DarwinLM: Evolutionary Structured Pruning of Large Language Models
作者: Shengkun Tang, Oliver Sieberling, Eldar Kurtic, Zhiqiang Shen, Dan Alistarh
分类: cs.LG, cs.CL
发布日期: 2025-02-11 (更新: 2025-03-05)
备注: Code: https://github.com/IST-DASLab/DarwinLM
🔗 代码/项目: GITHUB
💡 一句话要点
DarwinLM:通过演化结构化剪枝压缩大型语言模型,提升推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 结构化剪枝 演化算法 模型压缩 训练感知 轻量级训练 推理加速
📋 核心要点
- 大型语言模型计算成本高昂,限制了其在实时应用中的部署,因此需要有效的模型压缩方法。
- DarwinLM 提出了一种训练感知的演化结构化剪枝方法,通过演化搜索和轻量级多步训练,寻找最优子结构。
- 实验表明,DarwinLM 在 Llama-2-7B 等模型上实现了最先进的结构化剪枝性能,且所需训练数据更少。
📝 摘要(中文)
大型语言模型(LLMs)在各种NLP任务中取得了显著成功。然而,它们巨大的计算成本限制了其广泛应用,尤其是在实时应用中。结构化剪枝提供了一种有效的解决方案,通过压缩模型并直接提供端到端的速度改进,而与硬件环境无关。同时,模型的不同组件对剪枝的敏感性不同,需要非均匀模型压缩。然而,剪枝方法不仅应识别出有能力的子结构,还应考虑压缩后的训练。为此,我们提出DarwinLM,一种训练感知的结构化剪枝方法。DarwinLM建立在演化搜索过程之上,通过变异在每一代中生成多个后代模型,并选择最适合生存的模型。为了评估后训练的效果,我们在后代群体中加入了一个轻量级的多步训练过程,逐步增加token数量,并在每个选择阶段淘汰表现不佳的模型。我们通过在Llama-2-7B、Llama-3.1-8B和Qwen-2.5-14B-Instruct上的大量实验验证了我们的方法,实现了结构化剪枝的最先进性能。例如,DarwinLM超越了ShearedLlama,同时在压缩后训练期间需要少5倍的训练数据。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)计算成本高昂,难以在资源受限的场景下部署的问题。现有的结构化剪枝方法通常没有充分考虑剪枝后模型的再训练,导致性能下降或需要大量的训练数据才能恢复性能。
核心思路:论文的核心思路是采用演化算法来搜索最优的剪枝结构,并在演化过程中引入轻量级的训练步骤,以评估剪枝后模型的可训练性。通过模拟自然选择的过程,逐步筛选出既能有效压缩模型,又能保持良好性能的子结构。
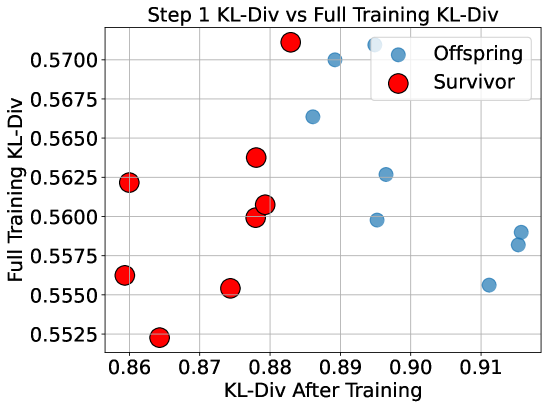
技术框架:DarwinLM 的整体框架包含以下几个主要阶段:1) 初始化:随机生成一组初始模型(种群)。2) 变异:对种群中的每个模型进行变异,生成新的后代模型,变异操作包括随机剪枝模型的不同部分。3) 训练:对每个后代模型进行轻量级的多步训练,逐步增加训练数据量。4) 选择:根据模型在训练过程中的性能指标(如验证集准确率),选择表现最好的模型进入下一代。重复变异、训练和选择的过程,直到达到预定的迭代次数。
关键创新:DarwinLM 的关键创新在于将训练过程融入到演化搜索中,实现了训练感知的剪枝。通过在演化过程中评估模型的可训练性,可以更有效地找到适合再训练的子结构,从而减少了对大量训练数据的依赖。
关键设计:在演化过程中,论文采用了多步训练策略,即逐步增加训练数据量。这样做的好处是可以先快速评估模型的潜力,再投入更多的资源进行精细化训练。此外,论文还设计了特定的变异算子,用于控制剪枝的比例和位置,以保证搜索空间的有效性。具体的损失函数和网络结构沿用了原始模型的设置。
🖼️ 关键图片


📊 实验亮点
DarwinLM 在 Llama-2-7B、Llama-3.1-8B 和 Qwen-2.5-14B-Instruct 等模型上取得了显著的性能提升,实现了结构化剪枝的最先进水平。例如,DarwinLM 在性能超越 ShearedLlama 的同时,所需压缩后训练数据减少了 5 倍。这些结果表明,DarwinLM 是一种高效且有效的 LLM 压缩方法。
🎯 应用场景
DarwinLM 具有广泛的应用前景,可用于在边缘设备、移动设备等资源受限的环境中部署大型语言模型。通过降低模型的计算成本和存储需求,可以实现更快的推理速度和更低的功耗,从而扩展 LLM 的应用范围,例如智能助手、实时翻译、文本摘要等。
📄 摘要(原文)
Large Language Models (LLMs) have achieved significant success across various NLP tasks. However, their massive computational costs limit their widespread use, particularly in real-time applications. Structured pruning offers an effective solution by compressing models and directly providing end-to-end speed improvements, regardless of the hardware environment. Meanwhile, different components of the model exhibit varying sensitivities towards pruning, calling for non-uniform model compression. However, a pruning method should not only identify a capable substructure, but also account for post-compression training. To this end, we propose DarwinLM, a method for training-aware structured pruning. DarwinLM builds upon an evolutionary search process, generating multiple offspring models in each generation through mutation, and selecting the fittest for survival. To assess the effect of post-training, we incorporate a lightweight, multistep training process within the offspring population, progressively increasing the number of tokens and eliminating poorly performing models in each selection stage. We validate our method through extensive experiments on Llama-2-7B, Llama-3.1-8B and Qwen-2.5-14B-Instruct, achieving state-of-the-art performance for structured pruning. For instance, DarwinLM surpasses ShearedLlama while requiring 5x less training data during post-compression training. Code is at: https://github.com/IST-DASLab/DarwinLM