Towards Efficient Optimizer Design for LLM via Structured Fisher Approximation with a Low-Rank Extension
作者: Wenbo Gong, Meyer Scetbon, Chao Ma, Edward Meeds
分类: cs.LG, cs.AI, stat.ML
发布日期: 2025-02-11 (更新: 2025-02-20)
💡 一句话要点
提出基于结构化Fisher近似和低秩扩展的高效LLM优化器设计方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 优化器设计 Fisher信息矩阵 低秩近似 内存效率
📋 核心要点
- 现有LLM优化器面临内存需求高、收敛速度慢的挑战,限制了模型训练的效率和可扩展性。
- 论文提出基于结构化FIM近似的优化器设计方法,通过选择合适的结构假设和低秩扩展来平衡效率和通用性。
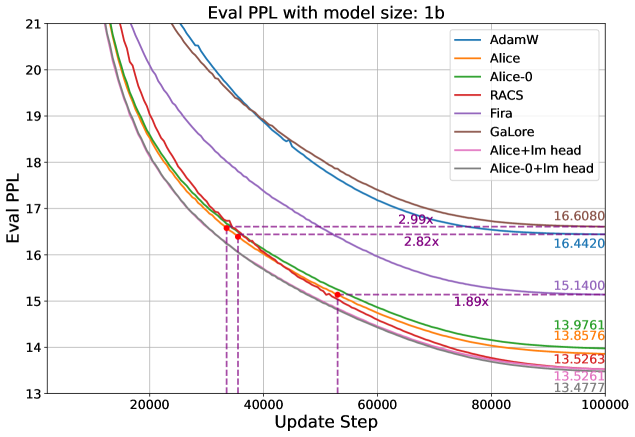
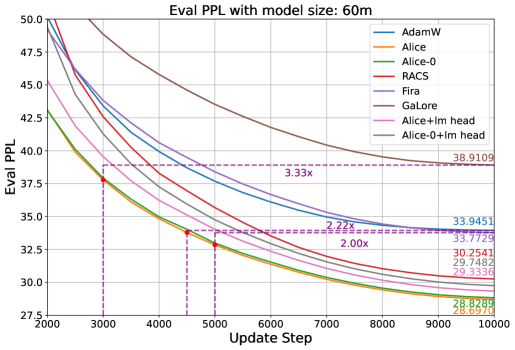
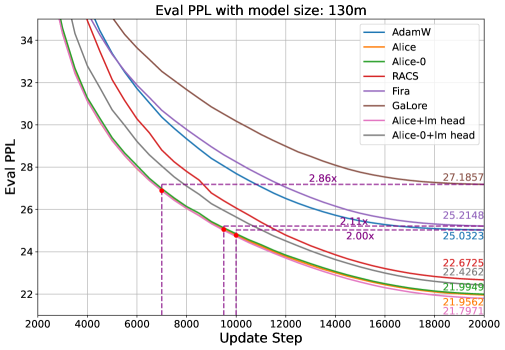
- 实验表明,提出的RACS和Alice优化器在LLaMA预训练中,相比现有方法,收敛速度更快,内存开销更小。
📝 摘要(中文)
本文致力于为大型语言模型(LLM)设计高效优化器,旨在降低内存需求并加速收敛。研究通过结构化Fisher信息矩阵(FIM)近似的视角,系统性地设计此类优化器。结果表明,许多先进的高效优化器可以被视为在特定结构假设下,对FIM进行Frobenius范数近似的解。基于此,论文提出了两个实用的LLM高效优化器设计建议:一是仔细选择结构假设,以平衡通用性和效率;二是利用新颖的低秩扩展框架,增强具有通用结构的优化器的内存效率。论文通过推导新的内存高效优化器Row and Column Scaled SGD (RACS) 和Adaptive low-dimensional subspace estimation (Alice)来展示了每种设计方法的应用。在LLaMA预训练(参数高达10亿)上的实验验证了其有效性,表明与现有的内存高效基线和Adam相比,收敛速度更快、效果更好,且内存开销很小。值得注意的是,Alice的收敛速度比Adam快2倍以上,而RACS在10亿参数模型上实现了类似SGD的内存性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)训练过程中优化器内存需求高、收敛速度慢的问题。现有的优化器,如Adam,虽然收敛速度较快,但需要存储大量的中间变量,导致内存开销巨大,限制了模型规模的扩展。而传统的SGD虽然内存开销小,但收敛速度慢,难以满足LLM的训练需求。
核心思路:论文的核心思路是将优化器的设计问题转化为Fisher信息矩阵(FIM)的近似问题。通过对FIM进行结构化近似,可以在保证优化性能的同时,降低计算和存储复杂度。此外,论文还提出了低秩扩展框架,进一步降低优化器的内存需求。这样设计的目的是在通用性和效率之间取得平衡,从而设计出适用于LLM训练的高效优化器。
技术框架:论文的技术框架主要包括两个部分:1) 基于结构化FIM近似的优化器设计:首先,分析现有优化器与FIM近似之间的关系,然后,选择合适的结构假设,例如行/列缩放,来简化FIM的计算。2) 基于低秩扩展的优化器内存优化:利用低秩矩阵分解技术,将优化器中的高维矩阵分解为低维矩阵的乘积,从而降低内存需求。整体流程是先通过结构化FIM近似设计出初步的优化器,然后通过低秩扩展进一步优化其内存效率。
关键创新:论文最重要的技术创新点在于将优化器设计问题与FIM近似问题联系起来,并提出了结构化FIM近似和低秩扩展两种优化方法。与现有方法相比,该方法能够更系统地设计高效优化器,并在内存效率和优化性能之间取得更好的平衡。此外,提出的RACS和Alice优化器是该方法的具体实现,并在实验中取得了显著的效果。
