An Empirical Analysis of Machine Learning Model and Dataset Documentation, Supply Chain, and Licensing Challenges on Hugging Face
作者: Trevor Stalnaker, Nathan Wintersgill, Oscar Chaparro, Laura A. Heymann, Massimiliano Di Penta, Daniel M German, Denys Poshyvanyk
分类: cs.SE, cs.LG
发布日期: 2025-02-06 (更新: 2025-09-29)
💡 一句话要点
分析Hugging Face平台模型与数据集的文档、供应链和许可挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器学习模型 数据集 Hugging Face 供应链分析 许可管理
📋 核心要点
- 机器学习模型在软件系统中被广泛应用,但其供应链关系缺乏了解,可能影响合规性和安全性。
- 通过分析Hugging Face平台上的大量模型和数据集,评估文档质量、供应链结构和许可情况。
- 研究揭示了文档不足、许可管理问题和供应链复杂性,为改进ML模型共享和管理提供了依据。
📝 摘要(中文)
本文对Hugging Face平台上760,460个模型和175,000个数据集进行了广泛分析,旨在评估机器学习(ML)组件在软件系统中的应用现状,并深入了解其供应链关系。研究首先评估了Hugging Face供应链中现有文档的质量,指出了实际案例中的不足,并提出了改进建议。其次,分析了现有供应链的底层结构。最后,探讨了当前的许可情况,并讨论了该领域面临的独特挑战。研究结果表明,需要加强ML模型/数据集的许可管理,改进模型文档支持,并实现自动化的不一致性检查和验证。研究团队公开了研究基础设施和数据集,以促进未来的研究。
🔬 方法详解
问题定义:论文旨在解决机器学习模型和数据集在共享平台(如Hugging Face)上存在的文档不完善、供应链不透明以及许可管理混乱的问题。现有方法缺乏对这些问题的系统性分析,导致用户难以充分理解和安全使用这些资源,同时也增加了合规性风险。
核心思路:论文的核心思路是通过大规模实证分析,深入挖掘Hugging Face平台上的模型和数据集,揭示其文档质量、供应链结构和许可情况的现状,从而识别问题并提出改进建议。这种方法侧重于从实际数据中发现问题,而非依赖理论推导或小规模实验。
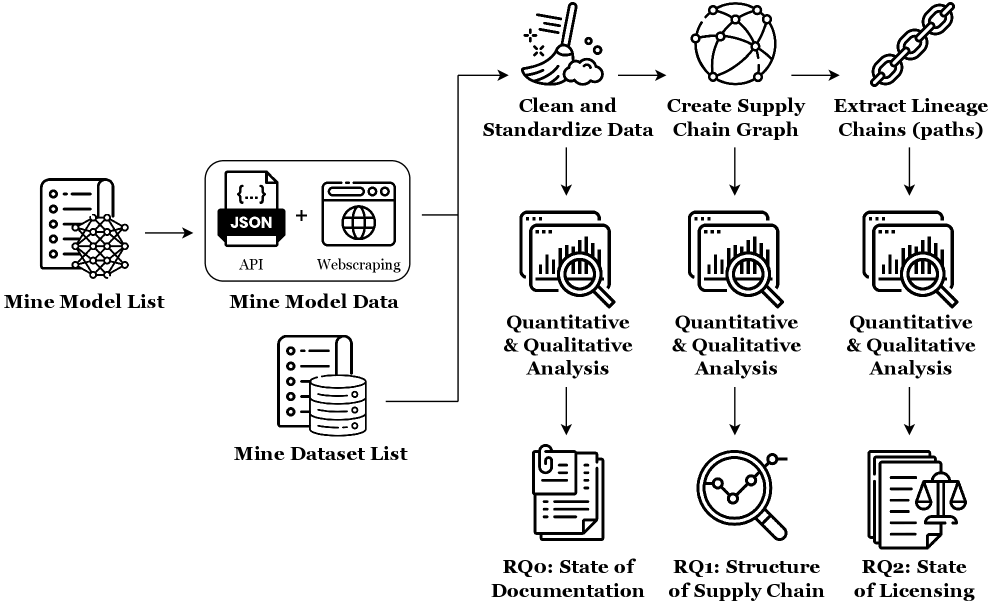
技术框架:论文的技术框架主要包括以下几个阶段:1) 数据收集:从Hugging Face平台抓取大量模型和数据集的元数据和相关文档。2) 文档分析:评估文档的完整性、准确性和可理解性,识别文档缺失或不清晰的情况。3) 供应链分析:分析模型和数据集之间的依赖关系,构建供应链图谱,识别潜在的风险点。4) 许可分析:分析模型和数据集的许可协议,识别许可冲突或不明确的情况。
关键创新:论文的关键创新在于其对机器学习模型和数据集的供应链进行了系统性的实证分析,揭示了现有共享平台在文档、供应链和许可管理方面存在的诸多问题。此前,针对这些问题的研究较少,且多集中于理论探讨或小规模案例分析。
关键设计:论文的关键设计包括:1) 使用自动化工具进行大规模数据抓取和分析。2) 设计合理的指标来评估文档质量、供应链复杂性和许可合规性。3) 采用人工审核的方式验证自动化分析的结果,确保结论的准确性。
🖼️ 关键图片

📊 实验亮点
研究分析了Hugging Face平台上的760,460个模型和175,000个数据集,揭示了大量模型缺乏充分的文档,许可信息不明确,以及供应链关系复杂等问题。这些发现为改进ML模型的共享和管理提供了重要的依据,并为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于改进机器学习模型的共享和管理平台,提升模型的可理解性、可追溯性和安全性。同时,可以帮助开发者更好地理解和使用开源模型,降低合规性风险。未来,该研究可以扩展到其他模型共享平台,并为制定更完善的机器学习模型许可协议提供参考。
📄 摘要(原文)
The last decade has seen widespread adoption of Machine Learning (ML) components in software systems. This has occurred in nearly every domain, from natural language processing to computer vision. These ML components range from relatively simple neural networks to complex and resource-intensive large language models. However, despite this widespread adoption, little is known about the supply chain relationships that produce these models, which can have implications for compliance and security. In this work, we conducted an extensive analysis of 760,460 models and 175,000 datasets extracted from the popular model-sharing site Hugging Face. First, we evaluate the current state of documentation in the Hugging Face supply chain, report real-world examples of shortcomings, and offer actionable suggestions for improvement. Next, we analyze the underlying structure of the existing supply chain. Finally, we explore the current licensing landscape against what was reported in previous work and discuss the unique challenges posed in this domain. Our results motivate multiple research avenues, including the need for better license management for ML models/datasets, better support for model documentation, and automated inconsistency checking and validation. We make our research infrastructure and dataset available to facilitate future research.