分子目标强化学习提升自主VLM Agent在复杂任务中的效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 视觉语言模型 自主Agent 变分推断 子目标学习 决策任务 稀疏奖励 长程依赖
📋 核心要点
- 现有强化学习方法在处理稀疏奖励和长程依赖的复杂现实决策任务时,学习效率低下。
- VSC-RL将决策问题重构为变分推断问题,通过最大化子目标条件回报和最小化策略差异来优化学习。
- 实验结果表明,VSC-RL在多个复杂任务上显著优于现有方法,提升了学习效率和性能。
📝 摘要(中文)
本文提出了一种新的框架,即变分子目标条件强化学习(VSC-RL),旨在提升视觉语言模型(VLM)Agent在解决复杂决策任务时的能力。与现有方法不同,VSC-RL将决策问题重新定义为一个变分子目标条件强化学习问题,并提出了新的优化目标,即子目标证据下界(SGC-ELBO)。SGC-ELBO包含两个关键组成部分:(a) 最大化子目标条件回报,以及 (b) 最小化与参考目标条件策略的差异。理论和实验均表明,VSC-RL能够有效提高学习效率,且不影响性能保证。在包括移动设备和Web控制任务在内的各种具有挑战性的基准测试中,VSC-RL始终优于现有的SOTA方法,实现了卓越的学习效率和性能。
🔬 方法详解
问题定义:论文旨在解决VLM Agent在复杂、稀疏奖励和长程依赖的决策任务中学习效率低下的问题。现有方法难以有效探索环境,导致学习速度慢,难以达到最优性能。
核心思路:论文的核心思路是将强化学习问题转化为一个变分子目标条件强化学习问题。通过引入子目标的概念,将复杂的任务分解为多个更容易学习的子任务,从而引导Agent进行更有效的探索。同时,利用变分推断的思想,学习一个子目标条件策略,并使其接近一个参考目标条件策略,从而保证学习的稳定性和性能。
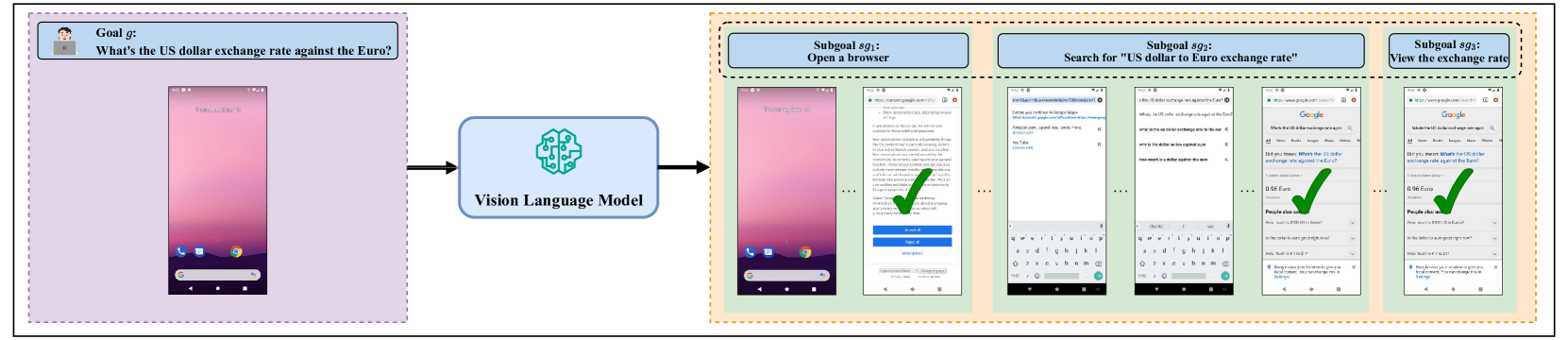
技术框架:VSC-RL框架包含以下主要模块:1) 环境交互模块:Agent与环境进行交互,收集经验数据。2) 子目标生成模块:根据当前状态和目标,生成一系列可能的子目标。3) 子目标条件策略学习模块:学习一个以子目标为条件的策略,用于指导Agent的行为。4) 目标条件策略学习模块:学习一个以目标为条件的策略,作为参考策略。5) 优化模块:利用SGC-ELBO优化目标,同时更新子目标条件策略和目标条件策略。
关键创新:VSC-RL的关键创新在于提出了SGC-ELBO优化目标,它结合了子目标条件回报最大化和策略差异最小化两个方面。与传统的强化学习方法相比,VSC-RL能够更有效地利用子目标信息,引导Agent进行更有效的探索,并保证学习的稳定性和性能。此外,将强化学习问题转化为变分推断问题,为解决复杂决策任务提供了一种新的思路。
关键设计:SGC-ELBO损失函数包含两项:一项是子目标条件回报的期望,另一项是子目标条件策略与目标条件策略之间的KL散度。通过调整这两项的权重,可以平衡探索和利用之间的关系。子目标生成模块可以使用多种方法实现,例如随机采样、基于模型的预测等。策略网络可以使用各种常见的神经网络结构,例如MLP、CNN、Transformer等。
🖼️ 关键图片

📊 实验亮点
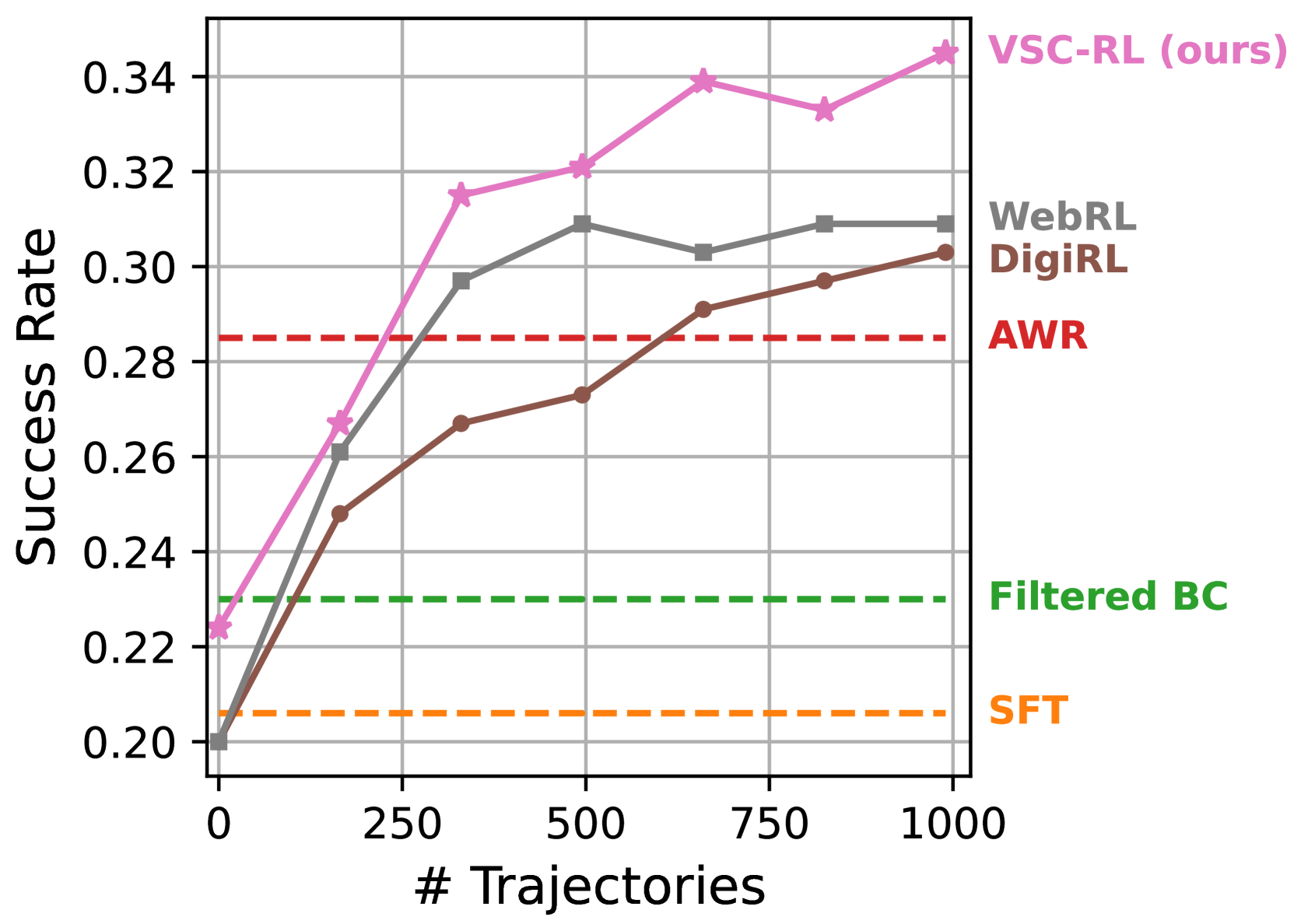