关键设计:RACS优化器通过对SGD的行和列进行缩放来近似FIM,其关键设计在于如何选择合适的缩放因子。Alice优化器则通过低维子空间估计来近似FIM,其关键设计在于如何选择合适的子空间维度和更新策略。此外,论文还详细描述了如何将低秩扩展应用于不同的优化器,以及如何选择合适的低秩维度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的RACS和Alice优化器在LLaMA预训练任务中表现出色。Alice优化器在收敛速度上优于Adam 2倍以上,同时保持较低的内存开销。RACS优化器在10亿参数的LLaMA模型上实现了与SGD相似的内存占用,同时取得了更好的优化效果。这些结果验证了所提出方法的有效性。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的预训练和微调,尤其是在资源受限的环境下。通过降低优化器的内存需求和加速收敛,可以支持更大规模模型的训练,并缩短训练时间。此外,该方法还可以应用于其他深度学习模型的优化,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Designing efficient optimizers for large language models (LLMs) with low-memory requirements and fast convergence is an important and challenging problem. This paper makes a step towards the systematic design of such optimizers through the lens of structured Fisher information matrix (FIM) approximation. We show that many state-of-the-art efficient optimizers can be viewed as solutions to FIM approximation (under the Frobenius norm) with specific structural assumptions. Building on these insights, we propose two design recommendations of practical efficient optimizers for LLMs, involving the careful selection of structural assumptions to balance generality and efficiency, and enhancing memory efficiency of optimizers with general structures through a novel low-rank extension framework. We demonstrate how to use each design approach by deriving new memory-efficient optimizers: Row and Column Scaled SGD (RACS) and Adaptive low-dimensional subspace estimation (Alice). Experiments on LLaMA pre-training (up to 1B parameters) validate the effectiveness, showing faster and better convergence than existing memory-efficient baselines and Adam with little memory overhead. Notably, Alice achieves better than 2x faster convergence over Adam, while RACS delivers strong performance on the 1B model with SGD-like memory.