QuEST: Stable Training of LLMs with 1-Bit Weights and Activations
作者: Andrei Panferov, Jiale Chen, Soroush Tabesh, Roberto L. Castro, Mahdi Nikdan, Dan Alistarh
分类: cs.LG
发布日期: 2025-02-07 (更新: 2025-06-10)
🔗 代码/项目: GITHUB
💡 一句话要点
QuEST:通过1比特权重和激活实现LLM的稳定训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量化感知训练 低比特量化 大型语言模型 梯度估计 模型压缩
📋 核心要点
- 现有量化感知训练(QAT)在极低比特(如1比特)权重和激活下,难以保证大型语言模型(LLM)训练的稳定性和精度。
- QuEST通过精确量化和信任梯度估计器,显式最小化量化梯度与全精度梯度之间的误差,从而实现稳定训练。
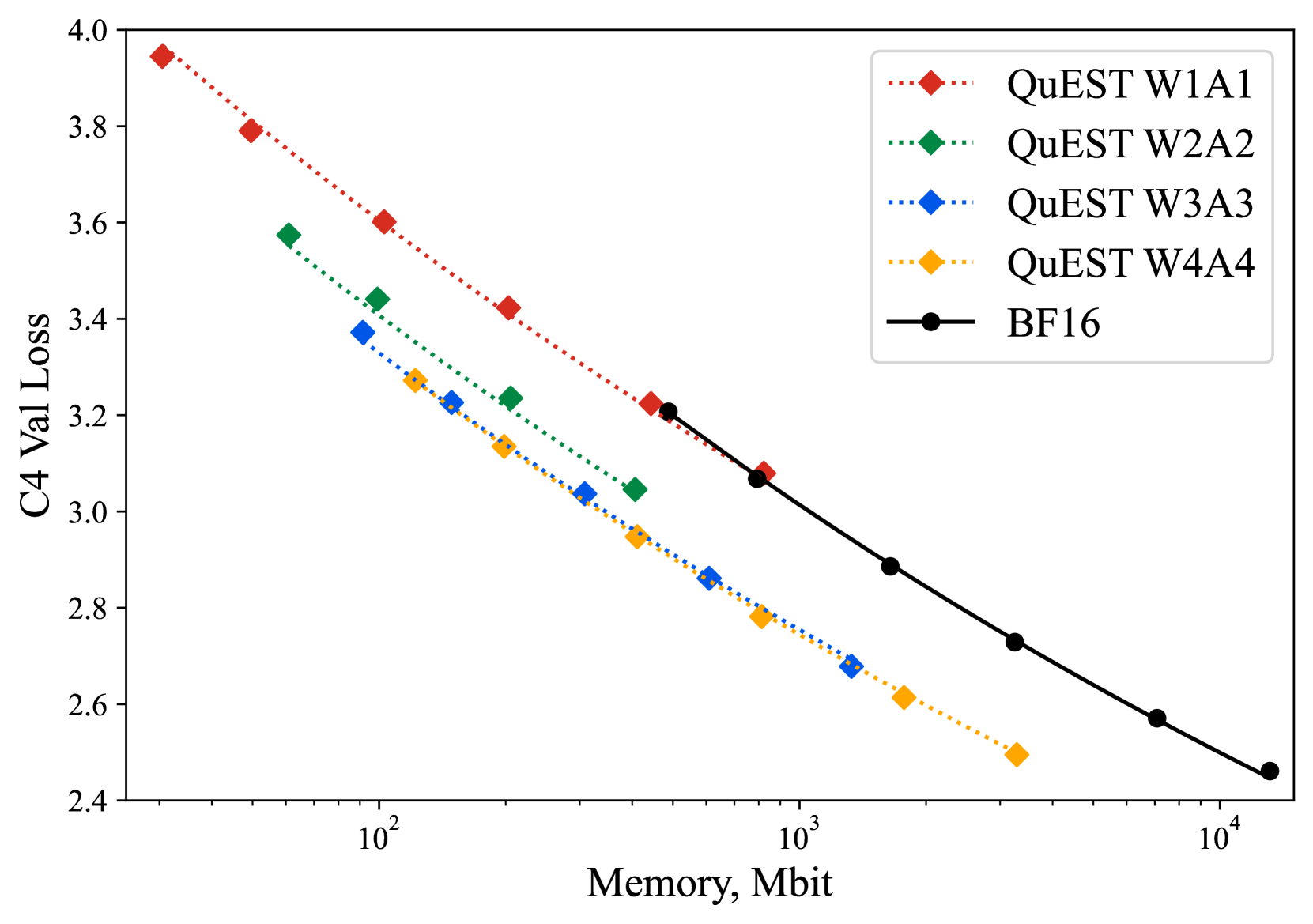
- 实验表明,QuEST在Llama架构上实现了稳定的缩放规律,并支持稀疏表示,且模型可高效执行。
📝 摘要(中文)
为了降低大型语言模型(LLM)的巨大成本,一种方法是使用量化或稀疏表示进行训练或部署。虽然训练后压缩方法非常流行,但通过直接在这些表示上进行训练,即量化感知训练(QAT),来获得更精确的压缩模型的问题仍然是开放的。例如,最近的一项研究表明,使用QAT训练模型同时保持与标准FP16/BF16精度相比具有竞争力的精度的“最佳”比特宽度是8比特权重和激活。我们通过一种名为QuEST的新方法推进了这一技术水平,我们证明了QuEST在4比特时是最优的,并且在低至1比特权重和激活时也能实现稳定的收敛。QuEST通过改进QAT方法的两个关键方面来实现这一点:(1)通过Hadamard归一化和MSE最优拟合,对权重和激活的(连续)分布进行精确和快速的量化;(2)一种新的信任梯度估计器,基于显式地最小化在量化状态下计算的噪声梯度与“真实”(但未知)全精度梯度之间的误差的思想。在Llama类型架构上的实验表明,QuEST在整个硬件支持的精度范围内都能诱导稳定的缩放规律,并且可以扩展到稀疏表示。我们提供GPU内核支持,表明QuEST产生的模型可以高效执行。我们的代码可在https://github.com/IST-DASLab/QuEST 获得。