实验结果表明,VSC-RL在移动设备和Web控制等多个复杂任务上显著优于现有SOTA方法。例如,在某个Web控制任务中,VSC-RL的成功率比基线方法提高了20%以上,并且学习速度更快。这些结果证明了VSC-RL在提高学习效率和性能方面的有效性。
🎯 应用场景
VSC-RL具有广泛的应用前景,例如机器人控制、游戏AI、自动驾驶、智能助手等。该方法可以帮助Agent在复杂、不确定的环境中学习到有效的策略,从而实现自主决策和控制。尤其在需要与视觉和语言信息交互的场景下,VSC-RL能够充分利用VLM的优势,实现更智能化的Agent。
📄 摘要(原文)
State-of-the-art (SOTA) reinforcement learning (RL) methods have enabled vision-language model (VLM) agents to learn from interaction with online environments without human supervision. However, these methods often struggle with learning inefficiencies when applied to complex, real-world decision-making tasks with sparse rewards and long-horizon dependencies. We propose a novel framework, Variational Subgoal-Conditioned Reinforcement Learning (VSC-RL), advancing the VLM agents in resolving challenging decision-making tasks. Fundamentally distinct from existing methods, VSC-RL reformulates the decision-making problem as a variational subgoal-conditioned RL problem with the newly derived optimization objective, Subgoal Evidence Lower BOund (SGC-ELBO), which comprises two key components: (a) maximizing the subgoal-conditioned return, and (b) minimizing the divergence from a reference goal-conditioned policy. We theoretically and empirically demonstrate that the VSC-RL can efficiently improve the learning efficiency without compromising performance guarantees. Across a diverse set of challenging benchmarks, including mobile device and web control tasks, VSC-RL consistently outperforms existing SOTA methods, achieving superior learning efficiency and performance.