CAST: Cross Attention based multimodal fusion of Structure and Text for materials property prediction
作者: Jaewan Lee, Changyoung Park, Hongjun Yang, Sungbin Lim, Woohyung Lim, Sehui Han
分类: cs.LG, cond-mat.mtrl-sci, cs.AI
发布日期: 2025-02-06 (更新: 2025-08-08)
备注: 11 pages, 4 figures
💡 一句话要点
提出CAST:一种基于交叉注意力的结构-文本多模态融合模型,用于材料属性预测。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 材料属性预测 多模态融合 图神经网络 交叉注意力 预训练
📋 核心要点
- 图神经网络(GNNs)在材料属性预测中表现出色,但难以捕捉晶体系统等全局结构特征。
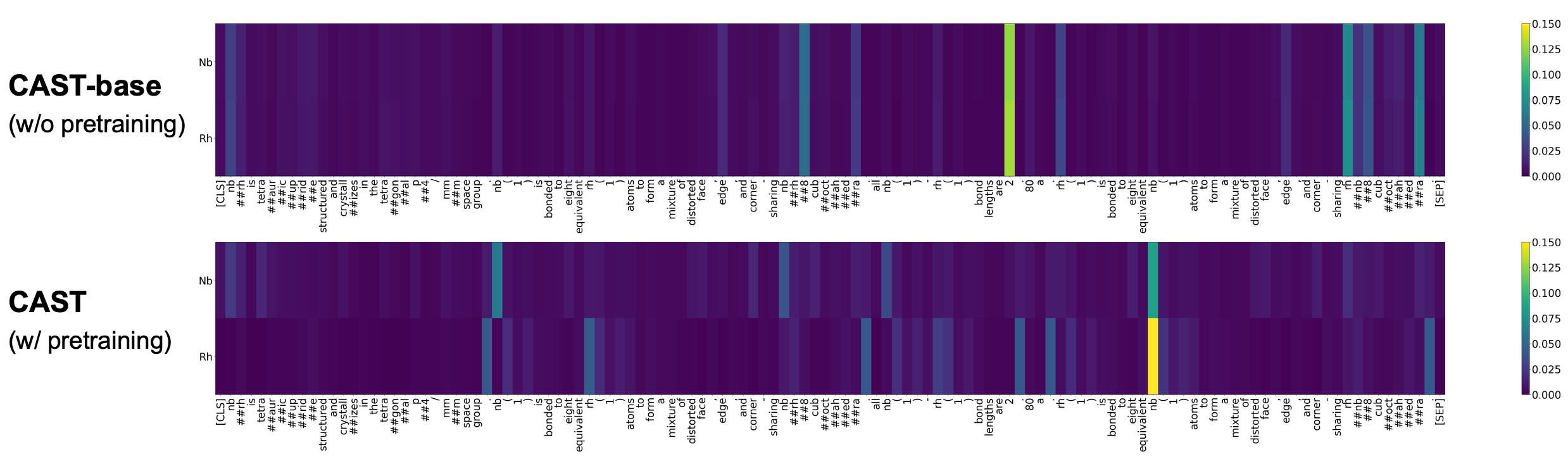
- CAST模型通过交叉注意力融合图节点级和文本token级特征,并引入掩码节点预测预训练,增强多模态对齐。
- 实验表明,CAST在材料属性预测上显著优于现有模型,相对MAE平均提升10.2%至35.7%。
📝 摘要(中文)
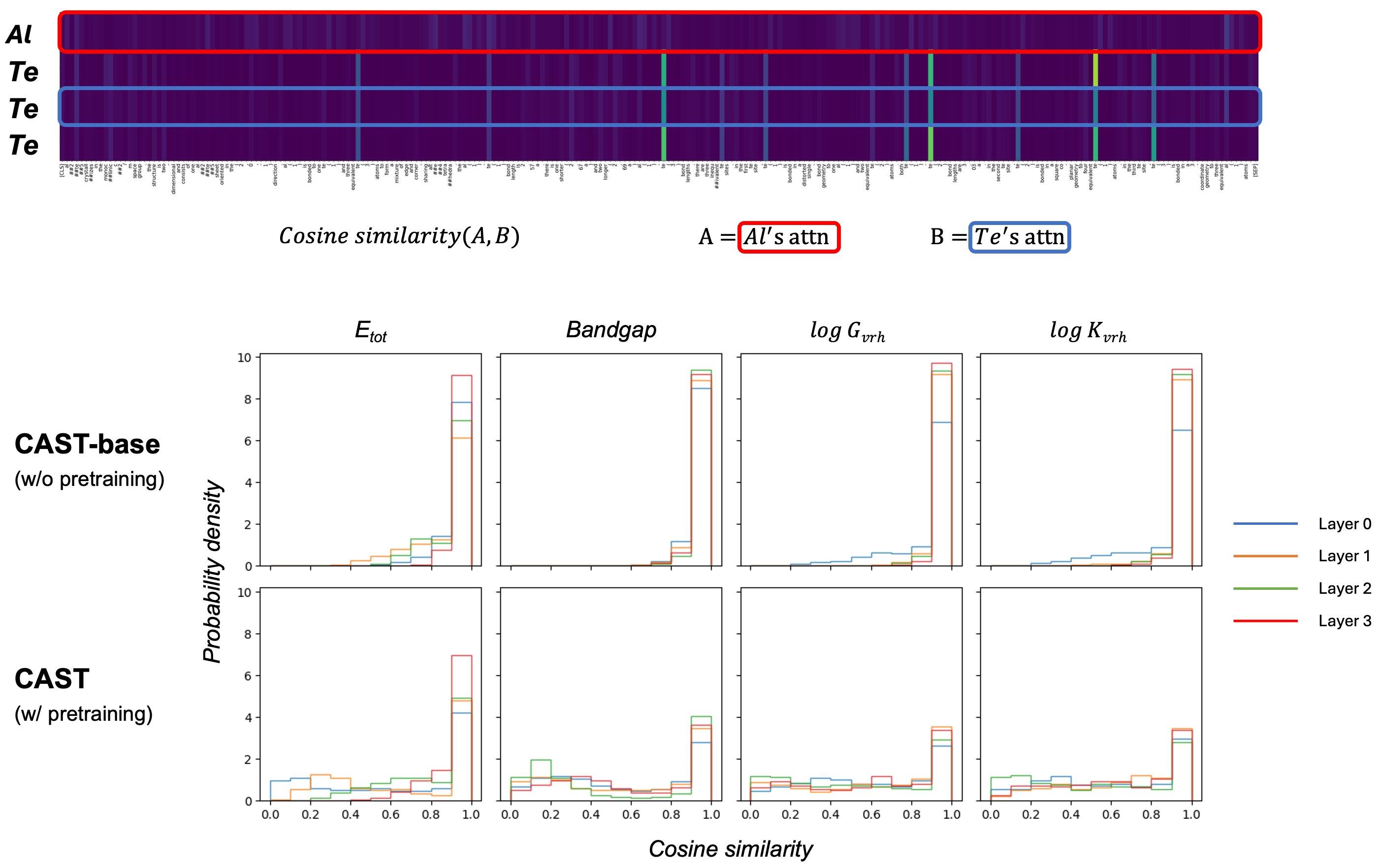
本文提出了一种基于交叉注意力的多模态模型CAST,用于预测材料属性,该模型集成了图表示和材料的文本描述,有效地保留了关键的结构和成分信息。与依赖聚合材料级嵌入的CrysMMNet和MultiMat等先前方法不同,CAST利用交叉注意力机制来组合细粒度的图节点级和文本token级特征。此外,还引入了一种掩码节点预测预训练策略,以进一步增强节点和文本嵌入之间的对齐。实验结果表明,CAST在四个关键材料属性(形成能、带隙、体积模量和剪切模量)上优于现有的基线模型,平均相对MAE改进范围为10.2%到35.7%。对注意力图的分析证实了预训练在有效对齐多模态表示方面的重要性。这项研究强调了多模态学习框架在开发更准确和全局感知的材料预测模型方面的潜力。
🔬 方法详解
问题定义:现有基于图神经网络的材料属性预测方法,虽然在捕捉局部结构信息方面表现良好,但通常难以有效捕捉全局结构特征,例如晶体系统类型等,这限制了预测性能。此外,如何有效融合材料的结构信息和文本描述信息也是一个挑战。