🔬 方法详解
问题定义:论文旨在解决在极低比特(例如1比特)权重和激活下,量化感知训练(QAT)难以稳定训练大型语言模型(LLM)的问题。现有的QAT方法在低比特量化时,由于量化误差较大,会导致梯度估计不准确,从而影响训练的稳定性和最终模型的精度。
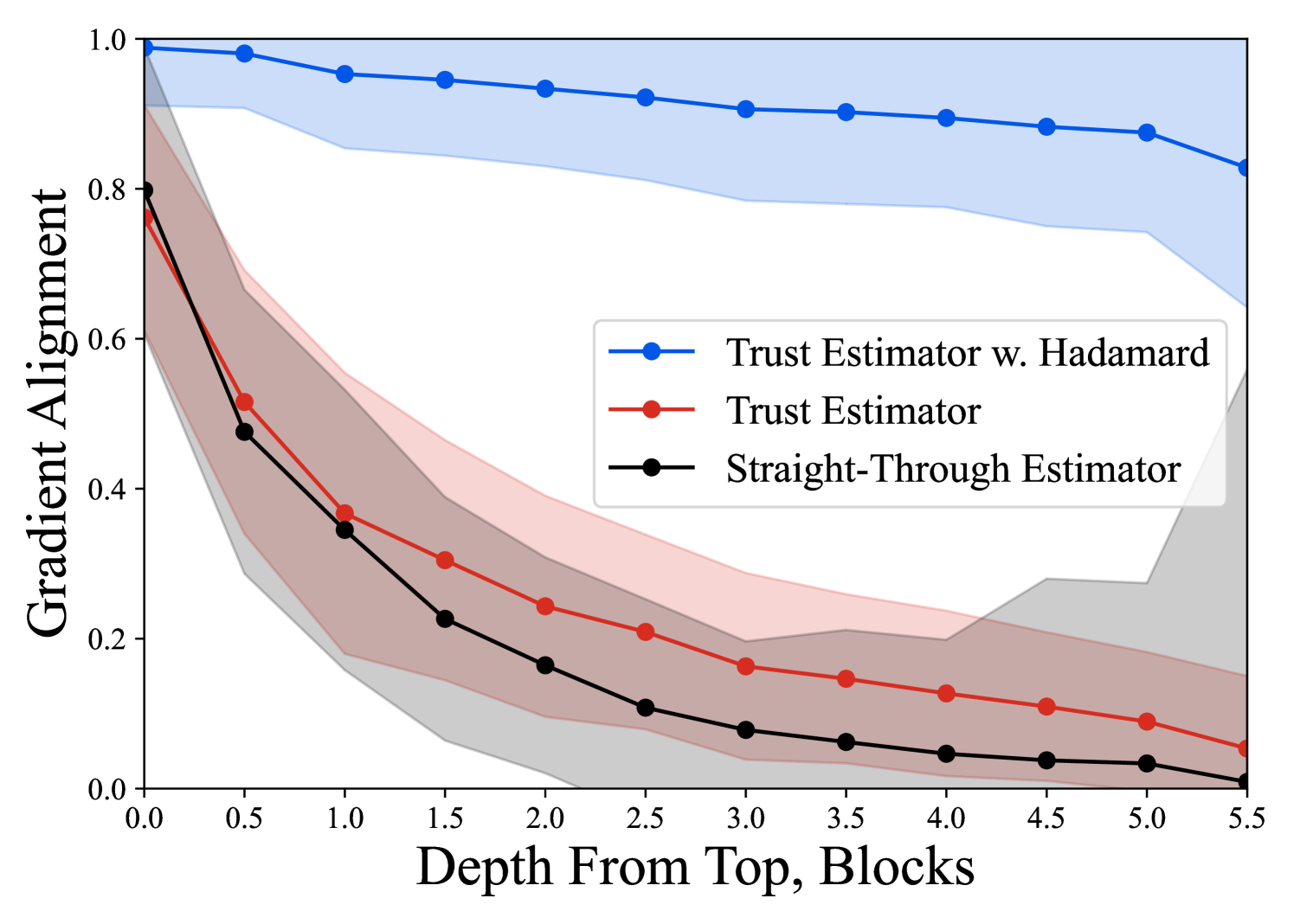
核心思路:QuEST的核心思路是通过更精确的量化方法和一种新的信任梯度估计器来减小量化误差对梯度估计的影响,从而实现低比特下的稳定训练。具体来说,QuEST首先使用Hadamard归一化和MSE最优拟合来更精确地量化权重和激活的分布。然后,QuEST提出了一种信任梯度估计器,该估计器显式地最小化量化状态下计算的噪声梯度与“真实”(但未知)全精度梯度之间的误差。
技术框架:QuEST的整体框架可以概括为以下几个步骤:1. 使用Hadamard归一化和MSE最优拟合对权重和激活进行量化。2. 使用量化后的权重和激活计算梯度。3. 使用信任梯度估计器估计“真实”梯度。4. 使用估计的梯度更新模型参数。
关键创新:QuEST的关键创新在于两个方面:一是精确的量化方法,通过Hadamard归一化和MSE最优拟合,更好地保留了权重和激活的分布信息,从而减小了量化误差。二是信任梯度估计器,它显式地最小化了量化梯度与全精度梯度之间的误差,从而提高了梯度估计的准确性。与现有方法相比,QuEST更关注量化误差对梯度估计的影响,并提出了针对性的解决方案。
关键设计:QuEST的关键设计包括:1. Hadamard归一化:用于规范化权重和激活的分布,使其更适合量化。2. MSE最优拟合:用于找到最佳的量化级别,以最小化量化误差。3. 信任梯度估计器:通过最小化量化梯度与全精度梯度之间的误差来估计“真实”梯度。具体的损失函数设计和参数设置在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
