Speeding up Speculative Decoding via Sequential Approximate Verification
作者: Meiyu Zhong, Noel Teku, Ravi Tandon
分类: cs.LG, cs.IT
发布日期: 2025-02-06 (更新: 2025-07-08)
备注: ICML 2025, Workshop on Efficient Systems for Foundation Models
💡 一句话要点
提出SPRINTER,通过序列近似验证加速推测解码,降低大语言模型推理延迟。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推测解码 大语言模型 模型加速 近似验证 序列推理
📋 核心要点
- 推测解码依赖目标LLM的并行验证,成为降低延迟的瓶颈。
- SPRINTER使用低复杂度验证器预测token是否被目标LLM接受,减少目标LLM调用。
- 实验表明,SPRINTER在保持生成质量的同时,进一步降低了延迟。
📝 摘要(中文)
推测解码(SD)是一种利用大型语言模型(LLM)进行快速推理的新技术。SD使用较小的draft LLM自回归地生成token序列,并使用较大的target LLM进行并行验证,以确保统计一致性。然而,对target LLM的周期性并行调用阻碍了SD实现更低的延迟。我们提出了SPRINTER,它利用一个低复杂度的验证器,该验证器经过训练,可以预测draft LLM生成的token是否会被target LLM接受。通过执行序列近似验证,SPRINTER不需要target LLM进行验证,只有在token被认为不可接受时才会被调用。这减少了对较大LLM的调用次数,从而进一步加速并降低计算成本。我们对SPRINTER进行了理论分析,研究了生成token的统计特性,以及预期延迟降低与验证器的函数关系。我们在多个数据集和模型对上评估了SPRINTER,证明了近似验证仍然可以保持高质量的生成,同时进一步降低延迟。
🔬 方法详解
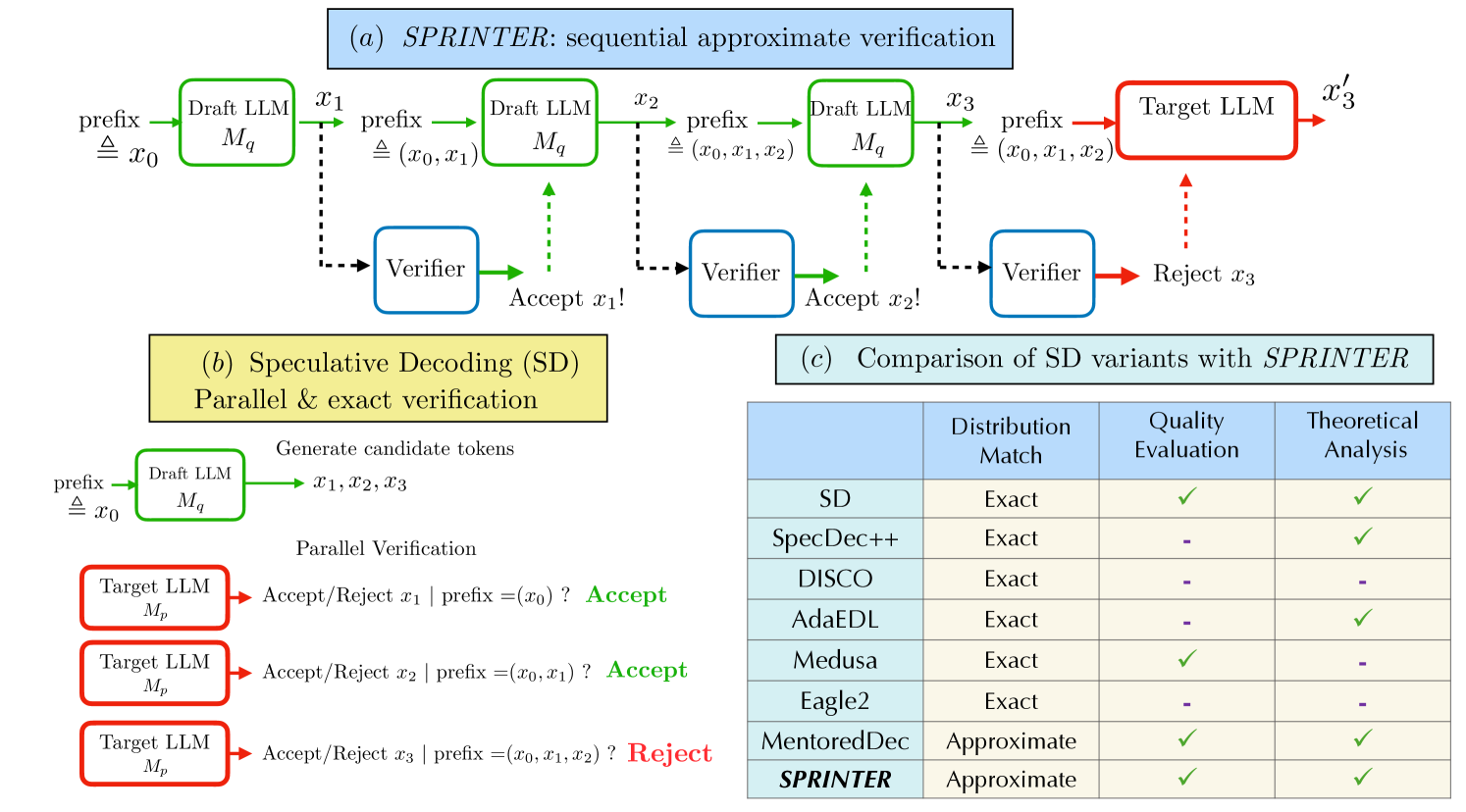
问题定义:推测解码(Speculative Decoding, SD)旨在加速大型语言模型(LLM)的推理过程。现有的SD方法依赖于目标LLM对draft LLM生成的token序列进行并行验证,这种频繁的并行调用成为了性能瓶颈,限制了延迟的进一步降低。现有方法的痛点在于验证过程的计算开销大,且无法充分利用draft LLM的生成能力。
核心思路:SPRINTER的核心思路是引入一个低复杂度的验证器,该验证器能够近似预测draft LLM生成的token是否会被目标LLM接受。通过这种方式,SPRINTER可以在很大程度上避免对目标LLM的频繁调用,从而降低计算开销并加速推理过程。这样设计的目的是利用轻量级模型快速过滤掉明显不符合目标LLM分布的token,从而减少昂贵的验证操作。
技术框架:SPRINTER的整体框架包括三个主要组成部分:draft LLM、verifier和target LLM。首先,draft LLM自回归地生成token序列。然后,verifier对每个token进行序列近似验证,判断其是否会被target LLM接受。只有当verifier认为token不可接受时,才会调用target LLM进行最终验证。如果verifier认为token可接受,则直接将其添加到生成序列中。
关键创新:SPRINTER的关键创新在于引入了序列近似验证的概念,并使用一个低复杂度的验证器来执行该验证。与传统的SD方法相比,SPRINTER避免了对目标LLM的频繁并行调用,从而显著降低了计算开销。此外,SPRINTER的验证器是经过专门训练的,能够更好地适应目标LLM的分布,从而提高验证的准确性。