核心思路:本文的核心思路是利用交叉注意力机制,将材料的图结构表示和文本描述信息进行有效融合。通过在图节点级别和文本token级别进行细粒度的特征交互,模型能够更好地理解材料的全局结构和成分信息,从而提高属性预测的准确性。
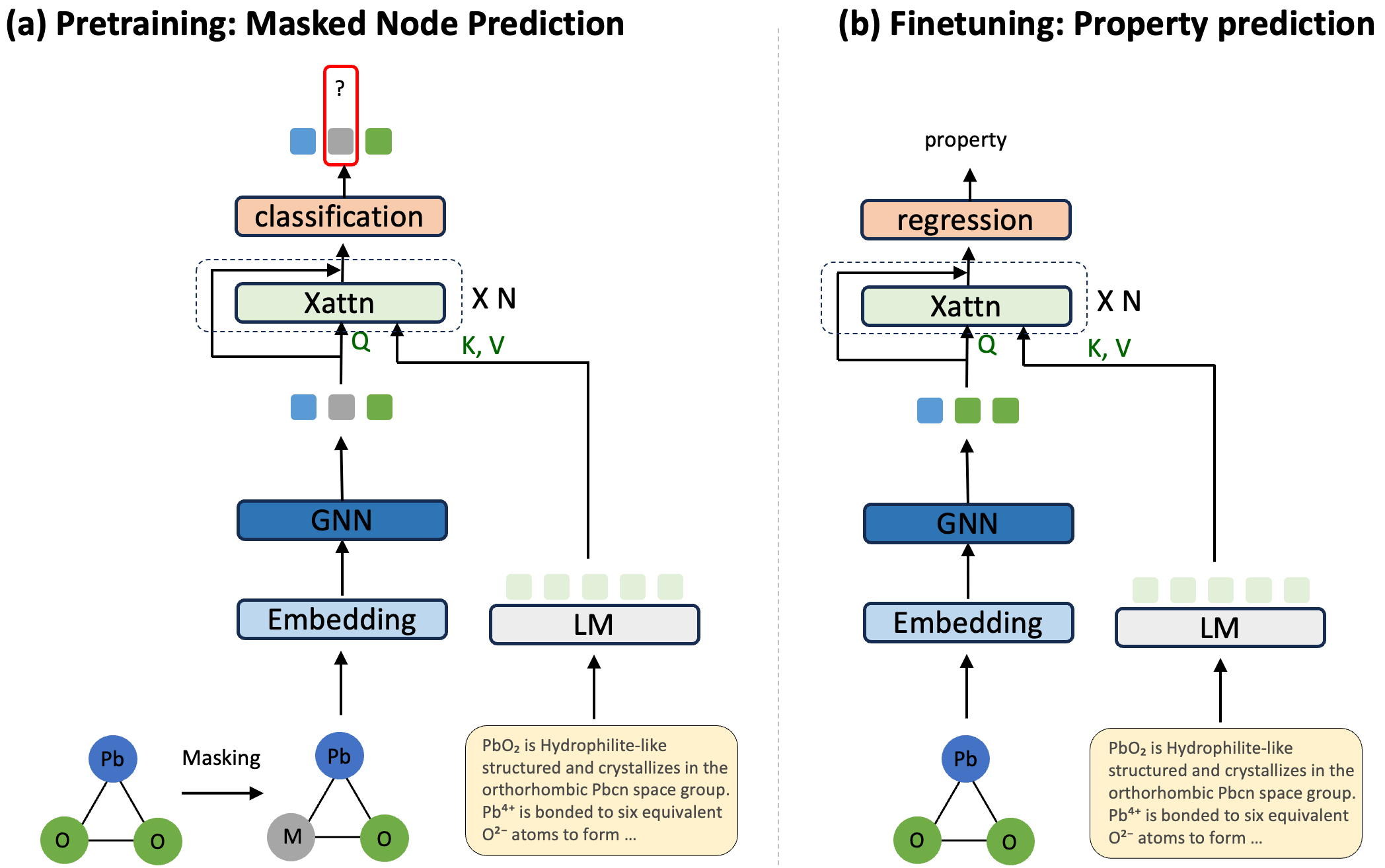
技术框架:CAST模型主要包含以下几个模块:1) 图神经网络模块,用于提取材料晶体结构的节点特征;2) 文本编码模块,用于提取材料文本描述的token特征;3) 交叉注意力模块,用于融合图节点特征和文本token特征;4) 预测模块,基于融合后的特征进行材料属性预测。此外,模型还采用了掩码节点预测的预训练策略,以增强节点和文本嵌入之间的对齐。
关键创新:CAST的关键创新在于使用交叉注意力机制进行细粒度的图节点和文本token特征融合,而非像CrysMMNet和MultiMat等方法那样,仅仅依赖于聚合的材料级别嵌入。这种细粒度的融合方式能够更好地捕捉材料的结构和成分信息,从而提高预测性能。此外,掩码节点预测预训练策略也进一步增强了多模态表示的对齐。
关键设计:在交叉注意力模块中,使用了多头注意力机制,以捕捉不同角度的特征交互信息。掩码节点预测预训练的目标是预测被掩盖的节点类型,损失函数采用交叉熵损失。图神经网络模块和文本编码模块的具体网络结构未知,但可以根据具体任务选择合适的模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CAST模型在四个关键材料属性(形成能、带隙、体积模量和剪切模量)的预测上,均优于现有的基线模型。具体而言,CAST在这些属性上的平均相对MAE改进范围为10.2%到35.7%,表明其在材料属性预测方面具有显著的优势。
🎯 应用场景
该研究成果可应用于新材料的发现与设计,加速材料研发进程。通过准确预测材料的各项属性,研究人员可以快速筛选出具有特定性能的候选材料,减少实验试错成本,推动能源、化工、电子等领域的材料创新。
📄 摘要(原文)
Recent advancements in graph neural networks (GNNs) have significantly enhanced the prediction of material properties by modeling crystal structures as graphs. However, GNNs often struggle to capture global structural characteristics, such as crystal systems, limiting their predictive performance. To overcome this issue, we propose CAST, a cross-attention-based multimodal model that integrates graph representations with textual descriptions of materials, effectively preserving critical structural and compositional information. Unlike previous approaches, such as CrysMMNet and MultiMat, which rely on aggregated material-level embeddings, CAST leverages cross-attention mechanisms to combine fine-grained graph node-level and text token-level features. Additionally, we introduce a masked node prediction pretraining strategy that further enhances the alignment between node and text embeddings. Our experimental results demonstrate that CAST outperforms existing baseline models across four key material properties-formation energy, band gap, bulk modulus, and shear modulus-with average relative MAE improvements ranging from 10.2% to 35.7%. Analysis of attention maps confirms the importance of pretraining in effectively aligning multimodal representations. This study underscores the potential of multimodal learning frameworks for developing more accurate and globally informed predictive models in materials science.