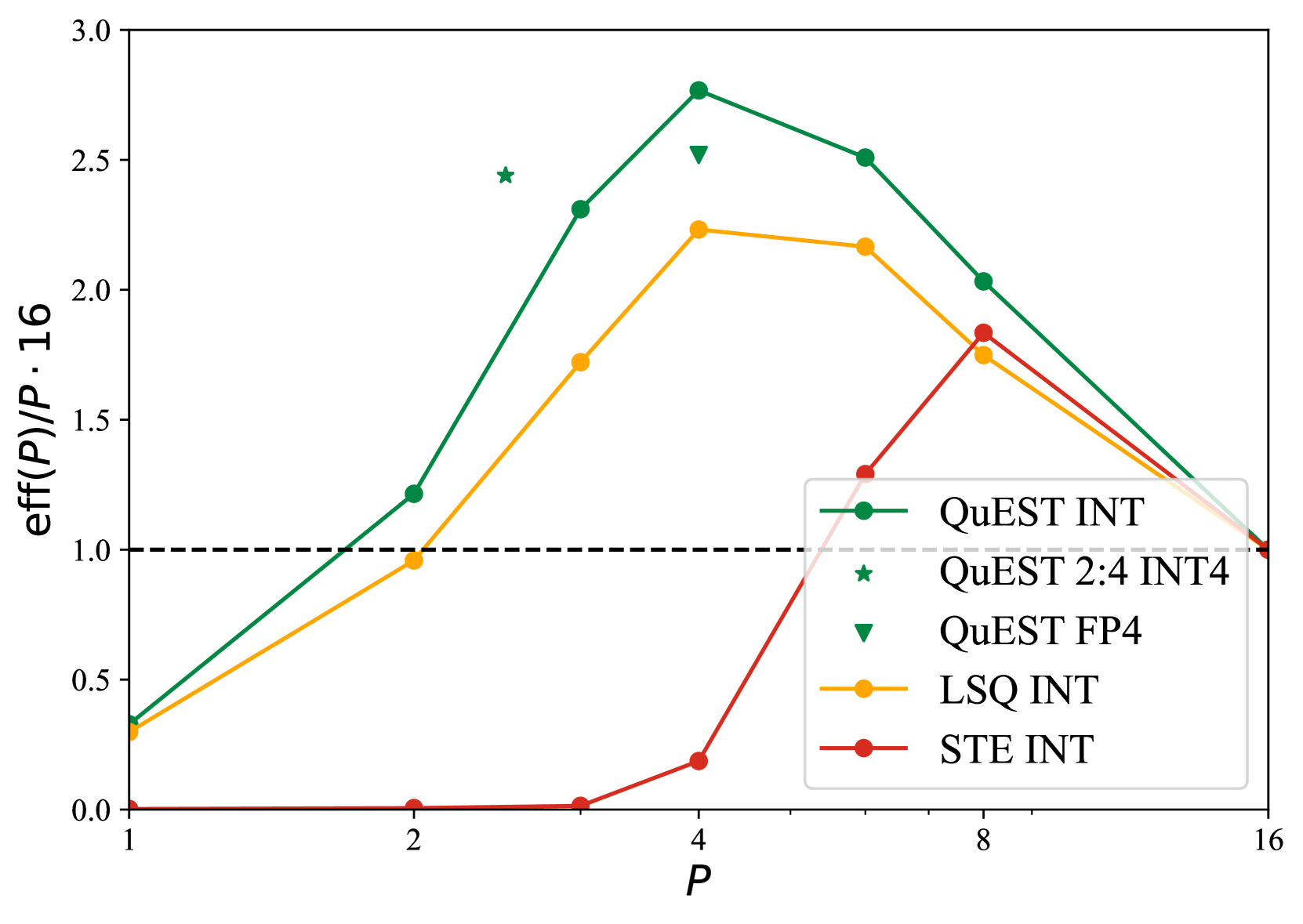
实验结果表明,QuEST在Llama架构上实现了稳定的缩放规律,并且在低至1比特权重和激活的情况下也能实现收敛。此外,QuEST还支持稀疏表示,进一步降低了模型的计算和存储成本。论文提供了GPU内核支持,表明QuEST产生的模型可以高效执行。这些结果表明QuEST是一种有效的低比特LLM训练方法。
🎯 应用场景
QuEST的潜在应用领域包括资源受限设备上的LLM部署、边缘计算、移动设备AI加速等。通过降低LLM的计算和存储成本,QuEST使得在算力有限的设备上运行大型模型成为可能,从而推动AI在更广泛场景下的应用。未来,QuEST可以进一步扩展到其他类型的模型和任务,并与其他压缩技术相结合,以实现更高的压缩率和性能。
📄 摘要(原文)
One approach to reducing the massive costs of large language models (LLMs) is the use of quantized or sparse representations for training or deployment. While post-training compression methods are very popular, the question of obtaining even more accurate compressed models by directly training over such representations, i.e., Quantization-Aware Training (QAT), is still open: for example, a recent study (arXiv:2411.04330) put the "optimal" bit-width at which models can be trained using QAT, while staying accuracy-competitive with standard FP16/BF16 precision, at 8-bits weights and activations. We advance this state-of-the-art via a new method called QuEST, for which we demonstrate optimality at 4-bits and stable convergence as low as 1-bit weights and activations. QuEST achieves this by improving two key aspects of QAT methods: (1) accurate and fast quantization of the (continuous) distributions of weights and activations via Hadamard normalization and MSE-optimal fitting; (2) a new trust gradient estimator based on the idea of explicitly minimizing the error between the noisy gradient computed over quantized states and the "true" (but unknown) full-precision gradient. Experiments on Llama-type architectures show that QuEST induces stable scaling laws across the entire range of hardware-supported precisions, and can be extended to sparse representations. We provide GPU kernel support showing that models produced by QuEST can be executed efficiently. Our code is available at https://github.com/IST-DASLab/QuEST.