关键设计:验证器通常是一个小型神经网络,例如一个简单的分类器或回归模型。训练验证器的关键在于构建合适的训练数据集,该数据集包含draft LLM生成的token序列以及目标LLM对这些token的接受/拒绝标签。损失函数可以选择交叉熵损失或均方误差损失,具体取决于验证器的输出类型。此外,还可以通过调整验证器的置信度阈值来控制验证的严格程度,从而在生成质量和推理速度之间进行权衡。
🖼️ 关键图片


📊 实验亮点
SPRINTER在多个数据集和模型对上进行了评估,实验结果表明,SPRINTER能够在保持高质量生成的同时,显著降低推理延迟。具体性能提升数据未知,但论文强调SPRINTER优于传统推测解码方法,实现了进一步的加速和计算成本降低。
🎯 应用场景
SPRINTER可广泛应用于需要快速LLM推理的场景,如实时对话系统、机器翻译、文本摘要等。通过降低推理延迟和计算成本,SPRINTER能够提升用户体验,并降低部署LLM的经济成本。未来,SPRINTER有望成为加速LLM应用普及的关键技术。
📄 摘要(原文)
Speculative Decoding (SD) is a recently proposed technique for faster inference using Large Language Models (LLMs). SD operates by using a smaller draft LLM for autoregressively generating a sequence of tokens and a larger target LLM for parallel verification to ensure statistical consistency. However, periodic parallel calls to the target LLM for verification prevent SD from achieving even lower latencies. We propose SPRINTER, which utilizes a low-complexity verifier trained to predict if tokens generated from a draft LLM would be accepted by the target LLM. By performing sequential approximate verification, SPRINTER does not require verification by the target LLM and is only invoked when a token is deemed unacceptable. This reduces the number of calls to the larger LLM, achieving further speedups and lower computation cost. We present a theoretical analysis of SPRINTER, examining the statistical properties of the generated tokens, as well as the expected reduction in latency as a function of the verifier. We evaluate SPRINTER on several datasets and model pairs, demonstrating that approximate verification can still maintain high quality generation while further reducing latency.