Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
作者: Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, Tom Goldstein
分类: cs.LG, cs.CL
发布日期: 2025-02-07 (更新: 2025-02-17)
备注: The model is available at https://huggingface.co/tomg-group-umd/huginn-0125. Code and data recipe can be found at https://github.com/seal-rg/recurrent-pretraining
💡 一句话要点
提出基于隐空间推理的循环深度语言模型,提升测试时计算能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 隐空间推理 循环神经网络 语言模型 测试时计算 深度学习 自然语言处理 推理基准测试
📋 核心要点
- 现有语言模型扩展计算能力主要依赖生成更多token,但需要大量训练数据且推理类型受限。
- 论文提出一种基于隐空间推理的循环深度模型,通过迭代循环块在测试时扩展计算深度。
- 实验结果表明,该模型在推理基准测试中性能显著提升,计算负载可扩展至500亿参数。
📝 摘要(中文)
本文研究了一种新型语言模型架构,该架构能够通过在隐空间中进行隐式推理来扩展测试时的计算能力。我们的模型通过迭代一个循环块来实现,从而在测试时展开到任意深度。这与通过生成更多token来扩展计算能力的主流推理模型形成对比。与基于思维链的方法不同,我们的方法不需要任何专门的训练数据,可以使用小的上下文窗口,并且可以捕获难以用语言表达的推理类型。我们将一个概念验证模型扩展到35亿参数和8000亿token。我们表明,由此产生的模型可以提高其在推理基准上的性能,有时会显著提高,直至达到相当于500亿参数的计算负载。
🔬 方法详解
问题定义:现有语言模型在进行复杂推理时,通常依赖于生成大量的token序列(如Chain-of-Thought),这不仅增加了计算成本,而且需要大量的专门训练数据。此外,某些类型的推理难以用自然语言直接表达,限制了模型的推理能力。现有方法的痛点在于计算效率低、训练数据依赖性强以及推理能力受限。
核心思路:论文的核心思路是在隐空间中进行迭代推理,而不是直接在token空间中生成。通过循环迭代一个推理块,模型可以在隐空间中逐步 refinement 其对问题的理解和解决方案。这种方法允许模型在测试时动态调整计算深度,而无需重新训练。
技术框架:该模型的核心是一个循环块,该循环块接收一个隐状态作为输入,并输出更新后的隐状态。在测试时,该循环块可以被迭代多次,从而允许模型逐步 refine 其推理过程。整体架构包含一个输入编码器,将输入文本编码为初始隐状态;一个循环推理块,负责在隐空间中进行迭代推理;以及一个输出解码器,将最终的隐状态解码为输出文本。
关键创新:最重要的技术创新点在于将推理过程从显式的token生成转移到隐空间的迭代 refinement。与传统的Chain-of-Thought方法相比,该方法不需要专门的训练数据,可以使用更小的上下文窗口,并且可以捕获难以用语言表达的推理类型。此外,该方法允许模型在测试时动态调整计算深度,从而实现更高效的计算。
关键设计:论文中没有明确给出关键参数设置、损失函数和网络结构的具体细节。但是,可以推断,循环推理块的设计至关重要,可能采用了Transformer或其他循环神经网络结构。损失函数可能包括语言建模损失和一些辅助损失,以鼓励隐空间中的有效推理。循环块的迭代次数是一个关键的超参数,控制着模型的计算深度。
🖼️ 关键图片
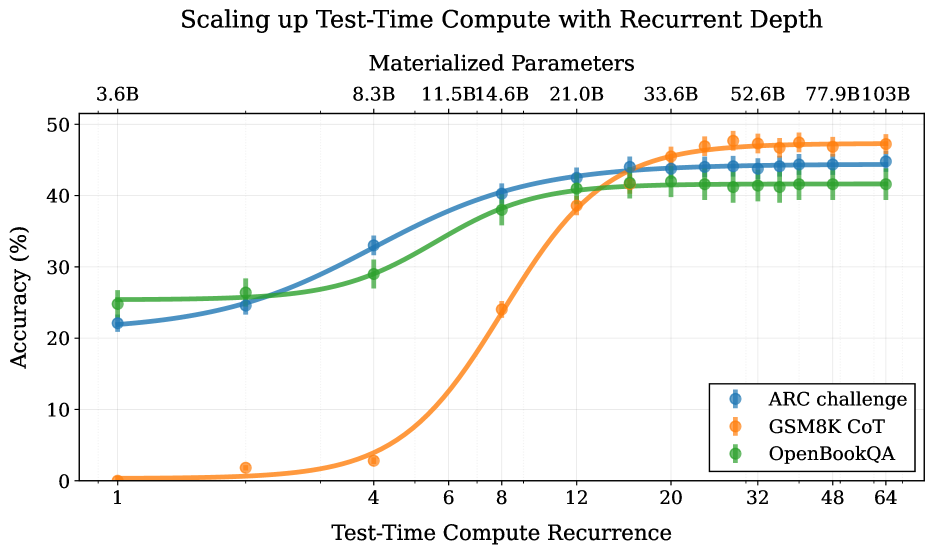


📊 实验亮点
该模型在推理基准测试中表现出色,通过增加测试时的计算量,性能得到了显著提升。具体而言,该模型在某些任务上达到了相当于500亿参数模型的性能水平,而实际参数量仅为35亿。这表明该方法能够有效地利用计算资源,提高模型的推理能力。
🎯 应用场景
该研究成果可应用于需要复杂推理的自然语言处理任务,例如数学问题求解、代码生成、知识图谱推理等。其潜在价值在于降低推理计算成本,提高推理准确率,并扩展模型对非语言化推理问题的处理能力。未来可能应用于智能客服、自动化编程等领域。
📄 摘要(原文)
We study a novel language model architecture that is capable of scaling test-time computation by implicitly reasoning in latent space. Our model works by iterating a recurrent block, thereby unrolling to arbitrary depth at test-time. This stands in contrast to mainstream reasoning models that scale up compute by producing more tokens. Unlike approaches based on chain-of-thought, our approach does not require any specialized training data, can work with small context windows, and can capture types of reasoning that are not easily represented in words. We scale a proof-of-concept model to 3.5 billion parameters and 800 billion tokens. We show that the resulting model can improve its performance on reasoning benchmarks, sometimes dramatically, up to a computation load equivalent to 50 billion parameters.