Revisiting Intermediate-Layer Matching in Knowledge Distillation: Layer-Selection Strategy Doesn't Matter (Much)
作者: Zony Yu, Yuqiao Wen, Lili Mou
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-02-06 (更新: 2025-12-10)
备注: Accepted at IJCNLP-AACL 2025
💡 一句话要点
知识蒸馏中层匹配策略不敏感性研究:层选择策略影响甚微
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 模型压缩 层选择策略 中间层匹配 特征表示
📋 核心要点
- 知识蒸馏中,中间层匹配的层选择策略多样,但其有效性缺乏深入分析,存在冗余设计。
- 该研究发现,层选择策略对学生模型性能影响甚微,即使是反向匹配也能取得良好效果。
- 通过分析教师层在学生视角下的角度,解释了层选择策略不敏感的原因,简化了KD系统设计。
📝 摘要(中文)
知识蒸馏(KD)是一种将知识从大型“教师”模型迁移到小型“学生”模型的常用方法。以往的研究探索了各种层选择策略(例如,前向匹配和顺序随机匹配),用于KD中的中间层匹配,其中强制学生层模仿特定的教师层。本文重新审视了这些层选择策略,并观察到一个有趣的现象:层选择策略在中间层匹配中并不重要——即使是看似荒谬的匹配策略(如反向匹配)仍然能产生出人意料的良好学生性能。我们通过检查从学生角度观察到的教师层之间的角度来解释这种现象。我们的工作揭示了KD实践,因为层选择策略可能不是KD系统设计的重点,并且在大多数设置中,简单的正向匹配效果良好。
🔬 方法详解
问题定义:知识蒸馏旨在将大型教师模型的知识迁移到小型学生模型,中间层匹配是常用的技术。现有方法通常关注如何选择合适的教师层与学生层进行匹配,提出了各种层选择策略,但这些策略的有效性和必要性尚不明确。现有方法的痛点在于,可能过度关注了层选择策略的设计,而忽略了其他更重要的因素。
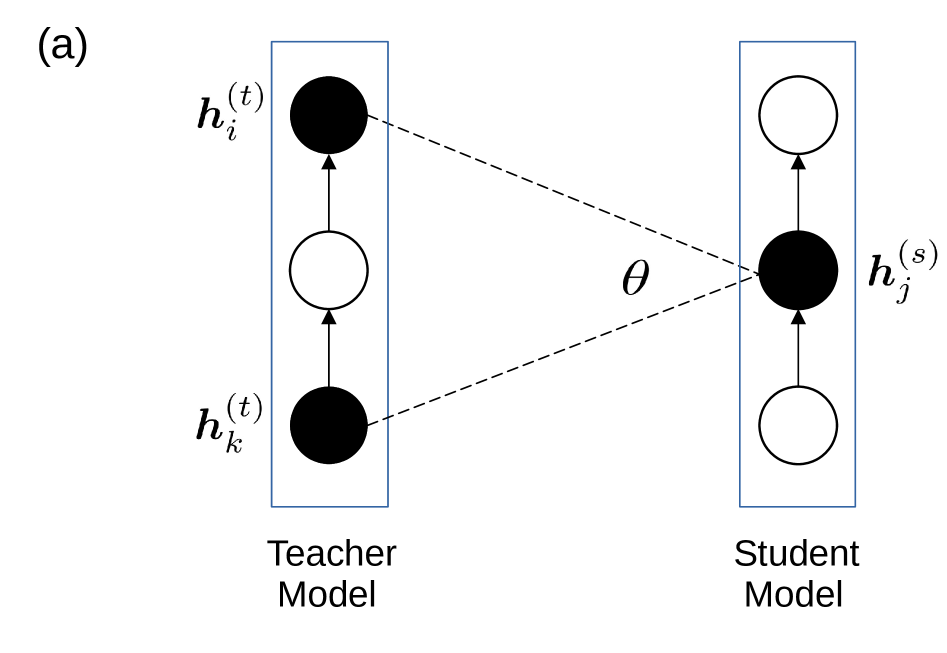
核心思路:论文的核心思路是重新审视知识蒸馏中中间层匹配的层选择策略,通过实验发现不同的层选择策略(包括看似不合理的策略)对学生模型的性能影响不大。这表明层选择策略可能不是知识蒸馏的关键因素。论文进一步分析了教师层在学生视角下的特征表示,发现教师层之间的角度关系可能解释了这种不敏感性。
技术框架:该研究主要通过实验来验证不同的层选择策略对学生模型性能的影响。实验流程包括:1) 选择教师模型和学生模型;2) 定义不同的层选择策略,例如前向匹配、反向匹配、随机匹配等;3) 使用不同的层选择策略进行知识蒸馏训练;4) 评估学生模型的性能。此外,论文还分析了教师层在学生视角下的特征表示,计算教师层之间的角度,以解释实验结果。
关键创新:该研究最重要的技术创新点在于发现了知识蒸馏中层选择策略的不敏感性。以往的研究通常认为选择合适的教师层与学生层进行匹配是重要的,而该研究表明,即使使用看似不合理的层选择策略,也能取得良好的学生模型性能。这挑战了以往的认知,并为知识蒸馏的研究提供了新的视角。
关键设计:论文的关键设计在于实验设置,包括选择合适的教师模型和学生模型、定义具有代表性的层选择策略、以及使用合适的损失函数进行知识蒸馏训练。此外,论文还设计了分析教师层特征表示的方法,通过计算教师层之间的角度来解释实验结果。具体的参数设置和网络结构信息未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,即使使用反向匹配等看似不合理的层选择策略,学生模型的性能也能接近甚至超过使用传统前向匹配策略的性能。这表明层选择策略在知识蒸馏中可能不是关键因素,简化层选择策略可以有效降低计算成本,同时保持模型性能。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于各种需要模型压缩和加速的场景,例如移动设备上的图像识别、自然语言处理等。通过简化知识蒸馏的层选择策略,可以降低算法复杂度和计算成本,提高模型部署效率。未来的研究可以进一步探索其他影响知识蒸馏效果的因素,例如损失函数的设计、数据增强方法等。
📄 摘要(原文)
Knowledge distillation (KD) is a popular method of transferring knowledge from a large "teacher" model to a small "student" model. Previous work has explored various layer-selection strategies (e.g., forward matching and in-order random matching) for intermediate-layer matching in KD, where a student layer is forced to resemble a certain teacher layer. In this work, we revisit such layer-selection strategies and observe an intriguing phenomenon that layer-selection strategy does not matter (much) in intermediate-layer matching -- even seemingly nonsensical matching strategies such as reverse matching still result in surprisingly good student performance. We provide an interpretation for this phenomenon by examining the angles between teacher layers viewed from the student's perspective. Our work sheds light on KD practice, as layer-selection strategies may not be the main focus of KD system design, and vanilla forward matching works well in most setups.